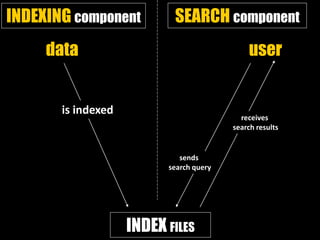
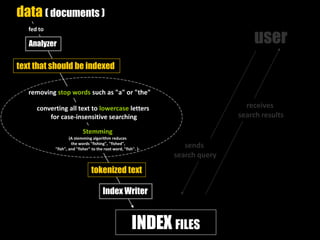
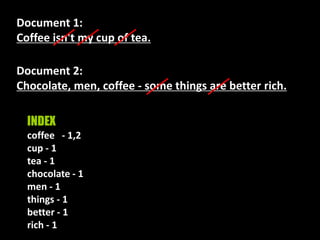
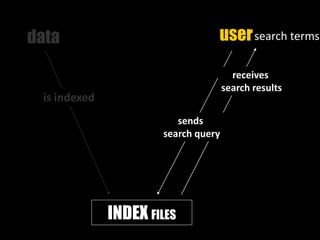
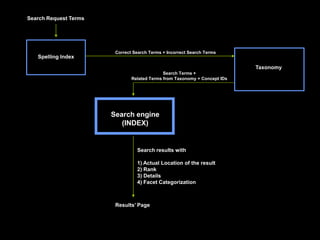
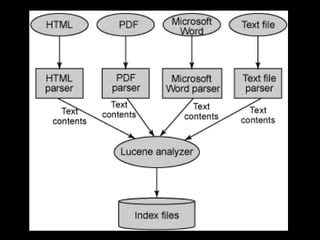
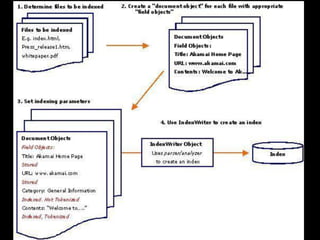
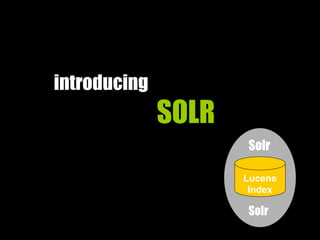
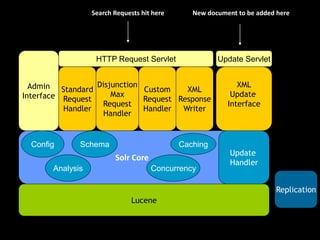
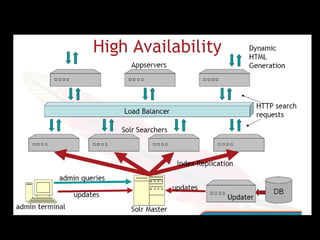
This document provides an introduction to enterprise search and its key components. It discusses how search engines work by building indexes on text and answering queries using those indexes. The two main components are indexing, which structures data for easy searching, and search, which returns results based on user queries against the index. It introduces common file formats that can be indexed like text, HTML, PDFs. Lucene and Solr are introduced as open source search libraries, with Solr building on Lucene and adding features like indexing, querying via HTTP, and admin interfaces. The document demonstrates adding, deleting, and searching for documents in Solr.




























































![Trabajo de imformatica_de_sara[1]](https://cdn.slidesharecdn.com/ss_thumbnails/trabajodeimformaticadesara1-110221183944-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








































