Download to read offline





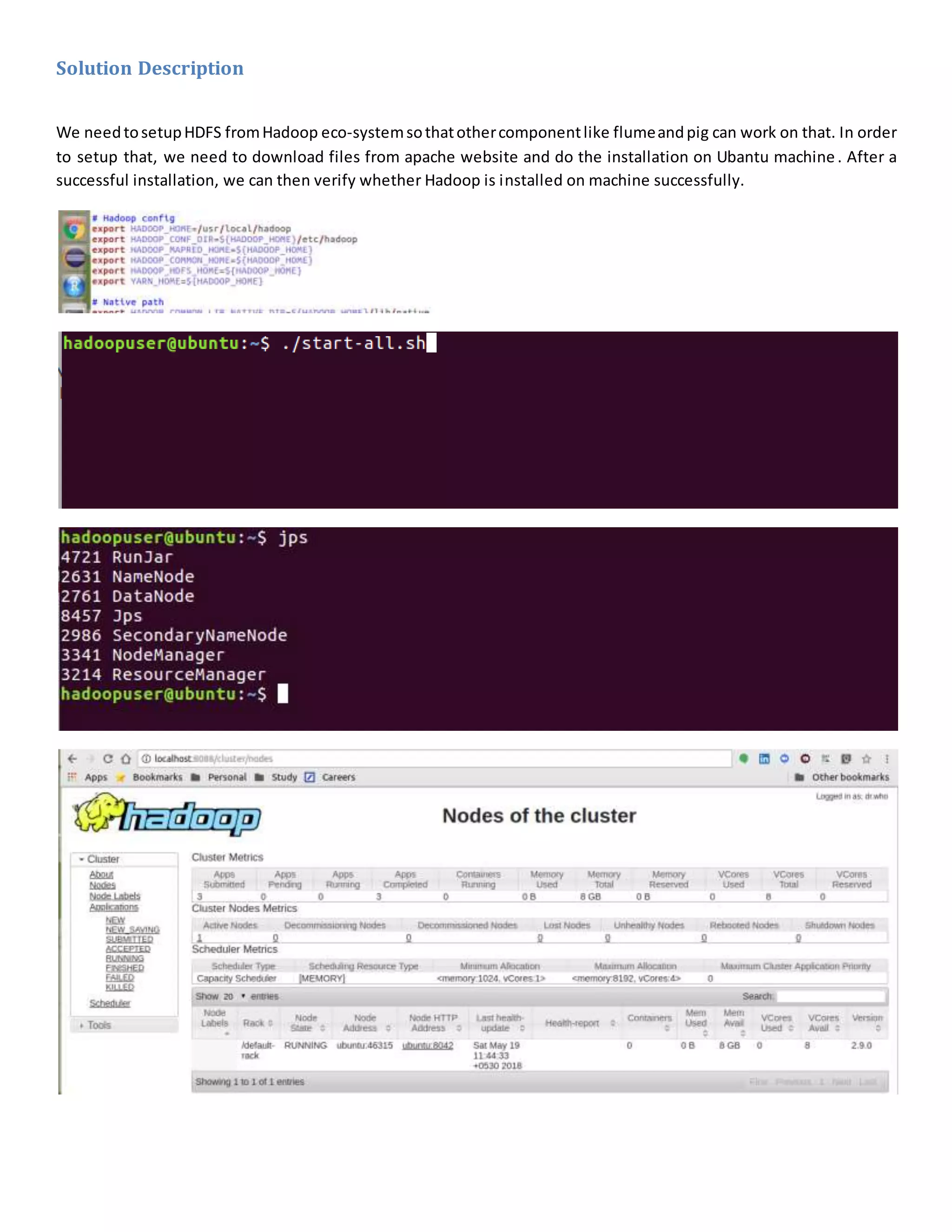

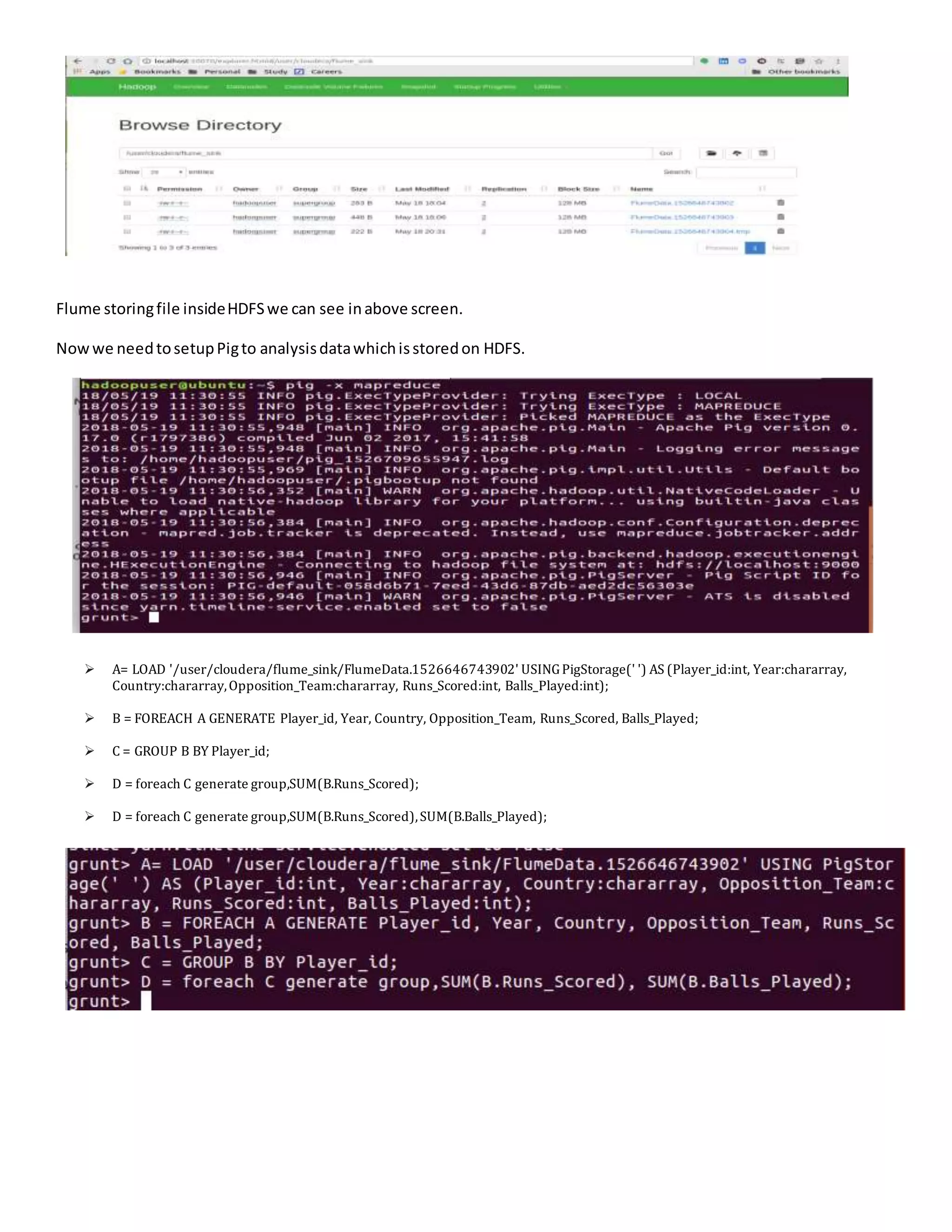
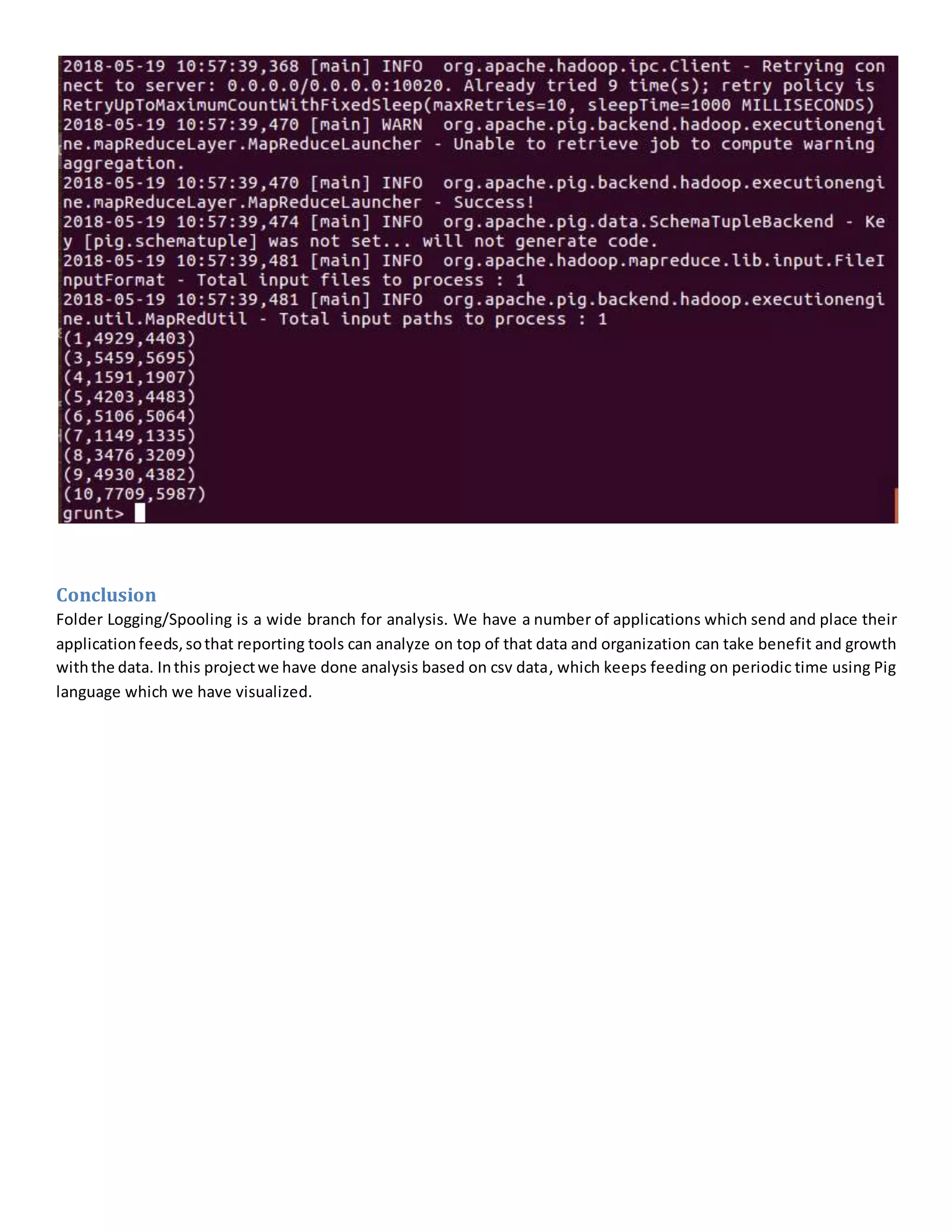

The document details a project analyzing runs scored by players using Apache Flume and Pig, outlining the problem statement of collecting data from multiple countries over the years. It describes the solution architecture involving Flume for data ingestion and Pig for data processing, including specific software tools and configuration setups. The conclusion emphasizes the importance of logging and spooling for data analysis, highlighting the project's ability to provide insights through continuous CSV data feeds.



































































