Download to read offline








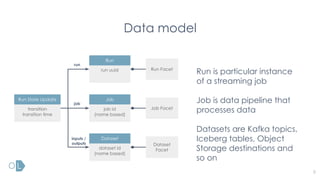


































The document presents an overview of Openlineage's integration with Flink for stream processing, discussing its mission to establish an open standard for lineage metadata collection. It highlights the challenges and complexities related to lineage in streaming jobs compared to batch jobs, as well as the newly introduced features from FLIP-314 aimed at improving the architecture and functionality of lineage tracking within Flink. Additionally, it emphasizes community involvement and future directions for supporting more streaming systems and enhancing lineage capabilities.






![[FFE19] Build a Flink AI Ecosystem](https://cdn.slidesharecdn.com/ss_thumbnails/ffe19flinkaiecosystem-191010100923-thumbnail.jpg?width=640&height=640&fit=bounds)

























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


