









![Client:
1. Dataframe rows to Flink tuples
2. Determine return types of UDFs
3. Create execution plan
15
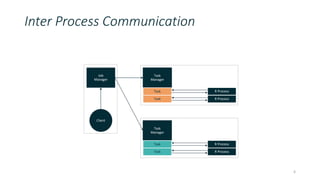
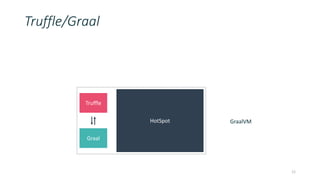
Job
Manager
Client
Task
Manager
map
map
Task
Manager
map
map
flink.init(SERVER, PORT)
flink.parallelism(DOP)
df <- flink.readdf(SOURCE,
list("id", “body“, …),
list(character, character, …)
)
df$wordcount <- length(strsplit(df$body, " ")[[1]])
flink.writeAsText(df, SINK)
flink.execute()](https://image.slidesharecdn.com/20170913flinkforward-170914134046/85/Flink-Forward-Berlin-2017-Andreas-Kunft-Efficiently-executing-R-Dataframes-on-Flink-16-320.jpg)
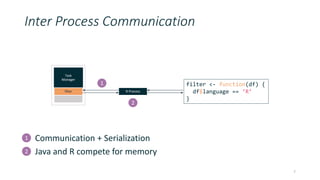
![function(tuple) {
.fun <- function(tuple) { length(strsplit(tuple[[2]], " ")[[1]] }
flink.tuple(tuple[[1]], tuple[[2]], .fun(tuple))
}
Dataframe proxy keeps track of columns, provides efficient access
Can be extended with new columns
Rewrite to directly use Flink tuples
16
df$wordcount <- length(strsplit(df$body, " ")[[1]])
1
23
1
2
3](https://image.slidesharecdn.com/20170913flinkforward-170914134046/85/Flink-Forward-Berlin-2017-Andreas-Kunft-Efficiently-executing-R-Dataframes-on-Flink-17-320.jpg)
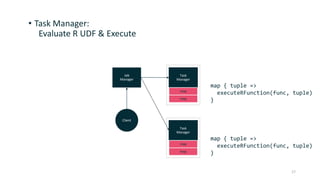
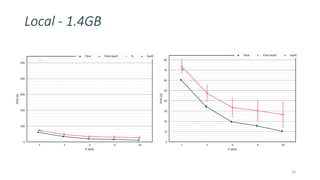
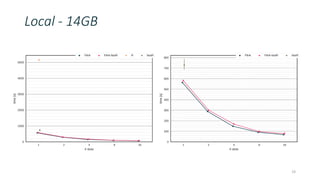
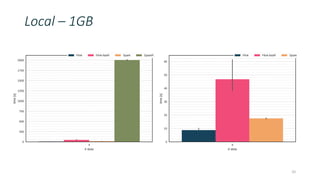
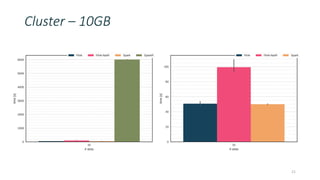


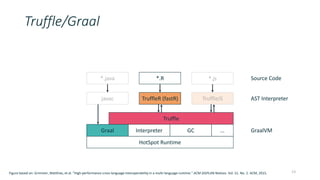
This document discusses providing an R dataframe abstraction for efficient distributed computation on Apache Flink. The goals are to provide a natural API for R and achieve performance comparable to Flink's native dataflow. The approach represents R dataframes as Flink data sets and compiles R functions into the native execution plan where possible. For user-defined R functions, they are evaluated within worker tasks using a just-in-time compiler. This allows executing R code within the same Java virtual machine as Flink for good performance, even on a single node. Results show it can achieve native Flink performance even for functions containing R code.








































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)














