Downloaded 249 times


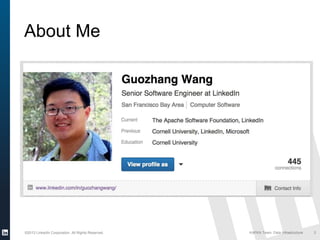






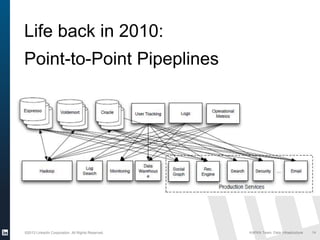
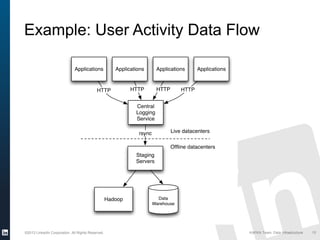
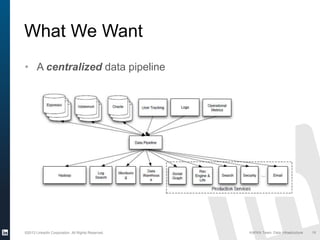



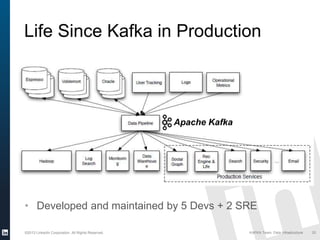


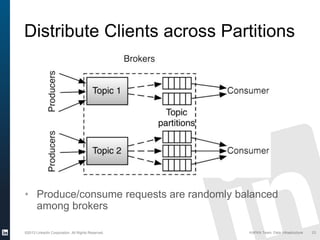

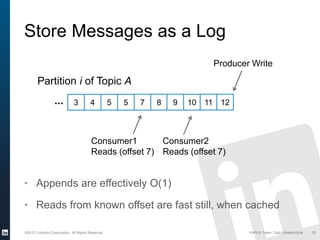





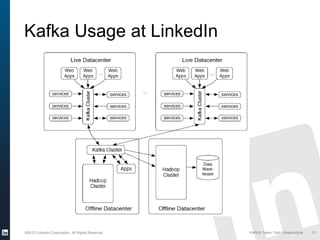
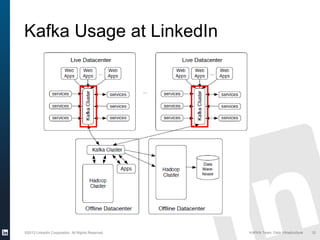
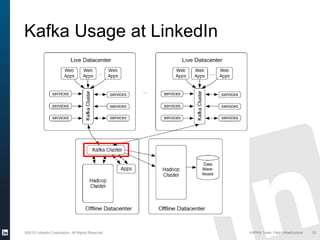




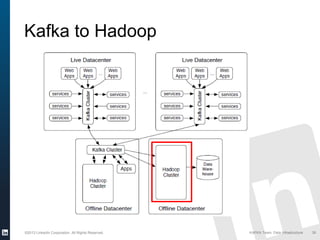








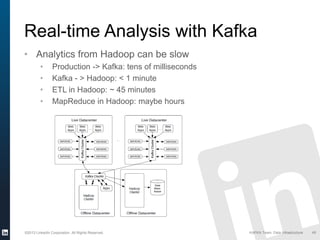



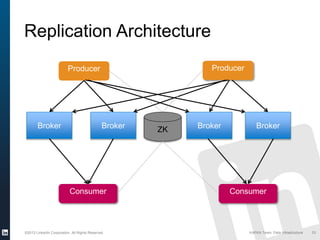

The document discusses Apache Kafka, a distributed publish-subscribe messaging system developed at LinkedIn. It describes how LinkedIn uses Kafka to integrate large amounts of user activity and other data across its products. Key aspects of Kafka's design allow it to scale to LinkedIn's high throughput requirements, including using a log structure and data partitioning for parallelism. LinkedIn relies on Kafka to transport over 500 billion messages per day between systems and for real-time analytics.

















































































