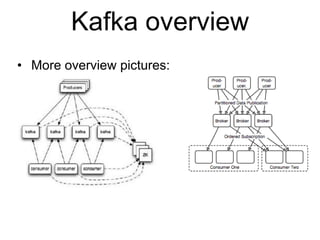
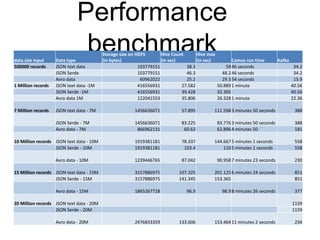
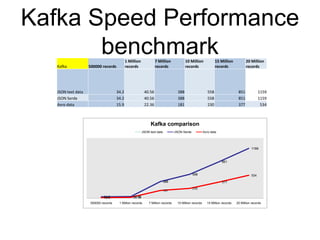
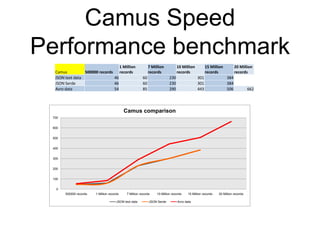
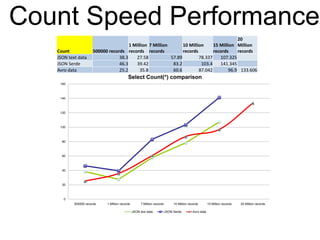
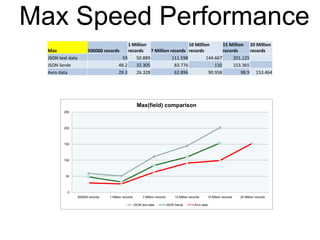
This document summarizes the results of a performance evaluation of Kafka and Camus to ingest streaming data into Hadoop. It finds that Kafka can ingest data at rates from 15,000-50,000 messages per second depending on data format (Avro is fastest). Camus can move the data to HDFS at rates from 54,000-662,000 records per second. Once in HDFS, queries on Avro-formatted data are fastest, with count and max aggregation queries completing in under 100 seconds for 20 million records. The customer's goal of 5000 events per second can be easily achieved with this architecture.