Download to read offline





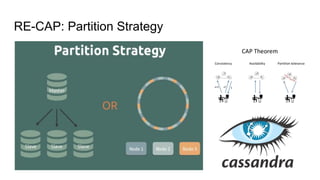
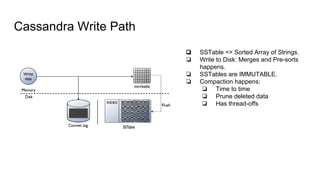

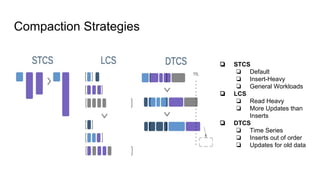
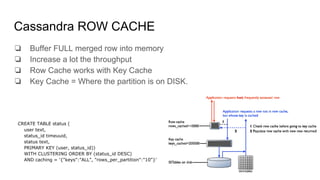

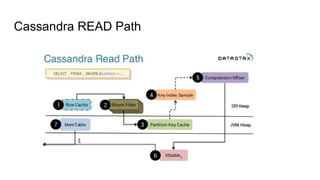








This document summarizes Diego Pacheco's presentation on Cassandra. It covers the Cassandra write path, tombstones, compaction strategies, row and bloom filters, SASI indexes, materialized views, counter families, and anti-patterns. It also discusses Cassandra's implementation at Uber using Mesos. The presentation addresses how data is written to disk in immutable SSTables and compacted over time to remove tombstones, and different compaction strategies for various workloads. It explains techniques like row caching, bloom filters, secondary indexes, materialized views and counters.






























![[Cassandra summit Tokyo, 2015] Cassandra 2015 最新情報 by ジョナサン・エリス(Jonathan Ellis)](https://cdn.slidesharecdn.com/ss_thumbnails/tokyocassandrasummit2015withnotes-150624051836-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)























































