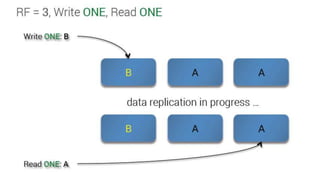
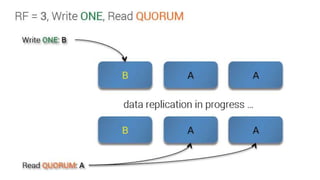
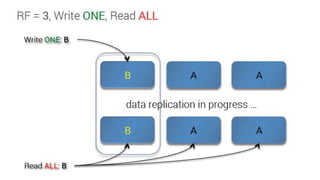
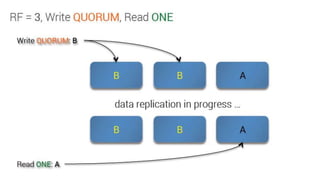
Downloaded 43 times





































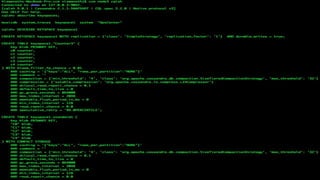



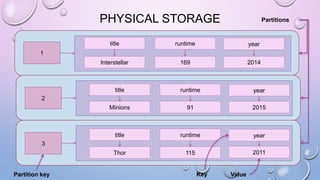



![LIGHT WEIGHT TRANSACTIONS OR
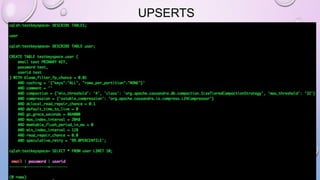
COMPARE AND SET (CAS)
• A NEW CLAUSE IF NOT EXISTS FOR INSERTS
• INSERT OPERATION EXECUTES IF A ROW WITH THE SAME PRIMARY KEY DOES NOT EXIST
• USES A CONSENSUS ALGORITHM CALLED PAXOS TO ENSURE INSERTS ARE DONE SERIALLY
• MULTIPLE MESSAGES ARE PASSED BETWEEN COORDINATOR AND REPLICAS WITH A LARGE
PERFORMANCE PENALTY
[applied] column returns true if row
does not exist and insert executes
[applied] column is false if row exists
and the existing row will be returned](https://image.slidesharecdn.com/gettingstartedwithcassandra-150919112257-lva1-app6892/85/Getting-started-with-Cassandra-2-1-89-320.jpg)
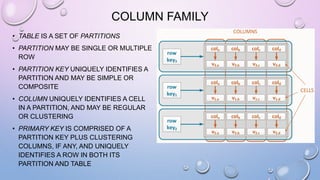
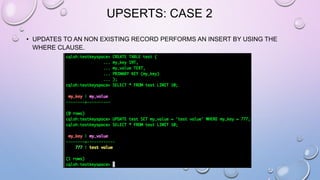
![LIGHT WEIGHT TRANSACTIONS OR
COMPARE AND SET (CAS)
• UPDATE USES IF TO VERIFY THE VALUE FOR COLUMN(S) BEFORE EXECUTION
[applied] column returns true if
condition(s) matches and update
written
[applied] column is false if condition(s)
do not match and the current row will be
returned](https://image.slidesharecdn.com/gettingstartedwithcassandra-150919112257-lva1-app6892/85/Getting-started-with-Cassandra-2-1-90-320.jpg)

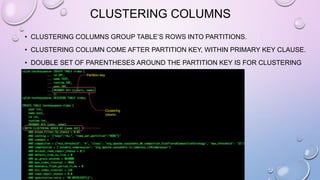



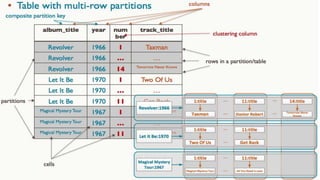






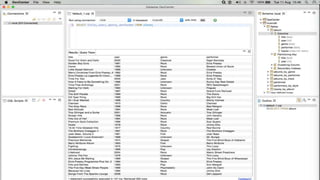
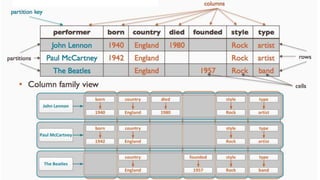
![LIST MANIPULATION
• ADD A LIST DECLARATION TO A TABLE BY ADDING A COLUMN AND MANIPULATE IT
ALTER TABLE USERS ADD TOP_PLACES LIST<TEXT>;
UPDATE USERS SET TOP_PLACES = [ 'RIVENDELL', 'MORDOR' ] WHERE USER_ID = 'FRODO';
UPDATE USERS SET TOP_PLACES[2] = 'RIDDERMARK' WHERE USER_ID = 'FRODO';](https://image.slidesharecdn.com/gettingstartedwithcassandra-150919112257-lva1-app6892/85/Getting-started-with-Cassandra-2-1-105-320.jpg)
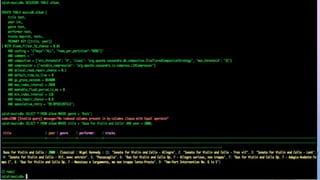
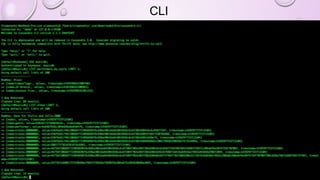
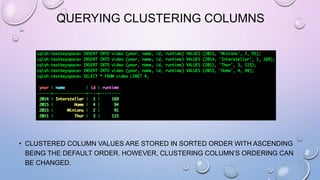
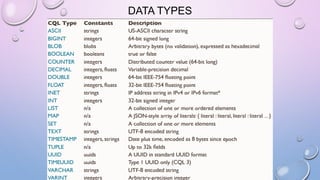
![MAP MANIPULATION
• ADD A TODO LIST TO EVERY USER PROFILE IN AN EXISTING USERS TABLE
ALTER TABLE USERS ADD TODO MAP<TIMESTAMP, TEXT>;
UPDATE USERS
SET TODO = { '2012-9-24' : 'ENTER MORDOR', '2014-10-2 12:00' : 'THROW RING INTO MOUNT
DOOM' }
WHERE USER_ID = 'FRODO';
UPDATE USERS
SET TODO = TODO + { '2013-10-1 18:00': 'CHECK INTO INN OF PRACING PONY'}
WHERE USER_ID='FRODO';
• COMPUTE THE TTL TO USE TO EXPIRE TO-DO LIST ELEMENTS ON THE DAY OF THE
TIMESTAMP, AND SET THE ELEMENTS TO EXPIRE.
UPDATE USERS USING TTL 86400
SET TODO['2012-10-1'] = 'FIND WATER' WHERE USER_ID = 'FRODO';](https://image.slidesharecdn.com/gettingstartedwithcassandra-150919112257-lva1-app6892/85/Getting-started-with-Cassandra-2-1-106-320.jpg)











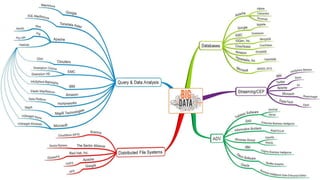
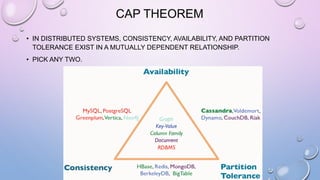
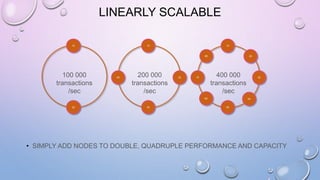
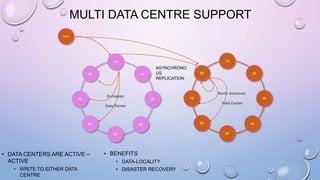
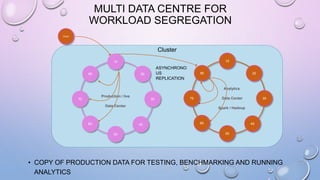
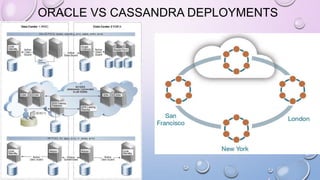
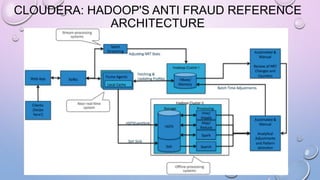
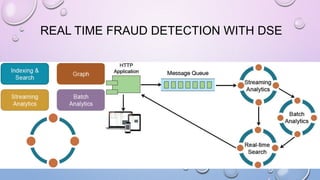
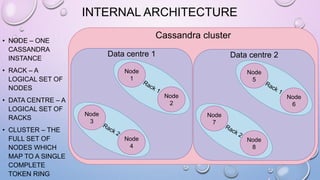
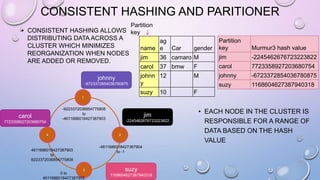
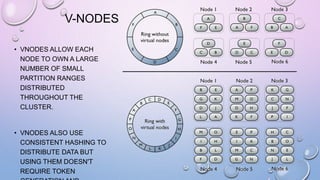
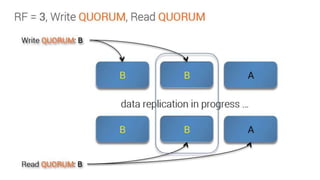
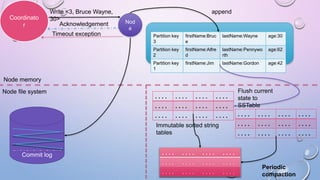
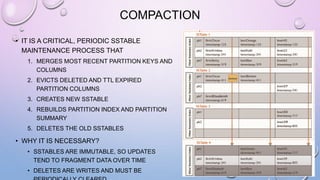
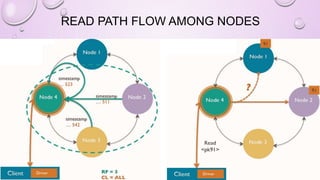
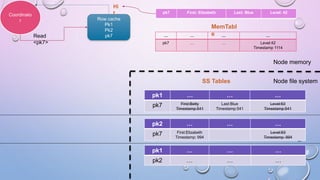
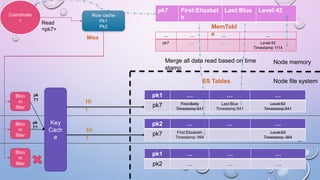
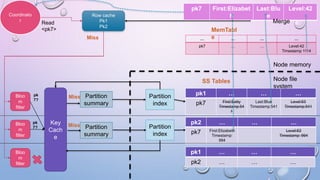
This document provides an overview and introduction to Apache Cassandra, including: - Cassandra is a distributed database designed to handle large amounts of structured data across commodity servers. It provides high availability with no single point of failure and linear scalability. - Cassandra uses a ring topology and consistent hashing to distribute data evenly across nodes. Data is stored in tables with rows mapped to partitions that are replicated across the ring for fault tolerance. - The write path involves writing to memtables, committing to the commit log for durability, flushing memtables to SSTables, and periodic compaction. The read path merges data from memtables, SSTables, commit log and caches for fast retrieval.









































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)
