Download as PDF, PPTX





![[1]
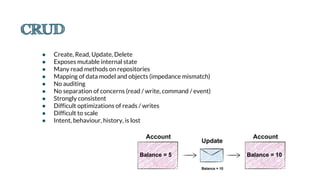
CQRS
Client
QueryCommand
DBDB
Denormalise
/Precompute
Kappa architecture
Batch-Pipeline
Kafka
Allyourdata
NoSQL
SQL
Spark
Client
Client
Client Views
Stream
processor
Flume
Scoop
Hive
Impala
Oozie
HDFS
Lambda Architecture
Batch Layer Serving
Layer
Stream layer (fast)
Query
Query
Allyourdata Serving DB](https://image.slidesharecdn.com/copyofcassandrasummit2015-150924212556-lva1-app6891/85/Cassandra-as-event-sourced-journal-for-big-data-analytics-7-320.jpg)
![[2, 3]](https://image.slidesharecdn.com/copyofcassandrasummit2015-150924212556-lva1-app6891/85/Cassandra-as-event-sourced-journal-for-big-data-analytics-8-320.jpg)







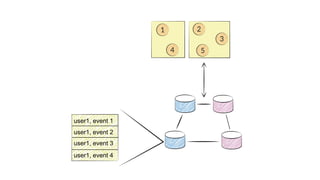




![class UserActorView(userId: String) extends PersistentView {
override def persistenceId: String = UserPersistenceId(userId).persistenceId
override def viewId: String = UserPersistenceId(userId).persistentViewId
override def autoUpdateInterval: FiniteDuration = FiniteDuration(100, TimeUnit.MILLISECONDS)
def receive: Receive = viewState(List.empty)
def viewState(processedDeviations: List[ExercisePlanProcessedDeviation]): Receive = {
case EntireResistanceExerciseSession(_, _, _, _, deviations) if isPersistent =>
context.become(viewState(deviations.filter(condition).map(process) ::: processedDeviations))
case GetProcessedDeviations => sender() ! processedDeviations
}
}](https://image.slidesharecdn.com/copyofcassandrasummit2015-150924212556-lva1-app6891/85/Cassandra-as-event-sourced-journal-for-big-data-analytics-28-320.jpg)

![val readJournal =
PersistenceQuery(system).readJournalFor(CassandraJournal.Identifier)
val source = readJournal.query(
EventsByPersistenceId(UserPersistenceId(name).persistenceId, 0, Long.MaxValue), NoRefresh)
.map(_.event)
.collect{ case s: EntireResistanceExerciseSession => s }
.mapConcat(_.deviations)
.filter(condition)
.map(process)
implicit val mat = ActorMaterializer()
val result = source.runFold(List.empty[ExercisePlanDeviation])((x, y) => y :: x)](https://image.slidesharecdn.com/copyofcassandrasummit2015-150924212556-lva1-app6891/85/Cassandra-as-event-sourced-journal-for-big-data-analytics-30-320.jpg)
![● Potentially infinite stream of events
Source[Any].map(process).filter(condition)
Publisher Subscriber
process
condition
backpressure](https://image.slidesharecdn.com/copyofcassandrasummit2015-150924212556-lva1-app6891/85/Cassandra-as-event-sourced-journal-for-big-data-analytics-31-320.jpg)




![textFile mapmap
reduceByKey
collect
sc.textFile("counts")
.map(line => line.split("t"))
.map(word => (word(0), word(1).toInt))
.reduceByKey(_ + _)
.collect()
[4]](https://image.slidesharecdn.com/copyofcassandrasummit2015-150924212556-lva1-app6891/85/Cassandra-as-event-sourced-journal-for-big-data-analytics-37-320.jpg)

.select("columns")
val processedData = data.flatMap(...)...
processedData.saveToCassandra("keyspace", "table")](https://image.slidesharecdn.com/copyofcassandrasummit2015-150924212556-lva1-app6891/85/Cassandra-as-event-sourced-journal-for-big-data-analytics-40-320.jpg)
![● Akka Analytics project
● Handles custom Akka serialization
case class JournalKey(persistenceId: String, partition: Long, sequenceNr: Long)
lazy val sparkConf: SparkConf =
new SparkConf()
.setAppName(...).setMaster(...).set("spark.cassandra.connection.host", "127.0.0.1")
val sc = new SparkContext(sparkConf)
val events: RDD[(JournalKey, Any)] = sc.eventTable()
events.sortByKey().map(...).filter(...).collect().foreach(println)](https://image.slidesharecdn.com/copyofcassandrasummit2015-150924212556-lva1-app6891/85/Cassandra-as-event-sourced-journal-for-big-data-analytics-41-320.jpg)
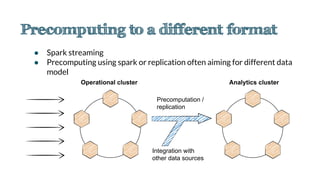
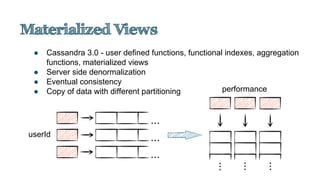
![val events: RDD[(JournalKey, Any)] = sc.eventTable().cache().filterClass[EntireResistanceExerciseSession].flatMap(_.deviations)
val deviationsFrequency = sqlContext.sql(
"""SELECT planned.exercise, hour(time), COUNT(1)
FROM exerciseDeviations
WHERE planned.exercise = 'bench press'
GROUP BY planned.exercise, hour(time)""")
val deviationsFrequency2 = exerciseDeviationsDF
.where(exerciseDeviationsDF("planned.exercise") === "bench press")
.groupBy(
exerciseDeviationsDF("planned.exercise"),
exerciseDeviationsDF("time”))
.count()
val deviationsFrequency3 = exerciseDeviations
.filter(_.planned.exercise == "bench press")
.groupBy(d => (d.planned.exercise, d.time.getHours))
.map(d => (d._1, d._2.size))](https://image.slidesharecdn.com/copyofcassandrasummit2015-150924212556-lva1-app6891/85/Cassandra-as-event-sourced-journal-for-big-data-analytics-43-320.jpg)
![def toVector(user: User): mllib.linalg.Vector =
Vectors.dense(
user.frequency, user.performanceIndex, user.improvementIndex)
val events: RDD[(JournalKey, Any)] = sc.eventTable().cache()
val users: RDD[User] = events.filterClass[User]
val kmeans = new KMeans()
.setK(5)
.set...
val clusters = kmeans.run(users.map(_.toVector))](https://image.slidesharecdn.com/copyofcassandrasummit2015-150924212556-lva1-app6891/85/Cassandra-as-event-sourced-journal-for-big-data-analytics-44-320.jpg)
![val weight: RDD[(JournalKey, Any)] = sc.eventTable().cache()
val exerciseDeviations = events
.filterClass[EntireResistanceExerciseSession]
.flatMap(session =>
session.sets.flatMap(set =>
set.sets.map(exercise => (session.id.id, exercise.exercise))))
.groupBy(e => e)
.map(g =>
Rating(normalize(g._1._1), normalize(g._1._2),
normalize(g._2.size)))
val model = new ALS().run(ratings)
val predictions = model.predict(recommend)
bench
press
bicep
curl
dead
lift
user 1 5 2
user 2 4 3
user 3 5 2
user 4 3 1](https://image.slidesharecdn.com/copyofcassandrasummit2015-150924212556-lva1-app6891/85/Cassandra-as-event-sourced-journal-for-big-data-analytics-45-320.jpg)
![val events: RDD[(JournalKey, Any)] = sc.eventTable().cache()
val connections = events.filterClass[Connections]
val vertices: RDD[(VertexId, Long)] =
connections.map(c => (c.id, 1l))
val edges: RDD[Edge[Long]] = connections
.flatMap(c => c.connections
.map(Edge(c.id, _, 1l)))
val graph = Graph(vertices, edges)
val ranks = graph.pageRank(0.0001).vertices](https://image.slidesharecdn.com/copyofcassandrasummit2015-150924212556-lva1-app6891/85/Cassandra-as-event-sourced-journal-for-big-data-analytics-47-320.jpg)




![[1] http://www.benstopford.com/2015/04/28/elements-of-scale-composing-and-scaling-data-platforms/
[2] http://malteschwarzkopf.de/research/assets/google-stack.pdf
[3] http://malteschwarzkopf.de/research/assets/facebook-stack.pdf
[4] http://www.slideshare.net/LisaHua/spark-overview-37479609](https://image.slidesharecdn.com/copyofcassandrasummit2015-150924212556-lva1-app6891/85/Cassandra-as-event-sourced-journal-for-big-data-analytics-57-320.jpg)

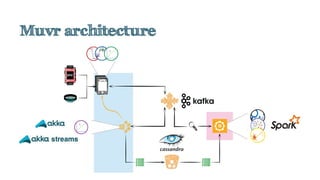
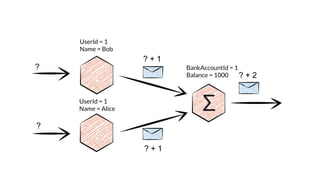
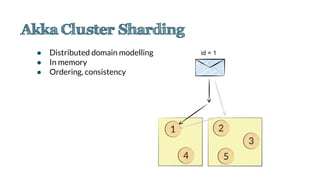
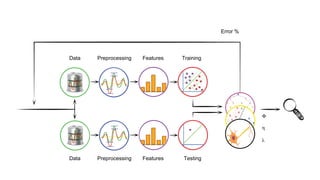
The document discusses an emerging technology stack for managing data, emphasizing the significance of event sourcing, Command Query Responsibility Segregation (CQRS), and various distributed computing technologies like Akka, Spark, and Cassandra. It highlights the challenges of current data integration processes and proposes solutions through the use of immutable data models and optimized data stores. The document also explores the benefits of data analytics and machine learning in leveraging insights from large datasets across different domains.
































































