Download as PDF, PPTX






![12
⚫ Tools for performance tuning
⚫ Performance estimation tool
⚫ Performance projection using Fujitsu FX100
execution profile
⚫ Gives “target” performance
⚫ Post-K processor simulator
⚫ Based on gem5, O3, cycle-level simulation
⚫ Very slow, so limited to kernel-level evaluation
⚫ Co-design of apps
⚫ 1. Estimate “target” performance using
performance estimation tool
⚫ 2. Extract kernel code for simulator
⚫ 3. Measure exec time using simulator
⚫ 4. Feed-back to code optimization
⚫ 5. Feed-back to compiler
Co-design of Apps for Architecture
NICAM OPRT3D_divdamp区間 (1/3
推定方法
性能
予測ツ
メモリ HB
カーネル化、縮小 あ
ソースコード版数 r4_a
浮動小数点数精度 単精
SIMD幅 1
集計スレッド番号 3
実行時間[秒] 2.09E
GFLOPS/プロセス 97
メモリスループット(R+W)
[GB/s/プロセス]
10
メモリスループット(R)
[GB/s/プロセス]
88
メモリスループット(W)
[GB/s/プロセス]
20
浮動小数点演算数
/スレッド
1.77E
実行命令数/スレッド 2.91E
ロード・ストア命令数
/スレッド
9.56E
L1Dミス数/スレッド 1.39E
L2ミス数/スレッド 6.11E
①
②
③
Perform-
ance
estimation
toolcd
Simulator Simulator Simulator
As is Tuning 1
Tuning 2
Target
performance
Executiontime](https://image.slidesharecdn.com/post-k-190412142208/75/Arm-A64fx-and-Post-K-Game-Changing-CPU-Supercomputer-for-HPC-Big-Data-AI-12-2048.jpg)

![◼ OpenMP版を用いてノードあたり演算性能を評価
FX10に対するノードあたり性能向上比
9
8
7
6
5
4
3
2
1
0
NAS Parallel Benchmark of FX100
[Slide by Ikuo Miyoshi, Fujitsu, SSKen2015]
FX10(16スレッド) FX100(32スレッド) Haswell(32スレッド)†
† エラーバーはCPU周波数を1.9GHzに固定しない場合の性能を表す
使用コード: NAS Parallel Benchmarks Ver. 3.3.1 OpenMP版 クラスC
FX100は、FX10比平均3.9倍、Haswell比平均1.3倍のノードあたり演算性能
MG SP FT LU IS BT CG EP
多重格子法 スカラ五重 離散3次元 ガ ウ ス
対角ソルバ フーリエ変換 ザイデル
法
整数ソート ブロック三重 CG法
対角ソルバ カーネル
驚異的並列
LU EPISMG FT CGSP BT
23 Copyright 2015 FUJITSU LIMITED
性能向上比
Note: Haswell:
1 node = 2 chips
32 threads&cores
FX100: 1 node =
1 chip
32 threads&cores](https://image.slidesharecdn.com/post-k-190412142208/75/Arm-A64fx-and-Post-K-Game-Changing-CPU-Supercomputer-for-HPC-Big-Data-AI-23-2048.jpg)
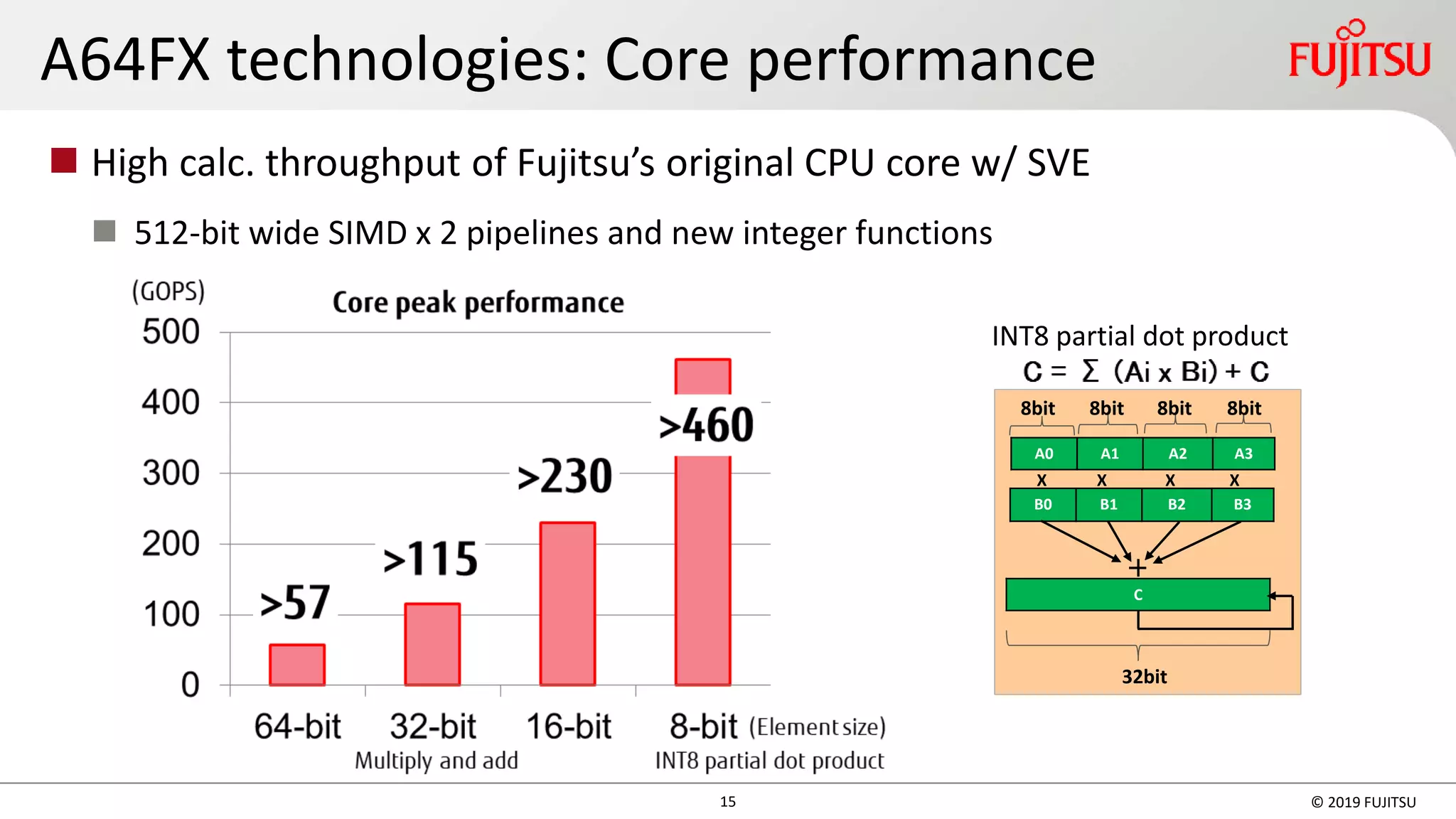
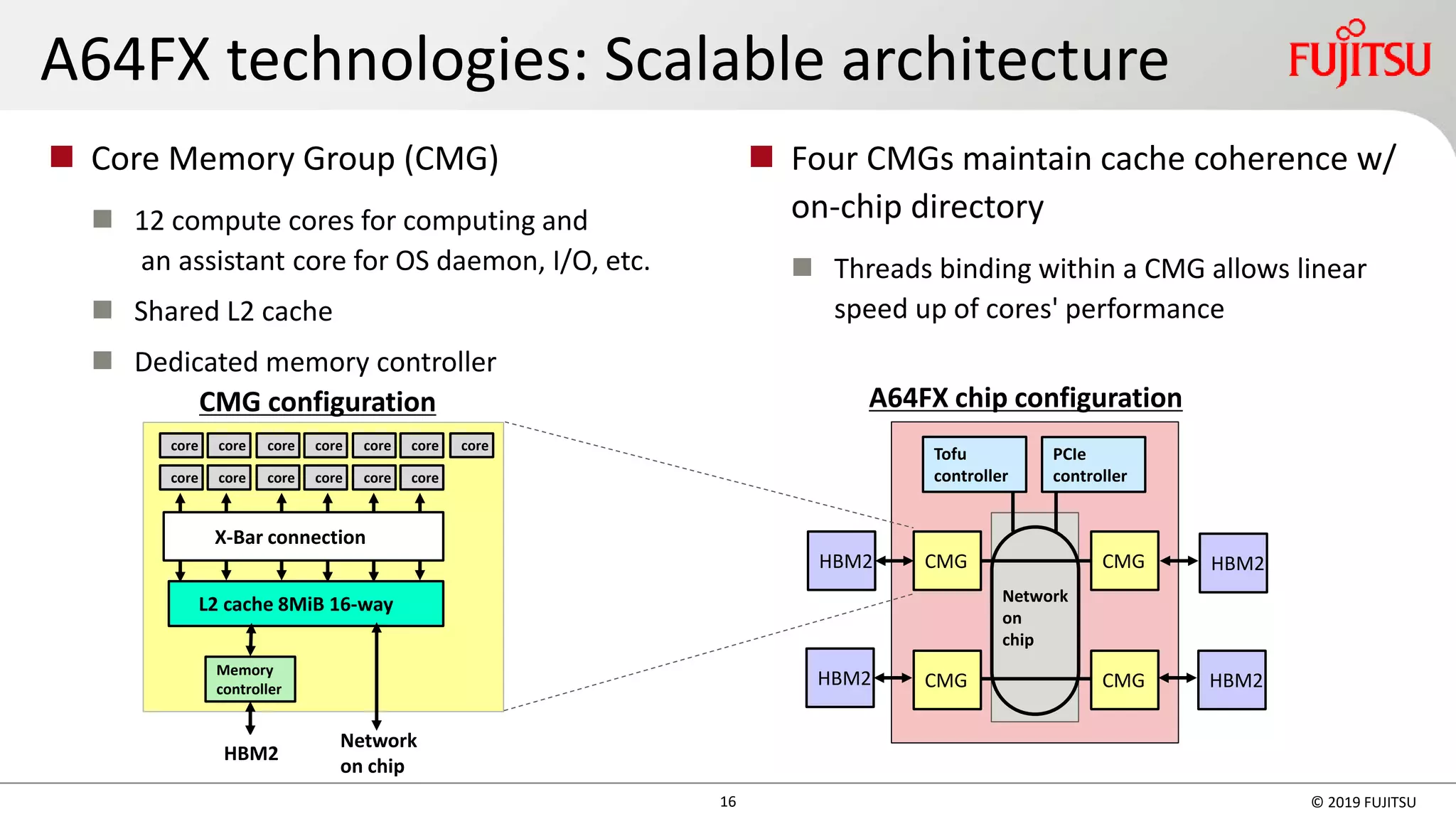
![◼ 評価条件
24 Copyright 2015 FUJITSU LIMITED
◼ 測定結果
FX10に対するノードあたり性能向上比
Fiber ( Post-K) MiniApp on FX100
[Slide by Ikuo Miyoshi, Fujitsu, SSKen2015]
FX100は、FX10比平均3.3倍、
Haswell比平均1.4倍の ノード
あたり性能
注) FFVCには開発版コンパイラ、 NTChemに
は 開発版数学ライブラリを使用。 QCDでは
セクタキャッシュ利用、
FFBではループリローリングのコード変更を実
施
アプリ名 問題サイズ 評価区間 スレッド数×プロセス数
(左からFX10、FX100、Haswell)
CCS QCD 32×32×32×32 BiCGStab 16t×2p 32t×1p 16t×2p
NICAM-DC-MINI gl05rl00z80pe10 Dynamics 3t×10p
FFB-MINI 1,048,576要素 MAIN_LOOP 1t×32p 8t×4p 1t×32p
FFVC-MINI 256×256×256 Total 4t×8p 16t×2p
NTChem-MINI taxol RIMP2_Driver 1t×32p 16t×2p 2t×16p
Note: Haswell:
1 node = 2 chips
32 threads&cores
FX100: 1 node =
1 chip
32 threads&cores](https://image.slidesharecdn.com/post-k-190412142208/75/Arm-A64fx-and-Post-K-Game-Changing-CPU-Supercomputer-for-HPC-Big-Data-AI-24-2048.jpg)








The document discusses the development and capabilities of the ARM A64FX processor and the Post-K supercomputer at the RIKEN Center for Computational Science, emphasizing its high performance in high-performance computing (HPC), optimization for AI and big data applications, and advancements in architecture. It details specifications such as the number of cores, memory bandwidth, power efficiency, and its potential contributions to various scientific domains. The A64FX is positioned as a significant leap toward exascale computing, offering capabilities that greatly exceed prior systems, including unique features designed for next-generation computing applications.























































































