Downloaded 10 times















































![Maxeler: Research (Google: good
method)
Structure of a Typical Research Paper: Scenario #1
[Comparison of Platforms for One Algorithm]
Curve A: MultiCore of approximately the same PurchasePrice
Curve B: ManyCore of approximately the same PurchasePrice
Curve C: Maxeler after a direct algorithm migration
Curve D: Maxeler after algorithmic improvements
Curve E: Maxeler after data choreography
Curve F: Maxeler after precision modifications
Structure of a Typical Research Paper: Scenario #2
[Ranking of Algorithms for One Application]
CurveSet A: Comparison of Algorithms on a MultiCore
CurveSet B: Comparison of Algorithms on a ManyCore
CurveSet C: Comparison on Maxeler, after a direct algorithm migration
CurveSet D: Comparison on Maxeler, after algorithmic improvements
CurveSet E: Comparison on Maxeler, after data choreography
CurveSet F: Comparison on Maxeler, after precision modifications
50/52
50/8](https://image.slidesharecdn.com/dataflowsupercomputing-valentinabalas-130215153808-phpapp02/85/Data-flow-super-computing-valentina-balas-50-320.jpg)



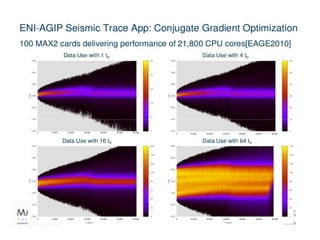
This document discusses speedups and efficiencies achieved using dataflow architectures compared to multicore and manycore systems for big data algorithms. It reports speedups of 20-200x and reductions in electricity costs of 20 times using hardware produced in Europe and software generated by EU/WB programmers. Programming dataflow machines requires adapting algorithms for a different computational model and is more difficult than traditional architectures. Several application examples are provided that demonstrate speedups, including geoscience, banking, modeling, and seismic imaging.



































![[Harvard CS264] 16 - Managing Dynamic Parallelism on GPUs: A Case Study of Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/managingdynamicparallelism-110430142356-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

































