







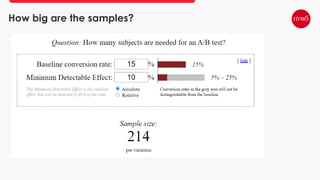

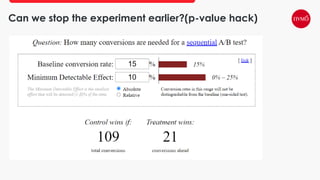









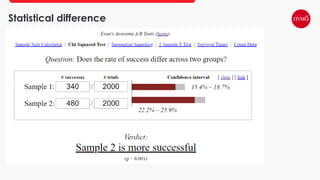




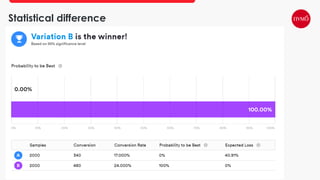

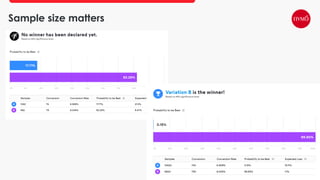


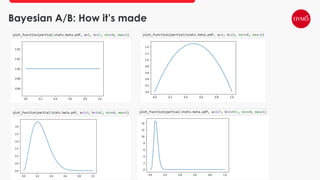

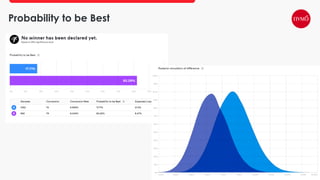



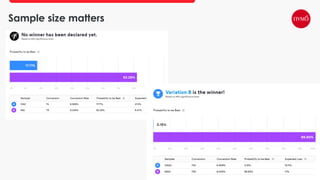

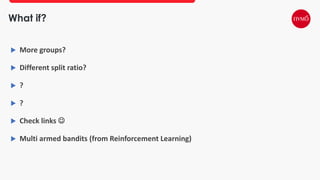
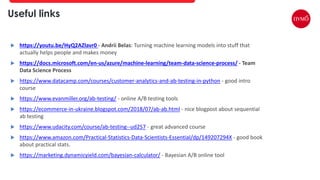


This document provides an overview of A/B testing, addressing its importance for data scientists, ML engineers, and product managers. It covers the use-cases, approaches, and tools necessary for effective A/B testing while emphasizing the role of business impact over accuracy. The document also contrasts frequentist and Bayesian A/B testing methods, highlighting sample size considerations and the implications of statistical significance.








































![[DSC Adria 23]Rok Piltaver Lessons Learned From 10 Years of AB Testing.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/rokpiltaverlessonslearnedfrom10yearsofabtesting-230530180353-baf610f5-thumbnail.jpg?width=640&height=640&fit=bounds)














































