Downloaded 61 times







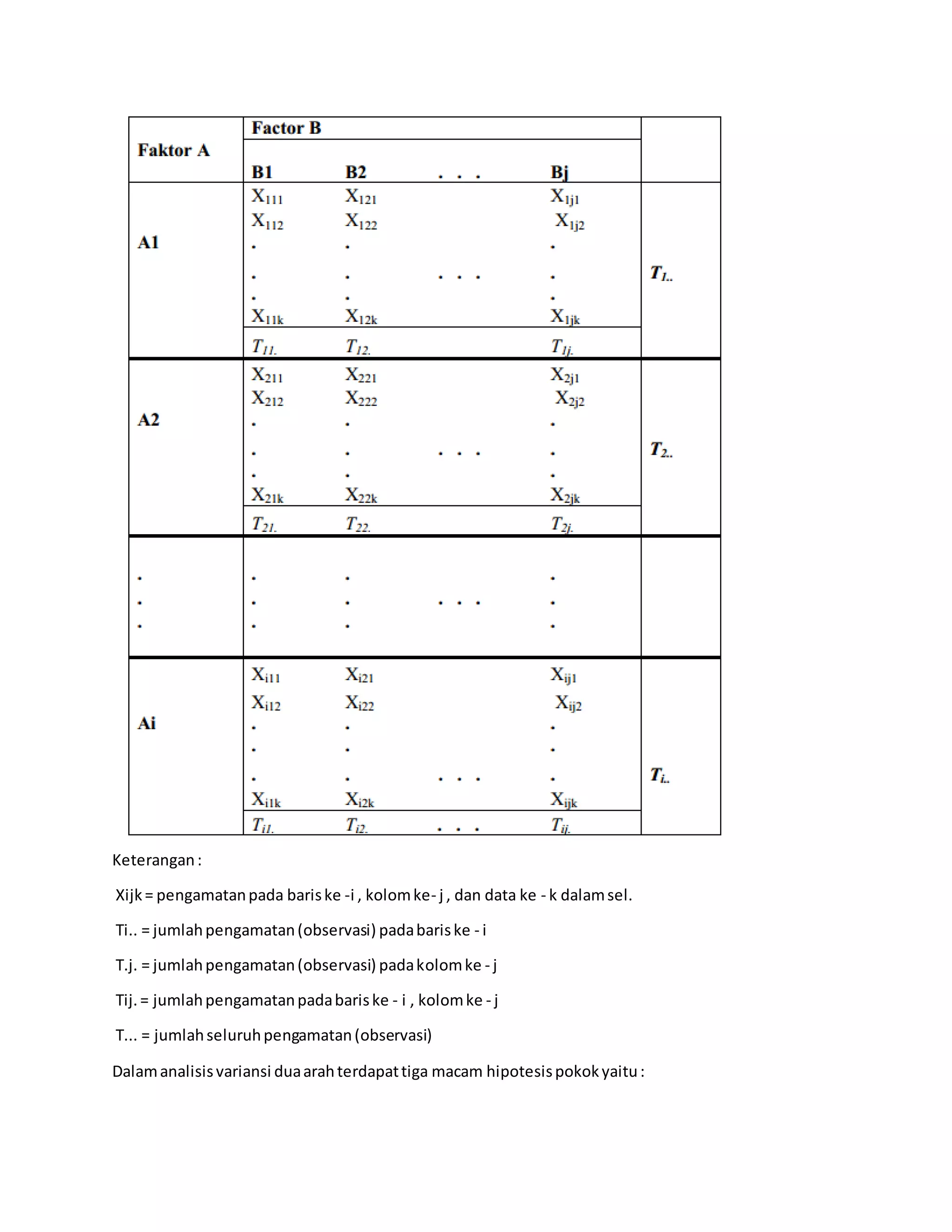



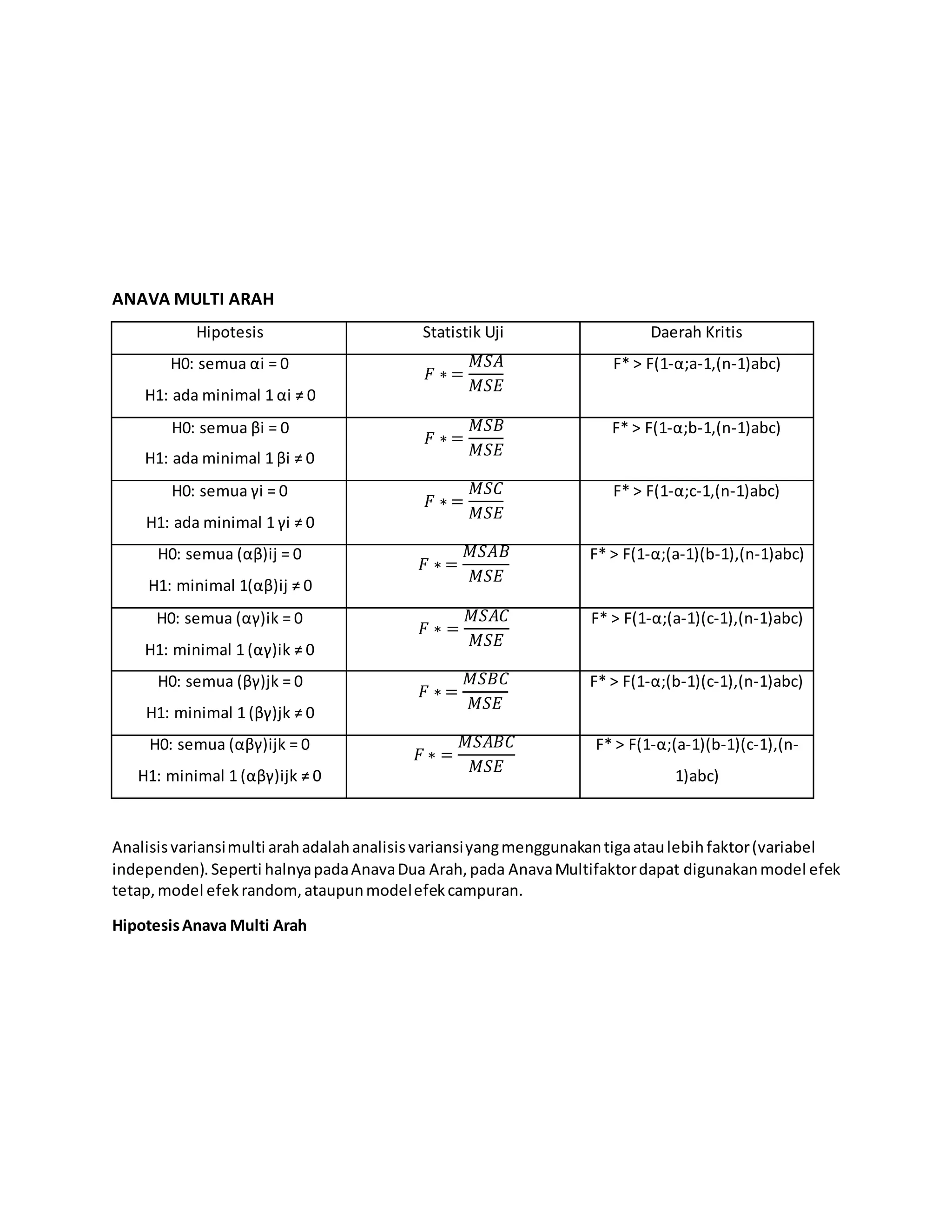


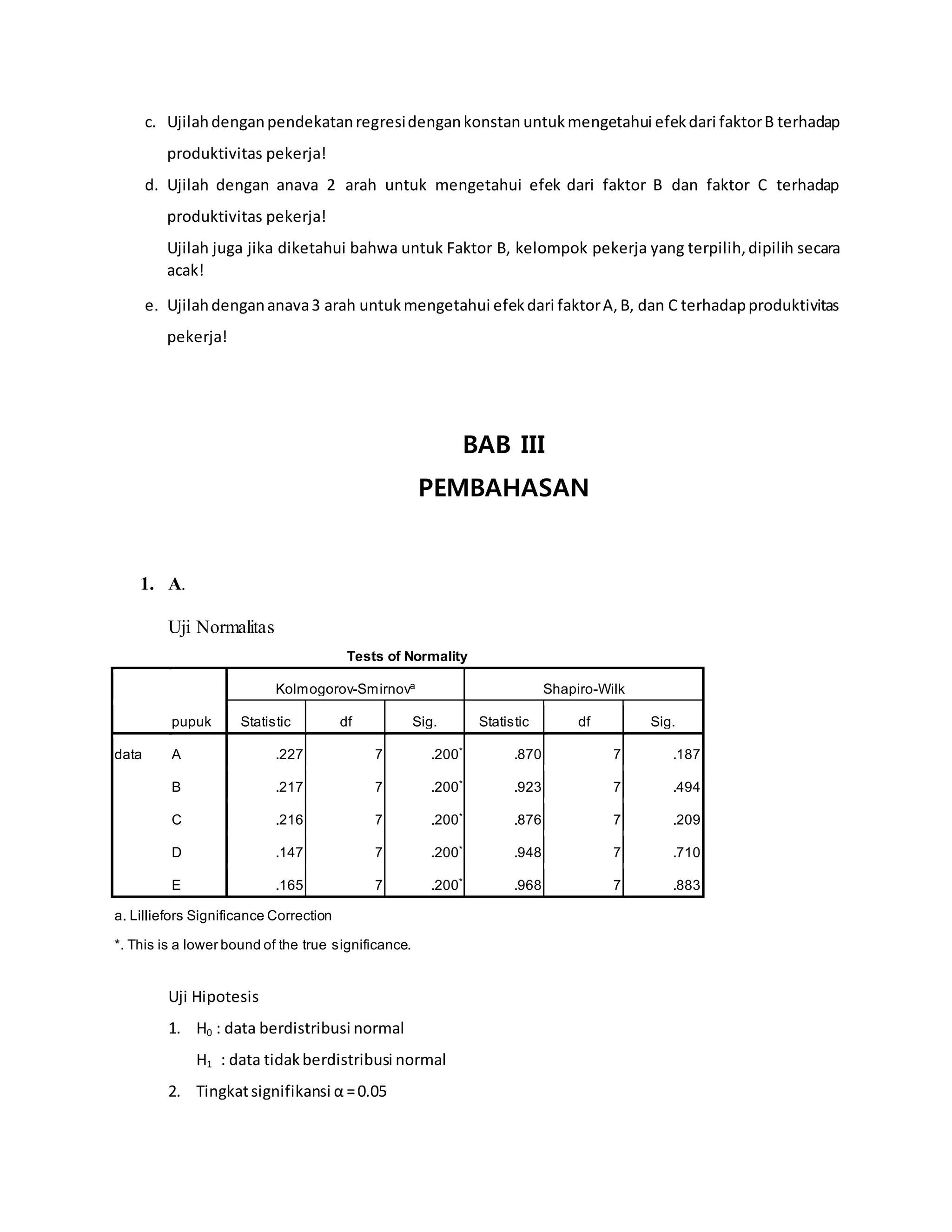

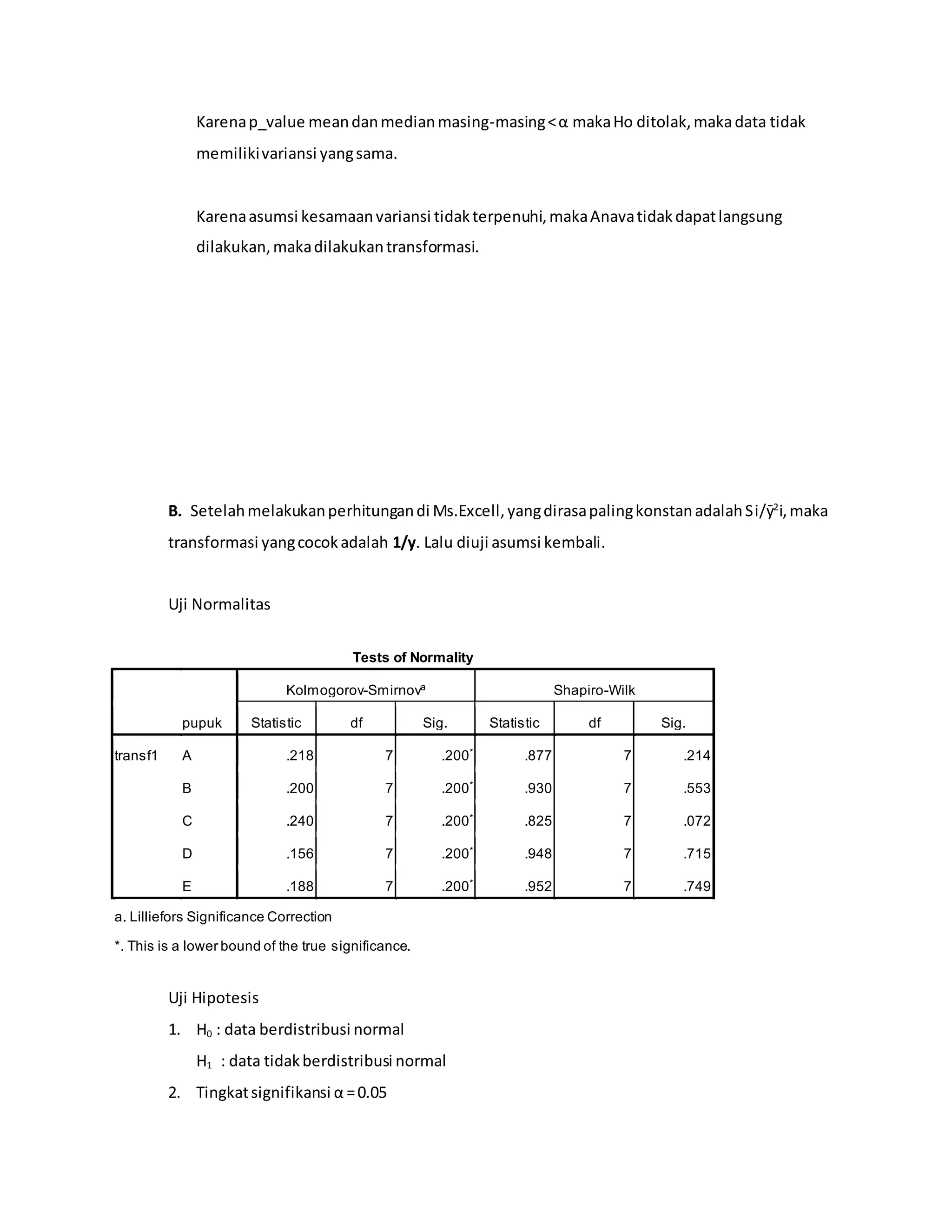
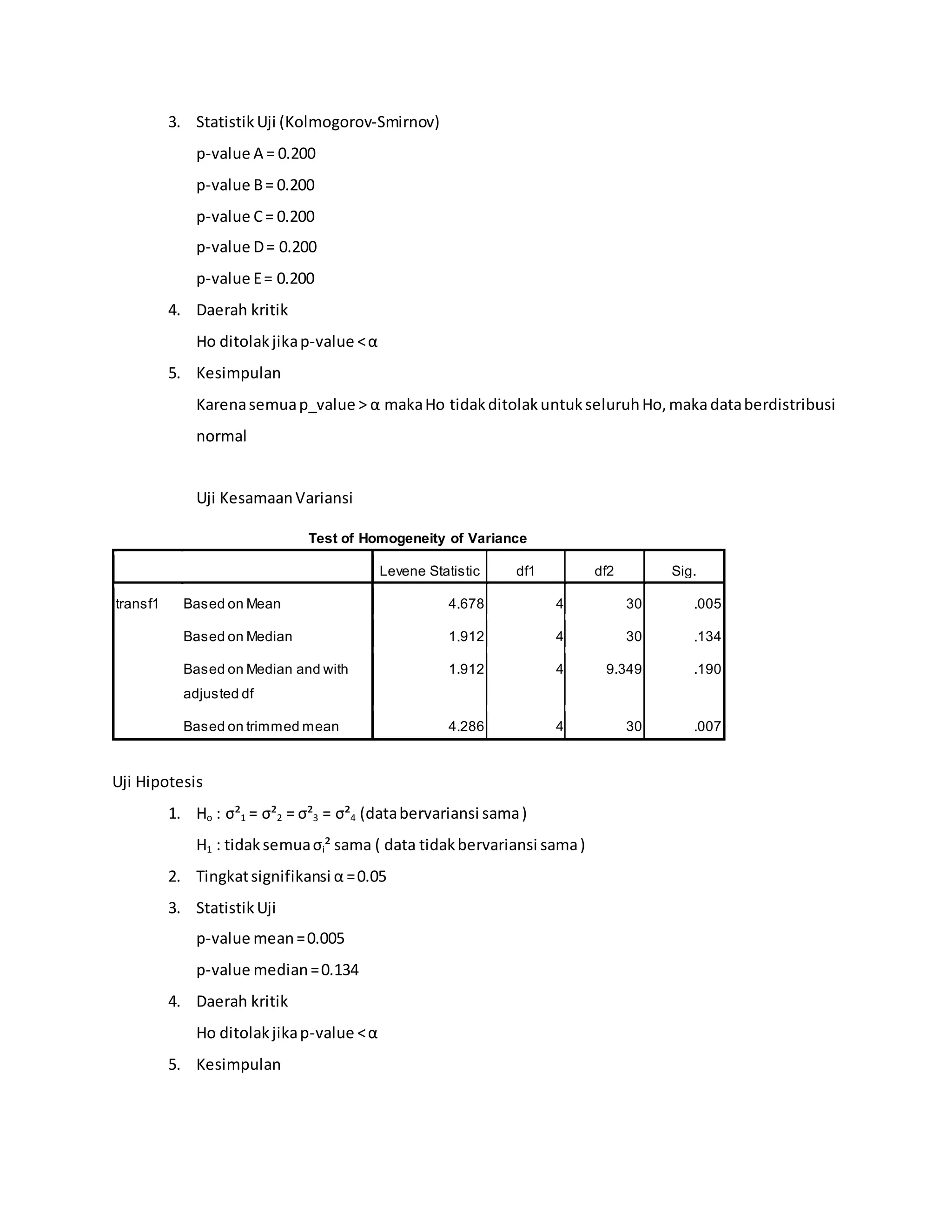















Laporan ini membahas praktikum analisis variansi terapan. Terdapat beberapa bab yang membahas landasan teori ANOVA satu arah dan dua arah beserta contoh soal dan penyelesaiannya. Soal uji kasus menguji pengaruh jenis pupuk terhadap hasil panen gabah dan pengaruh faktor shift kerja, kelompok pekerja dan jenis kelamin terhadap produktivitas pekerja.














































































