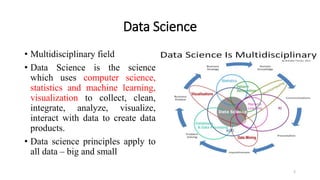
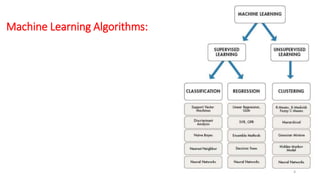
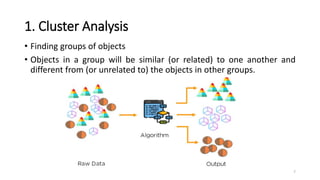
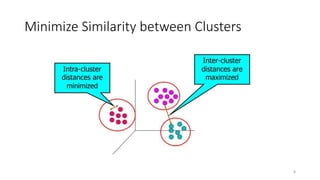
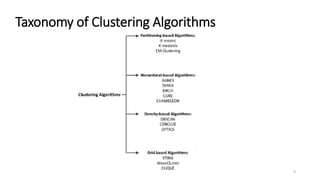
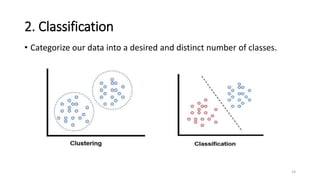
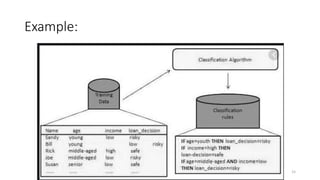
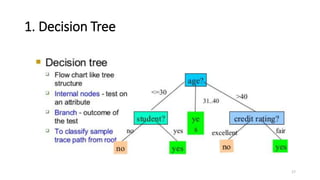
This document discusses machine learning algorithms in R. It provides an overview of machine learning, data science, and the 5 V's of big data. It then discusses two main machine learning algorithms - clustering and classification. For clustering, it covers k-means clustering, providing examples of how to implement k-means clustering in R. For classification, it discusses decision trees, K-nearest neighbors (KNN), and provides an example of KNN classification in R. It also provides a brief overview of regression analysis, including examples of simple and multiple linear regression in R.








![K-means-clustering in R
// Before Clustering
// Explore data
library(datasets)
head(iris)
library(ggplot2)
ggplot(iris, aes(Petal.Length, Petal.Width, color = Species)) + geom_point()
// After K-means Clustering
set.seed(20)
irisCluster <- kmeans(iris[, 3:4], 3)
irisCluster
irisCluster$cluster <- as.factor(irisCluster$cluster)
ggplot(iris, aes(Petal.Length, Petal.Width, color = irisCluster$cluster)) + geom_point()
13](https://image.slidesharecdn.com/slideshare-dataanalytics-200218110153/85/Machine-Learning-in-R-13-320.jpg)


![KNN classification in R
df <- data(iris) ##load data
head(iris) ## see the stucture
##Generate a random number that is 90% of the total number of rows in dataset.
ran <- sample(1:nrow(iris), 0.9 * nrow(iris))
##the normalization function is created
nor <-function(x) { (x -min(x))/(max(x)-min(x)) }
##Run nomalization on first 4 coulumns of dataset because they are the predictors
iris_norm <- as.data.frame(lapply(iris[,c(1,2,3,4)], nor))
summary(iris_norm)
##extract training set
iris_train <- iris_norm[ran,]
##extract testing set
iris_test <- iris_norm[-ran,]
##extract 5th column of train dataset because it will be used as 'cl' argument in knn function.
iris_target_category <- iris[ran,5]
##extract 5th column if test dataset to measure the accuracy
iris_test_category <- iris[-ran,5]
##load the package class
library(class)
##run knn function
pr <- knn(iris_train,iris_test,cl=iris_target_category,k=13)
##create confusion matrix
tab <- table(pr,iris_test_category)
##this function divides the correct predictions by total number of predictions that tell us how accurate teh
model is.
accuracy <- function(x){sum(diag(x)/(sum(rowSums(x)))) * 100}
accuracy(tab)
22](https://image.slidesharecdn.com/slideshare-dataanalytics-200218110153/85/Machine-Learning-in-R-22-320.jpg)


![Multiple Linear Regression:
input <- mtcars[,c("mpg","disp","hp","wt")]
print(head(input))
// Create Relationship Model & get the Coefficients
input <- mtcars[,c("mpg","disp","hp","wt")]
# Create the relationship model.
model <- lm(mpg~disp+hp+wt, data = input)
# Show the model.
print(model)
# Get the Intercept and coefficients as vector elements.
cat("# # # # The Coefficient Values # # # ","n")
a <- coef(model)[1]
print(a)
Xdisp <- coef(model)[2]
Xhp <- coef(model)[3]
Xwt <- coef(model)[4]
print(Xdisp)
print(Xhp)
print(Xwt)
25](https://image.slidesharecdn.com/slideshare-dataanalytics-200218110153/85/Machine-Learning-in-R-25-320.jpg)



































































