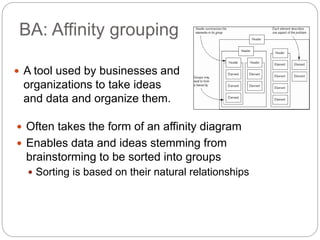
The document provides an overview of business analytics (BA) including its history, types, examples, challenges, and relationship to data mining. BA involves exploring past business performance data to gain insights and guide planning. It can focus on specific business segments. Types of BA include reporting, affinity grouping, clustering, and predictive analytics. Challenges to BA include acquiring high quality data and rapidly processing large volumes of data. Data mining is an important part of BA, helping to sort and analyze large datasets.































































![Green Printing at UK Government Department [Infographic]](https://cdn.slidesharecdn.com/ss_thumbnails/greeneconomicalprintingataukcentralgovernmentdepartment-150903235233-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

































































