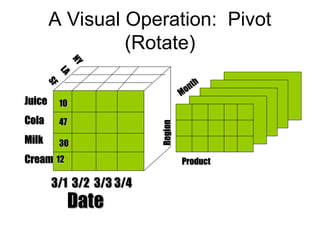
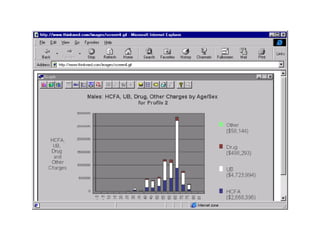
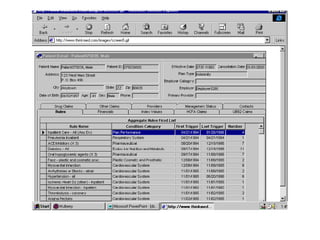
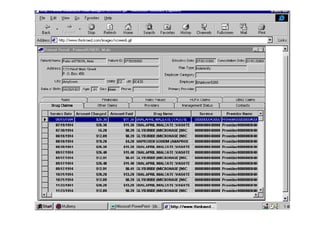
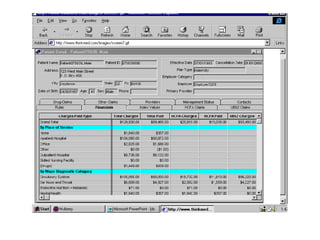
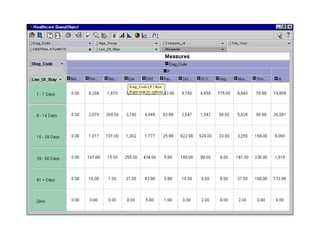
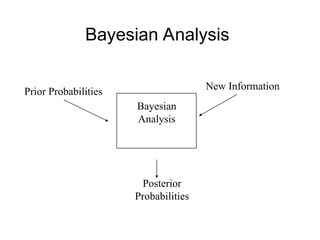
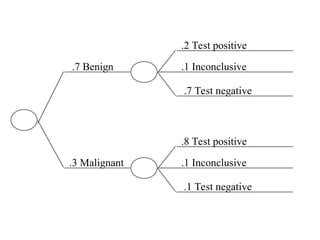
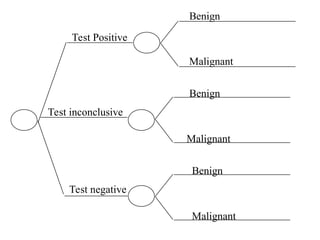
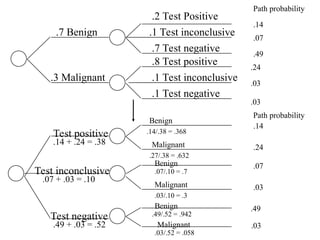
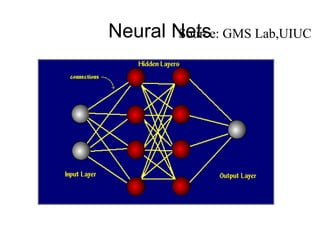
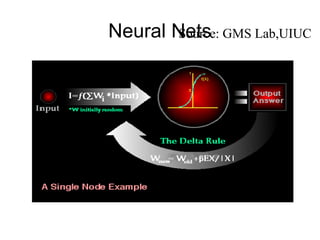
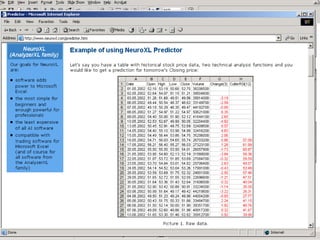
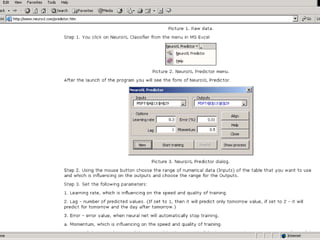
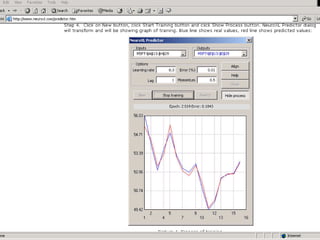
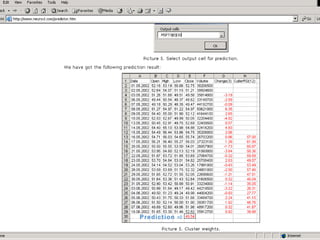
The document outlines the fundamentals of Online Analytical Processing (OLAP) and compares it to Online Transaction Processing (OLTP), highlighting OLAP's ability to support ad-hoc querying and provide multidimensional views of data for business analysts. It discusses various OLAP server types, including MOLAP, ROLAP, and HOLAP, and their respective advantages and disadvantages, as well as tools for data extraction, transformation, load (ETL), and reporting. Additionally, it covers data mining methods and approaches to knowledge discovery in databases, alongside the importance of data visualization in analyzing complex relationships.



![OLTP vs. OLAP
On-Line Transaction Processing (OLTP):
– technology used to perform updates on operational
or transactional systems (e.g., point of sale systems)
On-Line Analytical Processing (OLAP):
– technology used to perform complex analysis of the
data in a data warehouse
OLAP is a category of software technology that enables analysts,
managers, and executives to gain insight into data through fast,
consistent, interactive access to a wide variety of possible views
of information that has been transformed from raw data to reflect
the dimensionality of the enterprise as understood by the user.
[source: OLAP Council: www.olapcouncil.org]](https://image.slidesharecdn.com/analysistechnologies-day3slides-241128042927-6af02fc1/85/Analysis-technologies-day3-slides-Lecture-notesppt-3-320.jpg)