Download to read offline



![Research context
• Introduction:
1. Label smoothing (LS) has been used successfully to improve the accuracy of
Neural Networks (NN) by computing cross entropy with soft targets rather
than hard targets
• E.g., image classification, speech recognition, and machine translation
• Definition of Label smoothing (LS)
1. uses soft targets that are a weighted average of the hard targets and the
uniform distribution over labels
• E.g, for hard label y = 1, 0, 0 soft label y𝐿𝑆
= 1 − 0.1 +
0.1
3
,
0.1
3
,
0.1
3
= [
2.8
3
,
0.1
3
,
0.1
3
]
4
Source:
Müller, Rafael, Simon Kornblith, and Geoffrey Hinton. "When does label smoothing help?." arXiv preprint arXiv:1906.02629 (2019).](https://image.slidesharecdn.com/202110193-classimageclassificationwithsoftlabelssharedver-211021073538/85/20211019-When-does-label-smoothing-help_shared-ver-4-320.jpg)


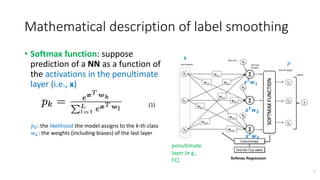
![Mathematical description of label smoothing
• Cross-entropy: we minimize the expected value of the cross-entropy
between the targets 𝑦𝑘 and the network’s outputs 𝑝𝑘 as in
1. For a network trained with hard targets:
𝑦𝑘 - one-hot encoder
2. For a network trained with soft target:
replace 𝑦𝑘 with 𝑦𝑘
𝐿𝑆
-
E.g., if α =0.1, K=3: y1 = 1, 0, 0 y1
𝐿𝑆
= 1 ∗ 0.9 +
0.1
3
,
0.1
3
,
0.1
3
= [
2.8
3
,
0.1
3
,
0.1
3
] 8
i.e., 𝑦𝑘 is "1" for the correct class and "0" for the rest.
α: a label smoothing of parameter](https://image.slidesharecdn.com/202110193-classimageclassificationwithsoftlabelssharedver-211021073538/85/20211019-When-does-label-smoothing-help_shared-ver-8-320.jpg)






The document explores the effectiveness of label smoothing (LS) in enhancing neural network accuracy and addresses the lack of understanding behind its success. It describes how LS leads to tighter clustering of penultimate layer representations and helps prevent over-confidence in predictions, benefiting model generalization and calibration. However, it also notes that LS can reduce mutual information, which may adversely affect applications like knowledge distillation.















































