Download as PDF, PPTX







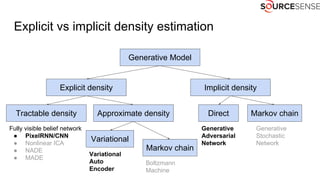

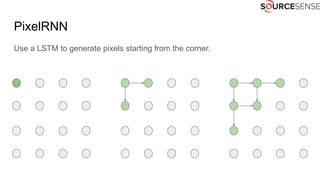
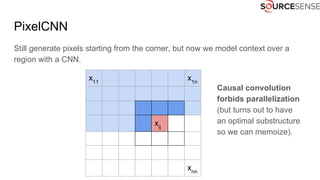
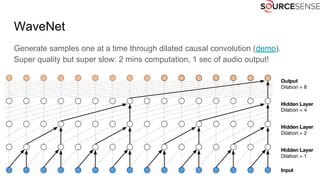

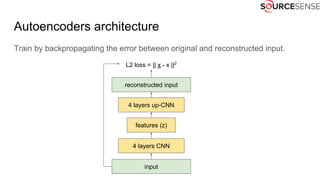

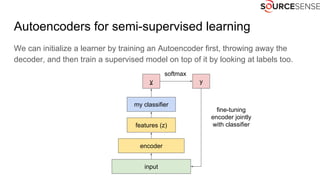
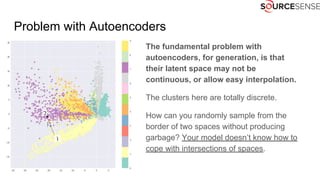
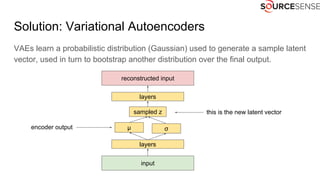
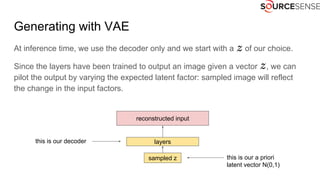










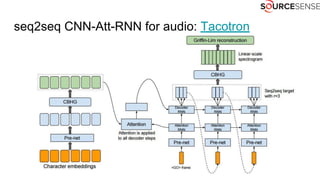



The document outlines the expertise and services of a company specializing in enterprise solutions using open source technology, with a focus on machine learning and generative models. It discusses supervised and unsupervised learning, deep generative models including Variational Autoencoders and Generative Adversarial Networks, and their applications in image and audio generation. Key concepts such as autoencoders, latent space, and image-to-image translation are explored, referencing notable tutorials and studies in the field.





















































































