








![WASEDA
UNIVERSITY
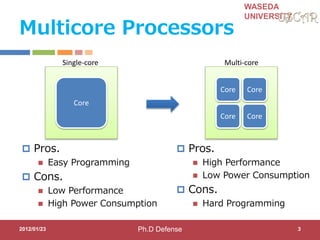
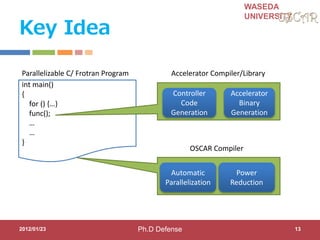
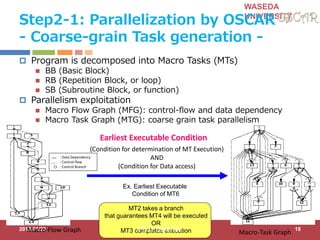
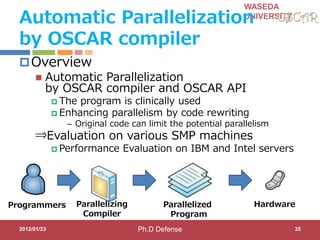
Step1: Hint Directives
for OSCAR Compiler for parallelization
2012/01/23
#pragma oscar_hint accelerator_task (ACCa) cycle(1000, ((OSCAR_DMAC())))
#pragma oscar_hint accelerator_task (ACCb) cycle(100) in(var1, x[2:11]) out(x[2:11])
void call_FFT(int var, int *x) {
#pragma oscar_comment XXXXXXXXXX
FFT(var, x);
} Accelerator compilers or programmers specify execution time and
input/output variables for accelerate-able program part
17
for (i = 0; I < 10; i++) {
x[i]++;
}
call_FFT(var1, x);
Accelerator Name Clock cycle
Input/output variables
Data transfer
Ph.D Defense](https://image.slidesharecdn.com/ahayashi20120123-140528154214-phpapp01/85/Studies-on-Automatic-Parallelization-for-Heterogeneous-and-Homogeneous-Multicore-Processors-17-320.jpg)
![WASEDA
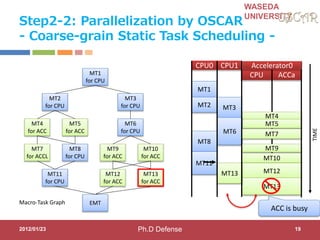
UNIVERSITY
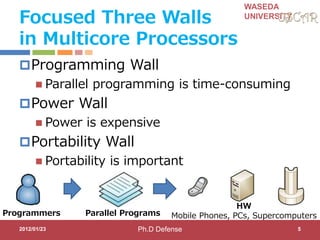
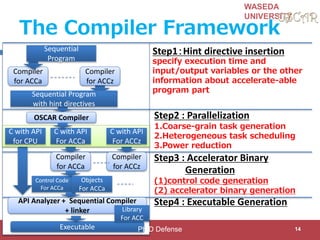
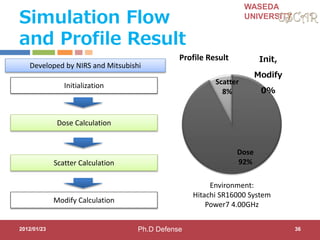
Step 2-3:Power Reduction
Compiler changes Frequency/Voltage
CPU0 CPU1 CPU2 CPU3 CPU ACCa CPU ACCb CPU ACCc CPU ACCd
SLEEP
Timer
SLEEP SLEEP SLEEP
SLEEP SLEEPSLEEPMID MID MID MID
TIME
cycle
deadline
=33[ms]
SLEEP
MID
2012/01/23 20
MID
MID
MID
MID
MID
MID
MID
MID
MID
MID
MID
MID
MID
MID
MID
MID
MID
MID
FULL:648MHz
@1.3V
MID:
324MHz@1.1
V
LOW:
162MHz@1.0
V
SLEEP:
Ph.D Defense](https://image.slidesharecdn.com/ahayashi20120123-140528154214-phpapp01/85/Studies-on-Automatic-Parallelization-for-Heterogeneous-and-Homogeneous-Multicore-Processors-20-320.jpg)
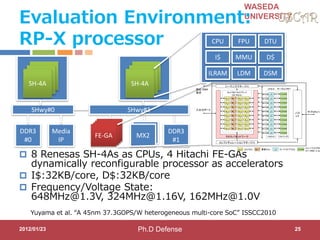
![WASEDA
UNIVERSITY
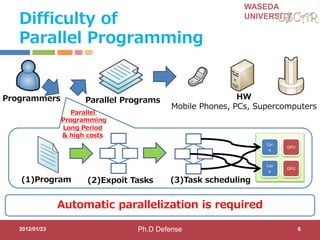
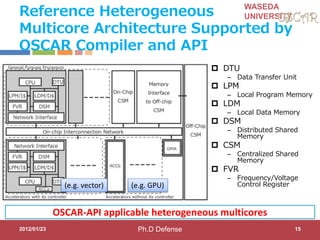
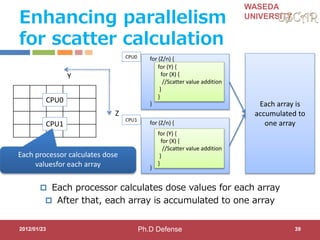
Step3:Role of Accelerator Compilers
Accelerator compilers generate both controller CPU
code and accelerator binary
2012/01/23
C with OSCAR API
#pragma oscar accelerator_task_entry
controller(1) oscartask_CTRL1_loop2
void oscartask_CTRL1_loop2(int *x)
{
int i;
for (i = 0; i <= 9; i += 1) {
x[i]++;
}
}
21
Controller CPU code
void
oscartask_CTRL1_loop2
(int *x)
{
// Data-transfer
// Kernel Invocation
// Data-transfer
}
Accelerator binary
CPU1
ACC
Ph.D Defense](https://image.slidesharecdn.com/ahayashi20120123-140528154214-phpapp01/85/Studies-on-Automatic-Parallelization-for-Heterogeneous-and-Homogeneous-Multicore-Processors-21-320.jpg)



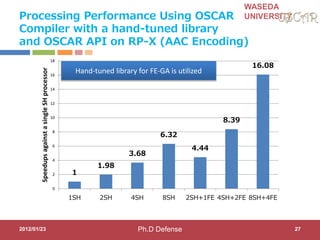
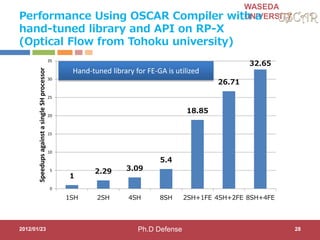

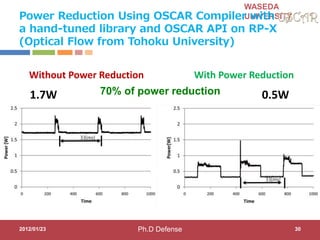
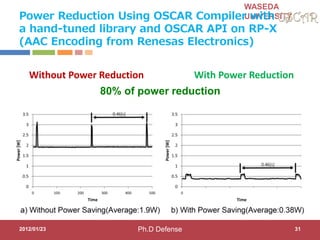






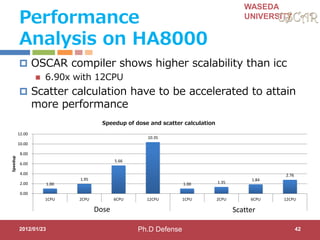

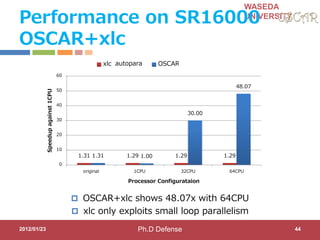
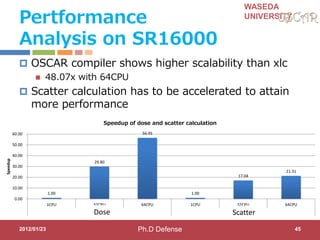
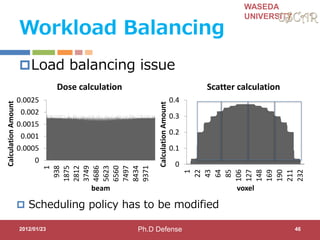










This document discusses research on automatic parallelization for heterogeneous and homogeneous multicore processors. It presents Akihiro Hayashi's PhD defense at Waseda University on this topic. It motivates the need for automatic parallelization due to difficulties in programming multicore processors. It proposes a solution called OSCAR that uses a heterogeneous multicore compiler with APIs to enable automatic parallelization across different processor types. The methodology involves hint directives, parallelization of tasks, power reduction techniques, and generation of executables. It evaluates the approach on media applications using a Renesas multicore processor.




























![[Harvard CS264] 03 - Introduction to GPU Computing, CUDA Basics](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201103-cudabasicsshare-110209024624-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



































