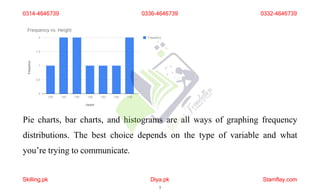
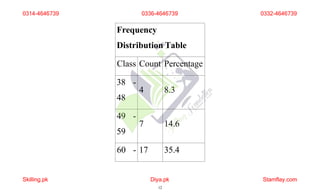
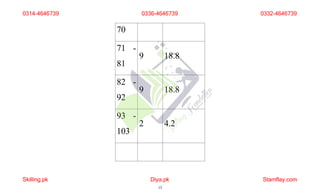
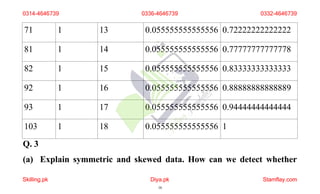
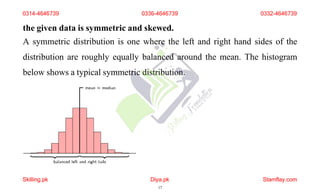
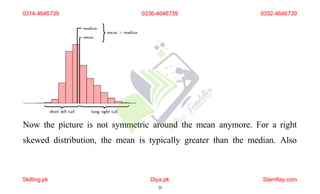
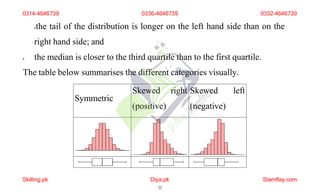
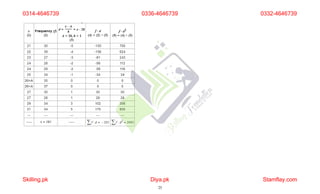
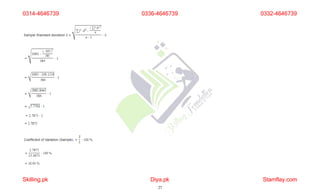
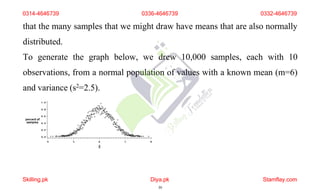
The document discusses frequency distribution and its importance in statistics, outlining its types and the organization of data through tables and graphical representations. It explains various graphical methods to represent frequency distributions, such as pie charts, bar charts, and histograms, each with their specific uses and advantages. Additionally, the document covers Chebyshev's theorem, skewness in data distributions, and methods for assessing consistency and measuring sales performance.