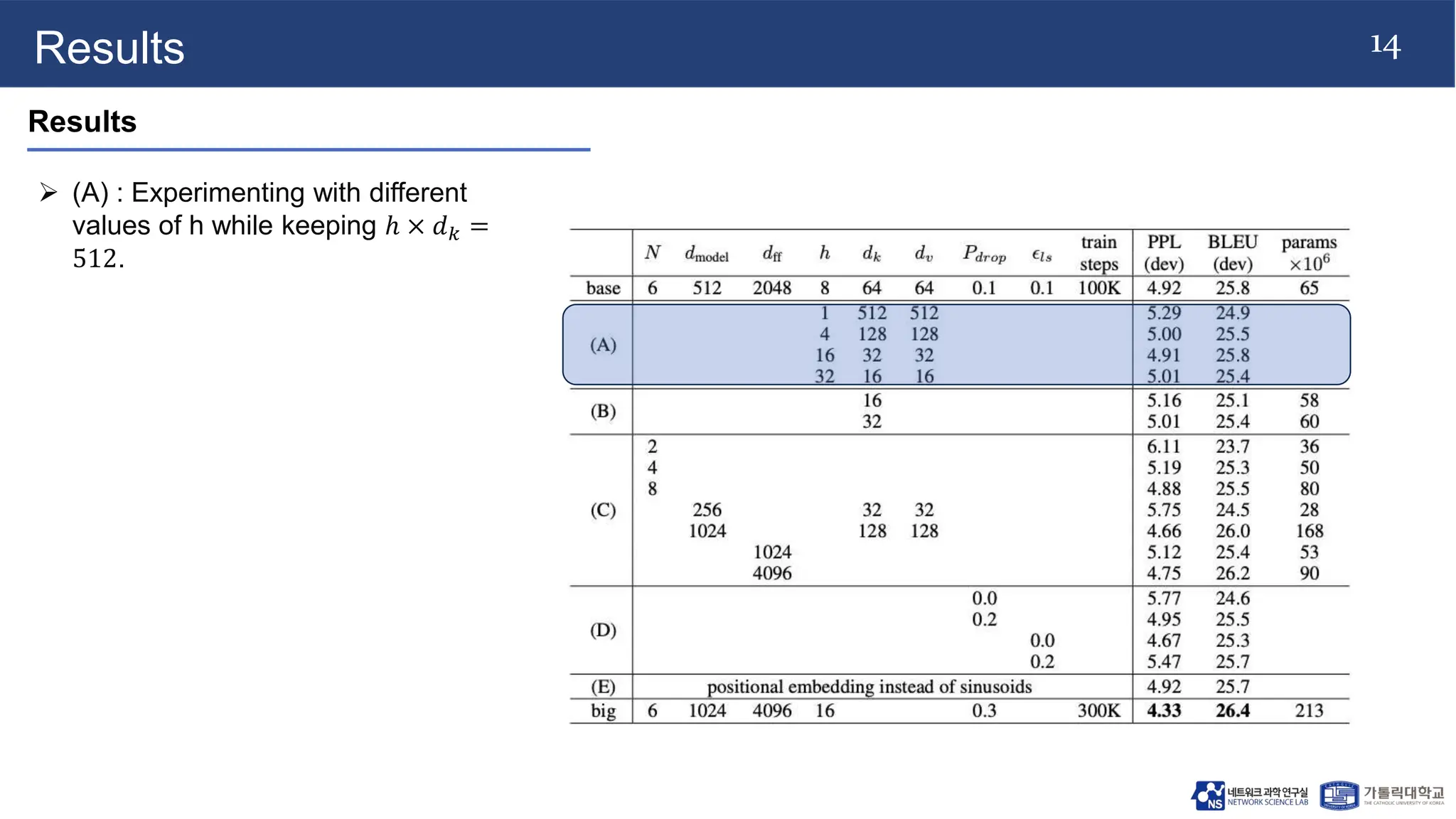
This document describes the Transformer, a novel neural network architecture based solely on attention mechanisms rather than recurrent or convolutional layers. The Transformer uses stacked encoder and decoder blocks with multi-head self-attention and feed-forward layers to achieve state-of-the-art results in machine translation tasks. Key aspects of the Transformer include multi-head attention to jointly attend to information from different representation subspaces, positional encoding to embed positional information, and an attention mask to prevent positions from attending to subsequent positions. The Transformer achieves superior performance compared to RNN-based models on translation benchmarks, with fewer parameters and computation that can be fully parallelized.





















![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[NS][Lab_Seminar_251110]ControlMLLM.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar251110controlmllm-251110090012-39bbf00d-thumbnail.jpg?width=640&height=640&fit=bounds)

![251103_Thanh_LabSeminar[One Last Attention for Your Vision-Language Model].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251103thanhlabseminarrada-251103113308-f66fee0b-thumbnail.jpg?width=640&height=640&fit=bounds)

![251124_Thanh_LabSeminar[Hyper-YOLO].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251124thanhlabseminarhyper-yolo-251124113258-535062b4-thumbnail.jpg?width=640&height=640&fit=bounds)


![251124_HW_LabSeminar[Multimodal-SCM].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251124hwlabseminarmultimodal-scm-251124113300-6fad72e4-thumbnail.jpg?width=640&height=640&fit=bounds)

![251124_Thuy_Labseminar[Vision GNN: An Image is Worth Graph of Nodes].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251124thuylabseminar-251124113257-025487fe-thumbnail.jpg?width=640&height=640&fit=bounds)
![251103_SH_LabSeminar[Expressiveness of Graph Neural Networks].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251103shlabseminarppgn-251103113317-1094e696-thumbnail.jpg?width=640&height=640&fit=bounds)
![251103_Thuy_Labseminar[Grounded Language-Image Pre-training].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251103thuylabseminar-251103113311-941d56eb-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NS][Lab_Seminar_251201]High-Precision Mixed Feature Fusion Network Using Hyp...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar251201mlf-snet-251206120538-22fa2497-thumbnail.jpg?width=640&height=640&fit=bounds)

![251110_HW_LabSeminar[WHAT TO ALIGN IN MULTIMODAL CONTRASTIVE LEARNING?].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251110hwlabseminarcomm-251110103747-14b1b798-thumbnail.jpg?width=640&height=640&fit=bounds)





















