Downloaded 40 times

















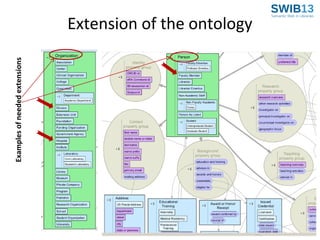
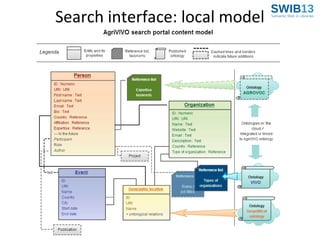
![Extension of the ontology
Examples of needed extensions
Organization
Person and education
Academy
Agricultural researcher
NGO
Farmer
Farmers Organization
Extension / communication agent
International Organization
Policy maker
Position
[Positions] Revise?
Sub-sub-class
Agricultural research
Institute
Sub-sub-class
Agricultural research
center
Senior Officer
Administrative staff
Information manager](https://image.slidesharecdn.com/agrivivo-swib-131126054202-phpapp02/85/AgriVIVO-A-Global-Ontology-Driven-RDF-Store-Based-on-a-Distributed-Architecture-SWIB-Conference-2013-27-320.jpg)






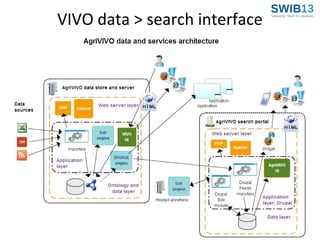






![Getting data re-used
• VIVO’s search functionalities can be integrated in other websites through
remote calls. In this way, specialized and targeted search engines can give
access to and offer highly customized “views” of the data coming from
AgriVIVO
Publication1 > Is about > Topic1
Publication2 > Is about > Topic1
Publication3 > Is about > Topic1
Person1 > Expertise > Topic1
Person2> Expertise > Topic1
Person3> Author of > Publication1
Person4 > Author of > Publication2
[...]](https://image.slidesharecdn.com/agrivivo-swib-131126054202-phpapp02/85/AgriVIVO-A-Global-Ontology-Driven-RDF-Store-Based-on-a-Distributed-Architecture-SWIB-Conference-2013-49-320.jpg)
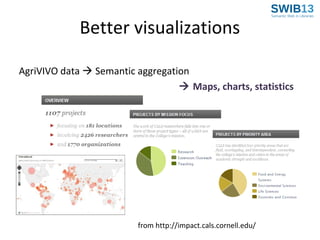


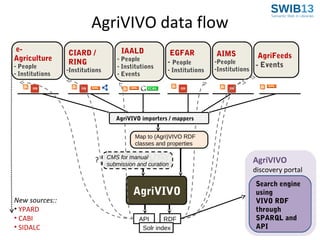
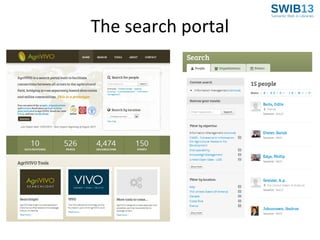
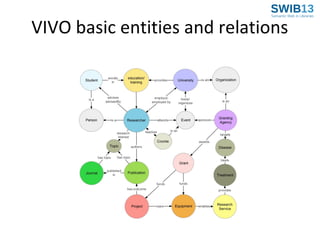
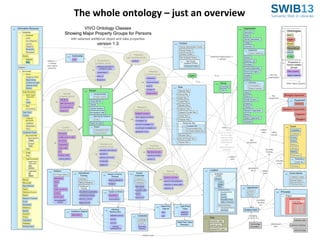
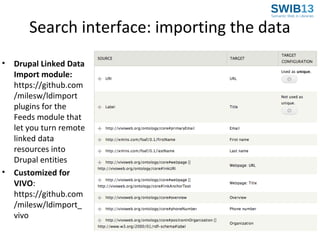
The document discusses the development of Agrivivo, an ontology-driven RDF store designed to facilitate research collaboration in the agricultural sector by aggregating data from various sources. Agrivivo, built upon the VIVO platform, aims to connect researchers, institutions, and relevant projects globally, while providing a customizable search interface and integrated data management tools. Future plans include enhancing data curation, integrating publication data, and improving support for multilingual content.




































































































