
Download to read offline












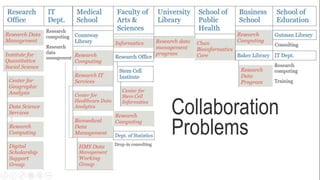

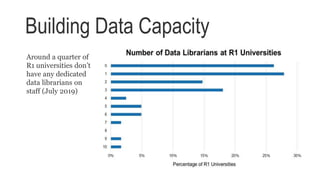
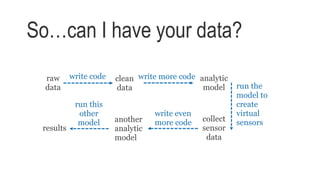


The document discusses the landscape of research data services and identifies three models for data sharing: institution driven, compliance driven, and community driven. It highlights the strengths and weaknesses of each model and emphasizes the need for collaboration and innovative thinking to address challenges in research data management. Finally, it calls for an engagement-focused approach to improve data support for researchers.























































































