Download to read offline




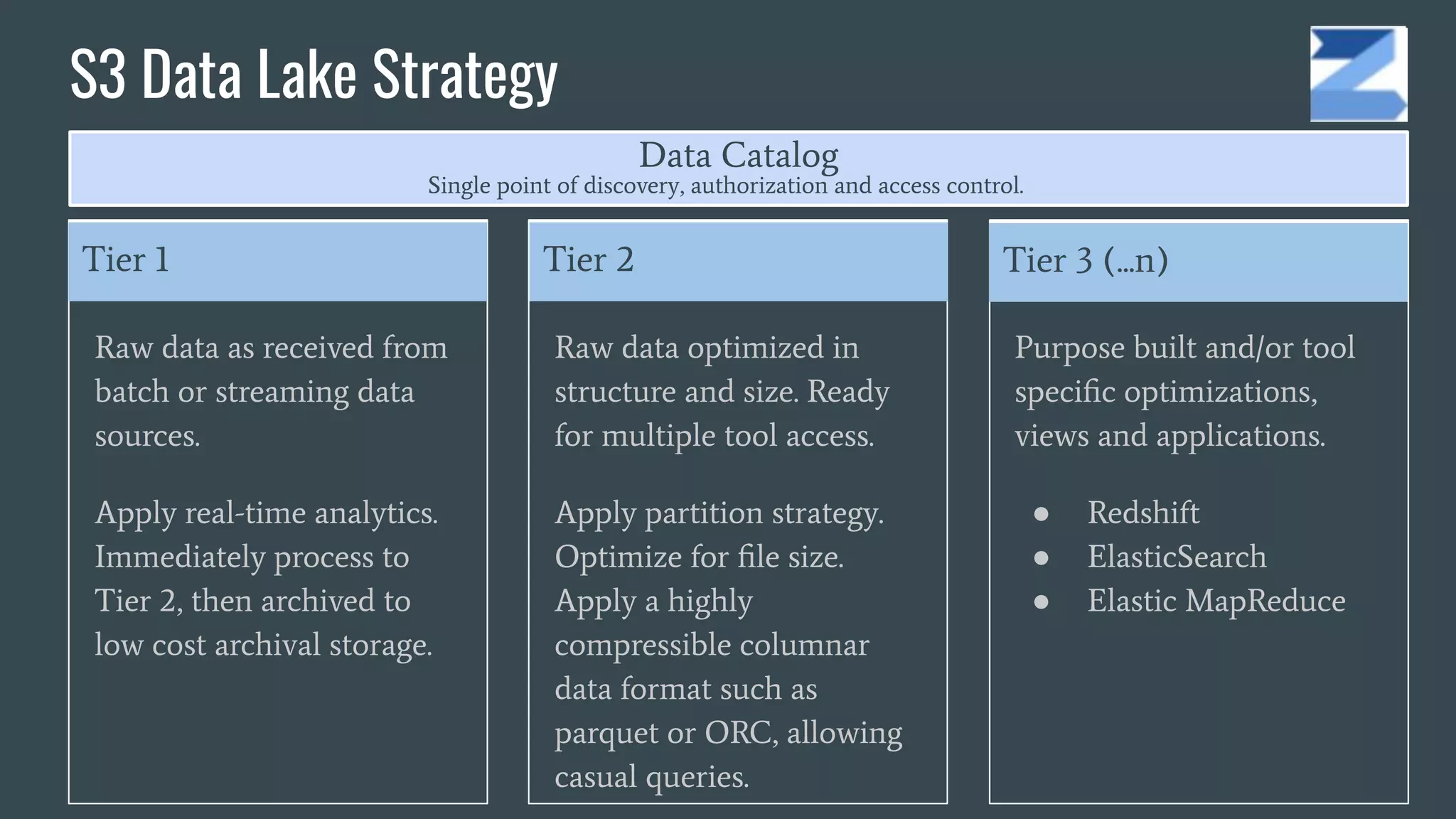
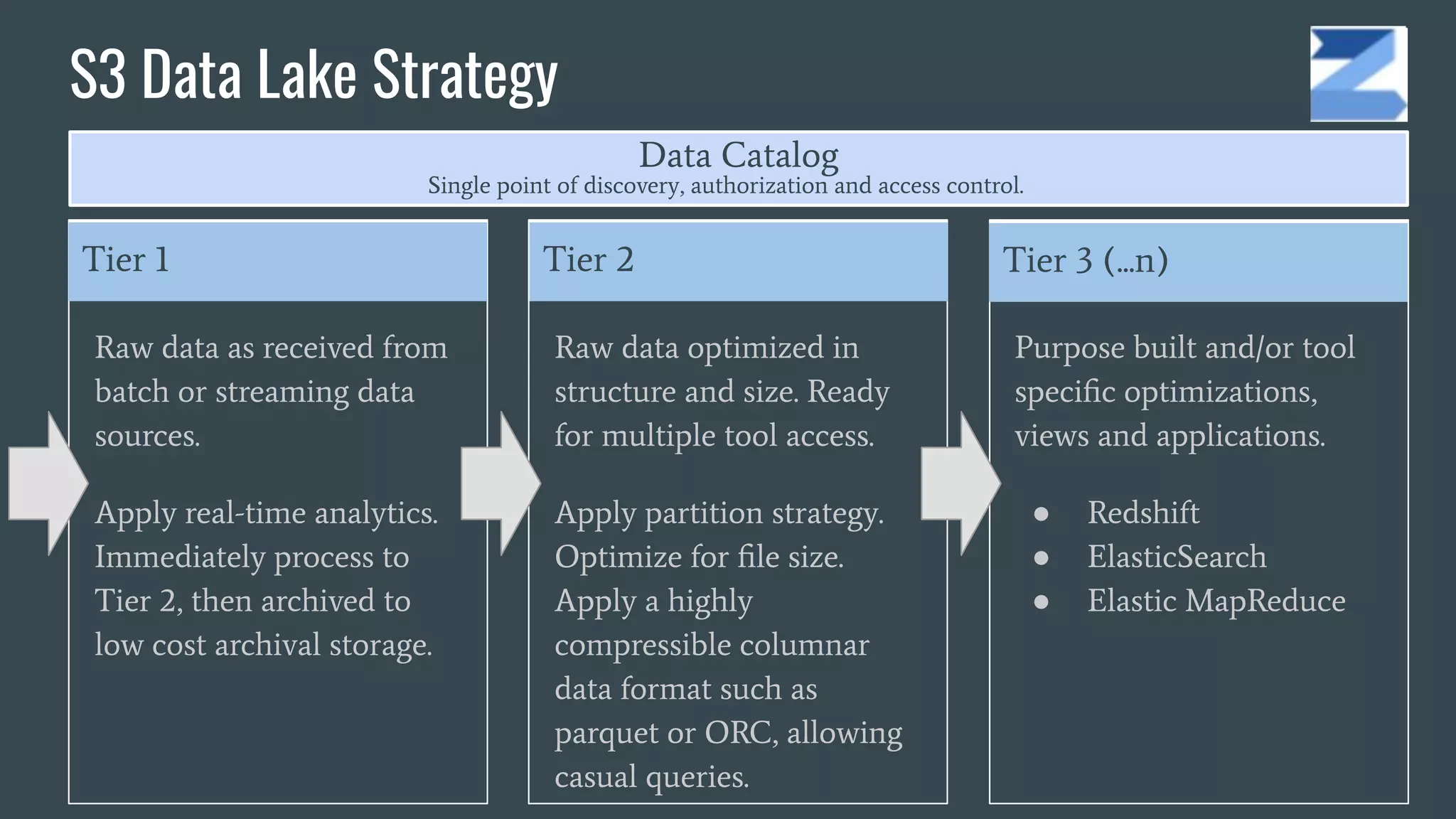
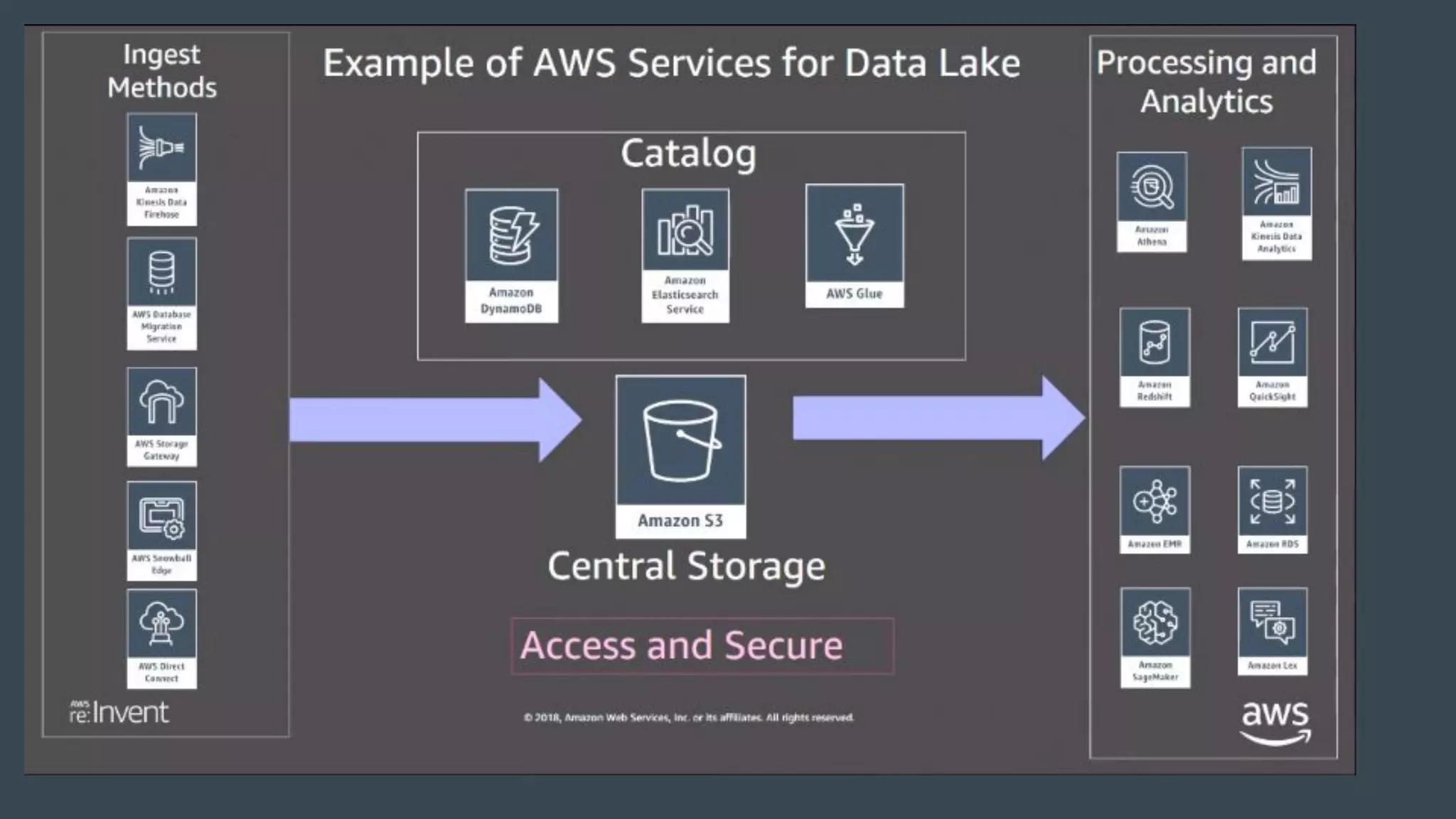





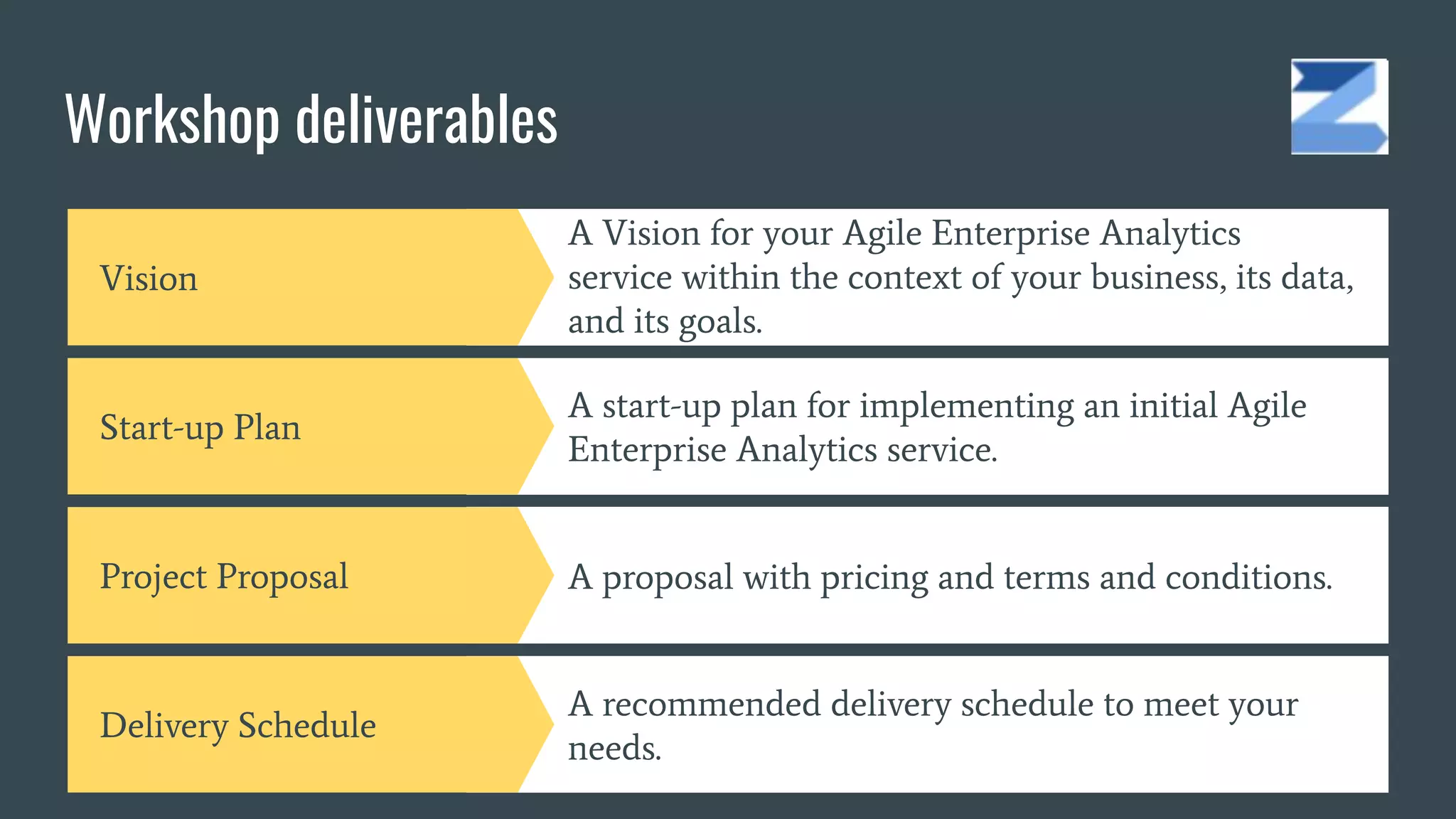



The document discusses the challenges and opportunities in managing enterprise data through agile analytics on AWS. It emphasizes the importance of establishing data lakes for effective data governance, access, and analytics, while leveraging open data formats and tools. Additionally, it provides a strategic framework for implementing a data-driven organization that facilitates evidence-based decision making and encourages the use of machine learning and AI.




















































![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
