Download as PDF, PPTX





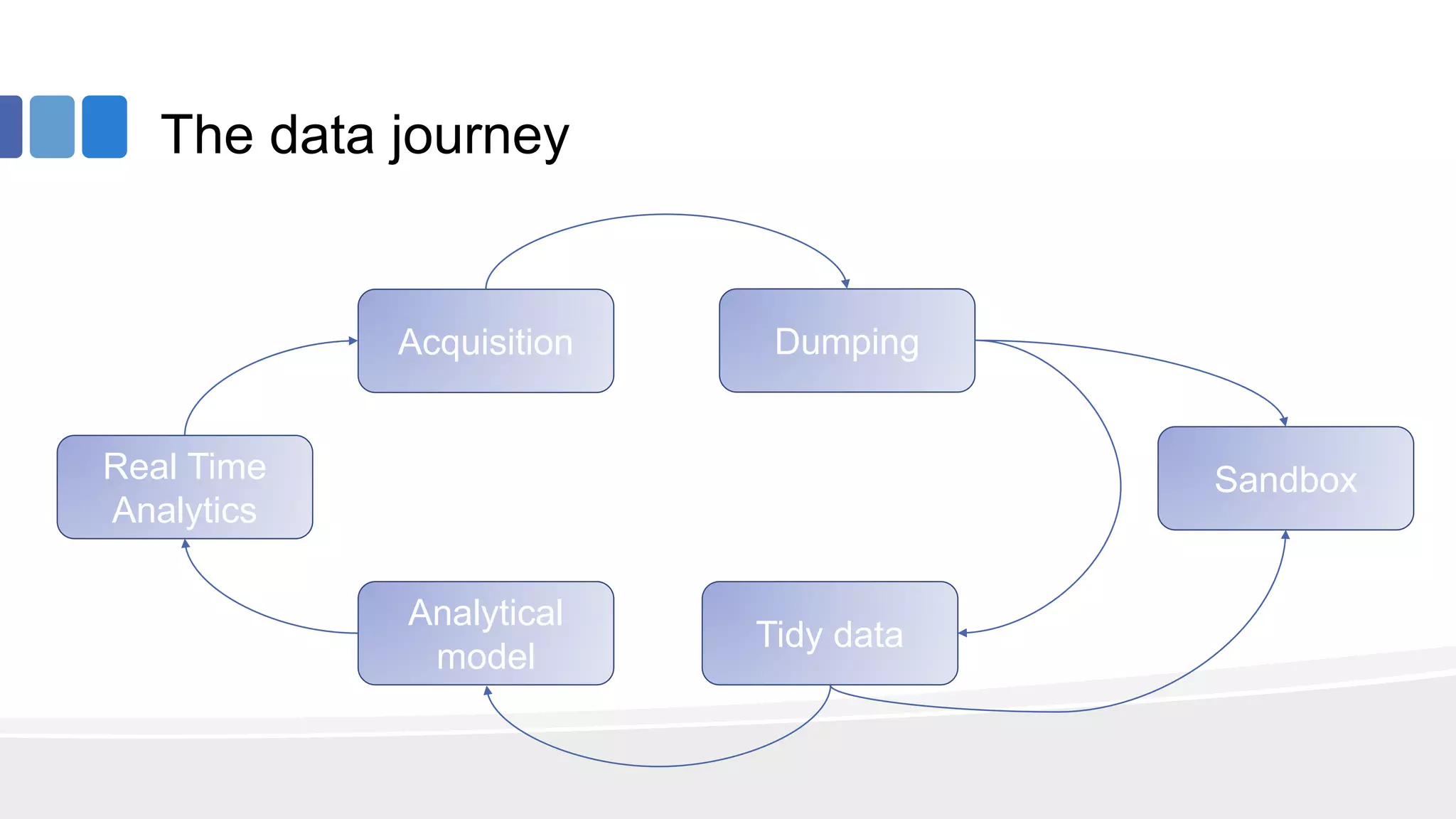
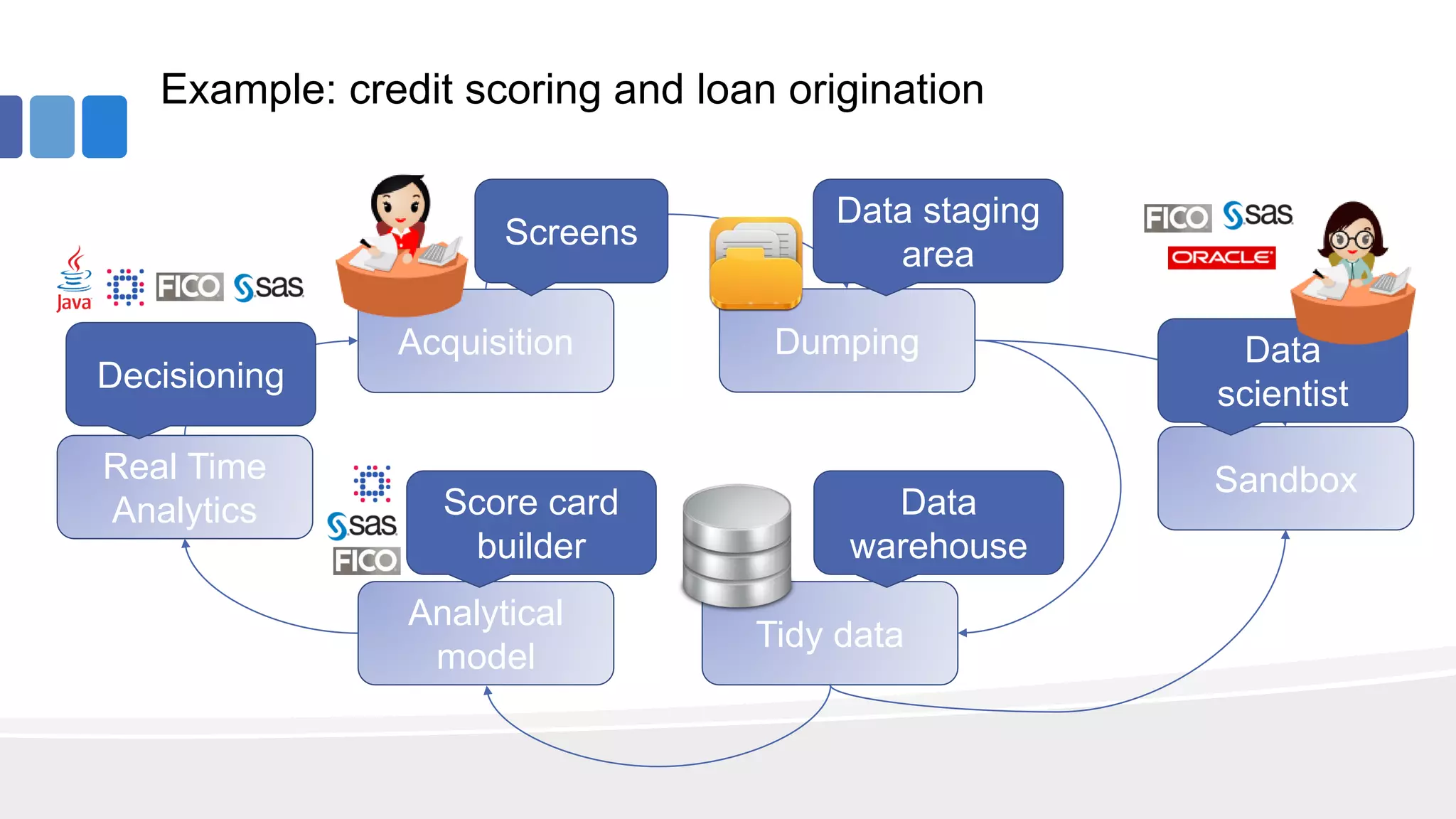

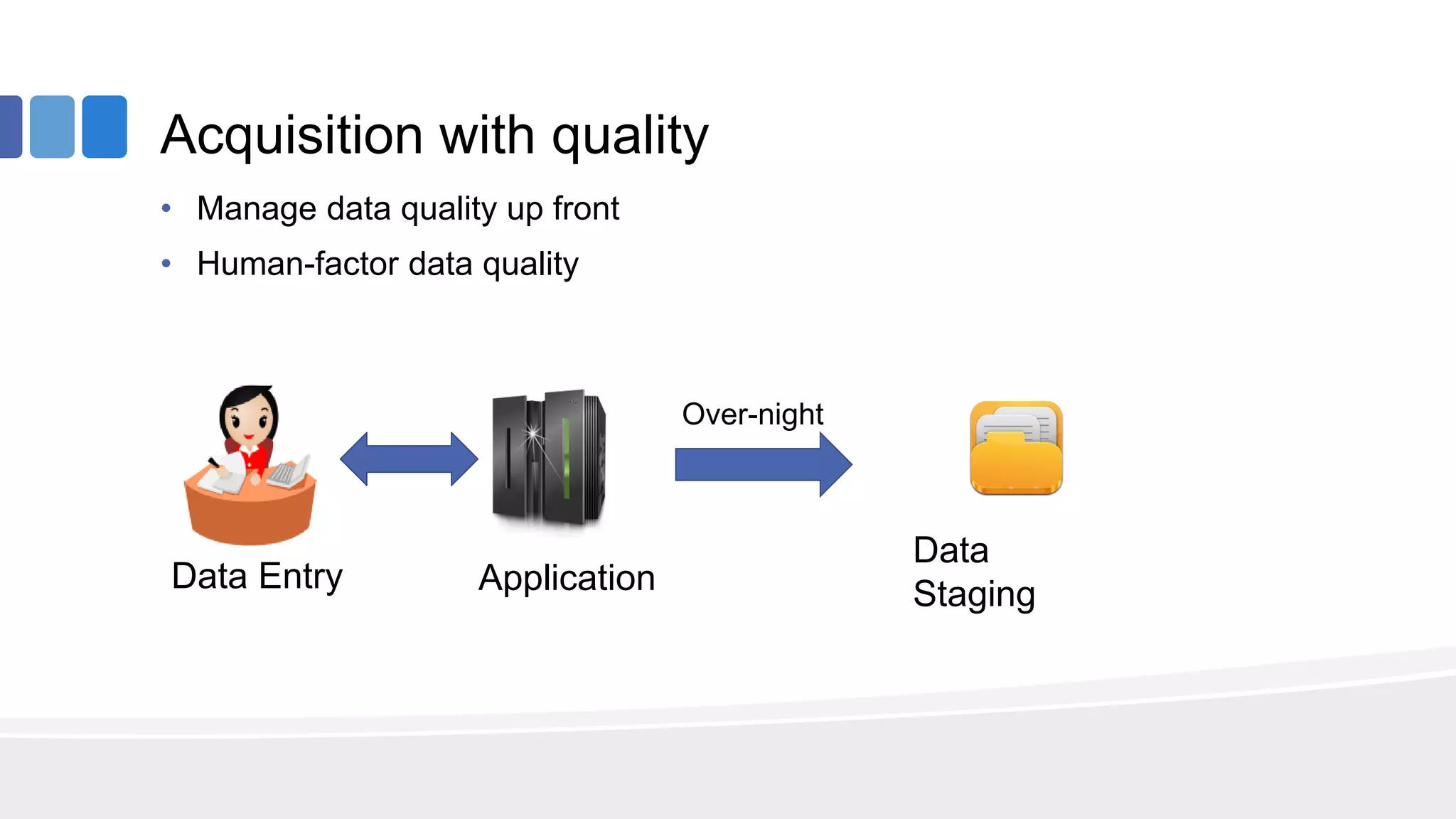
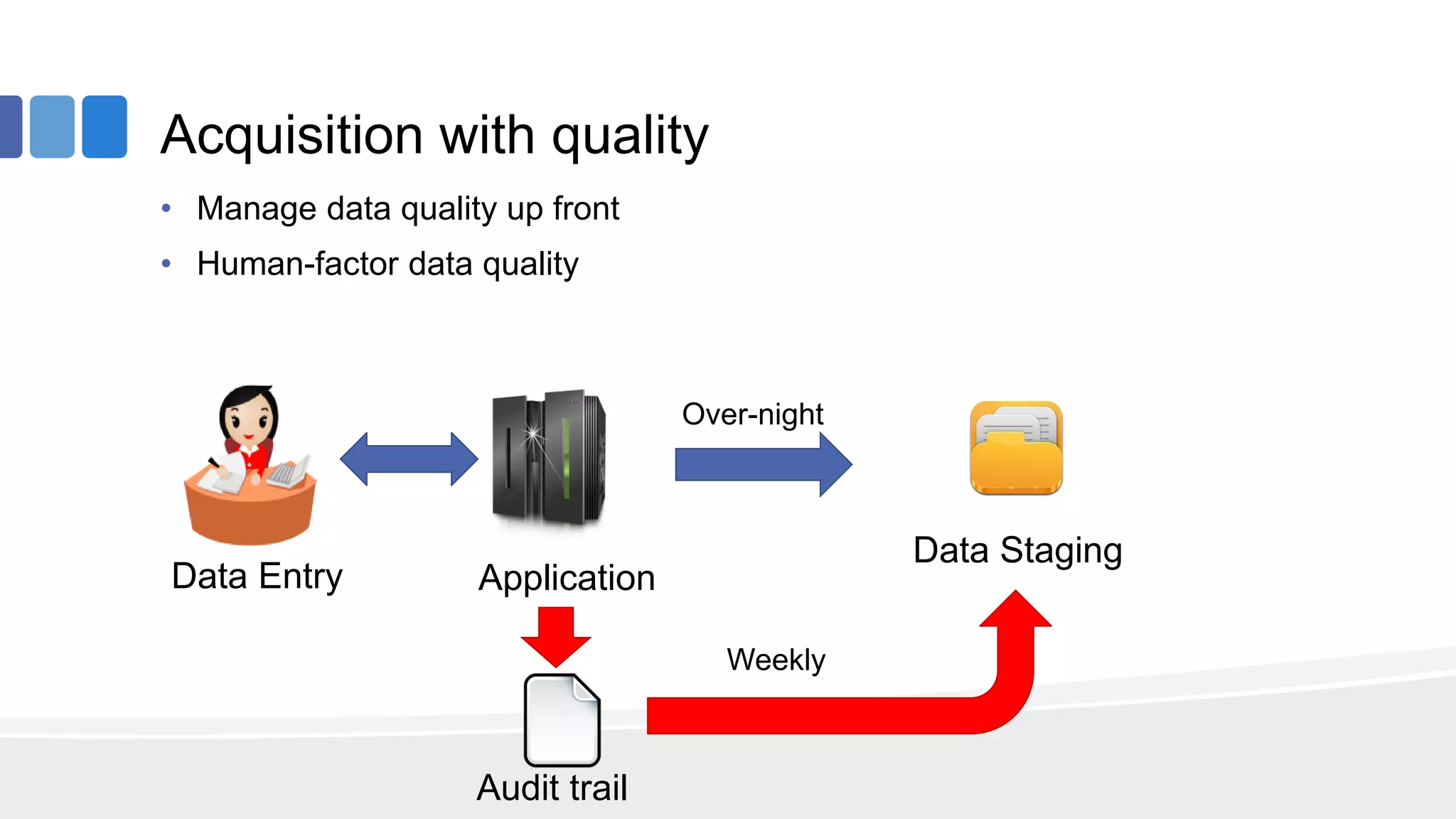
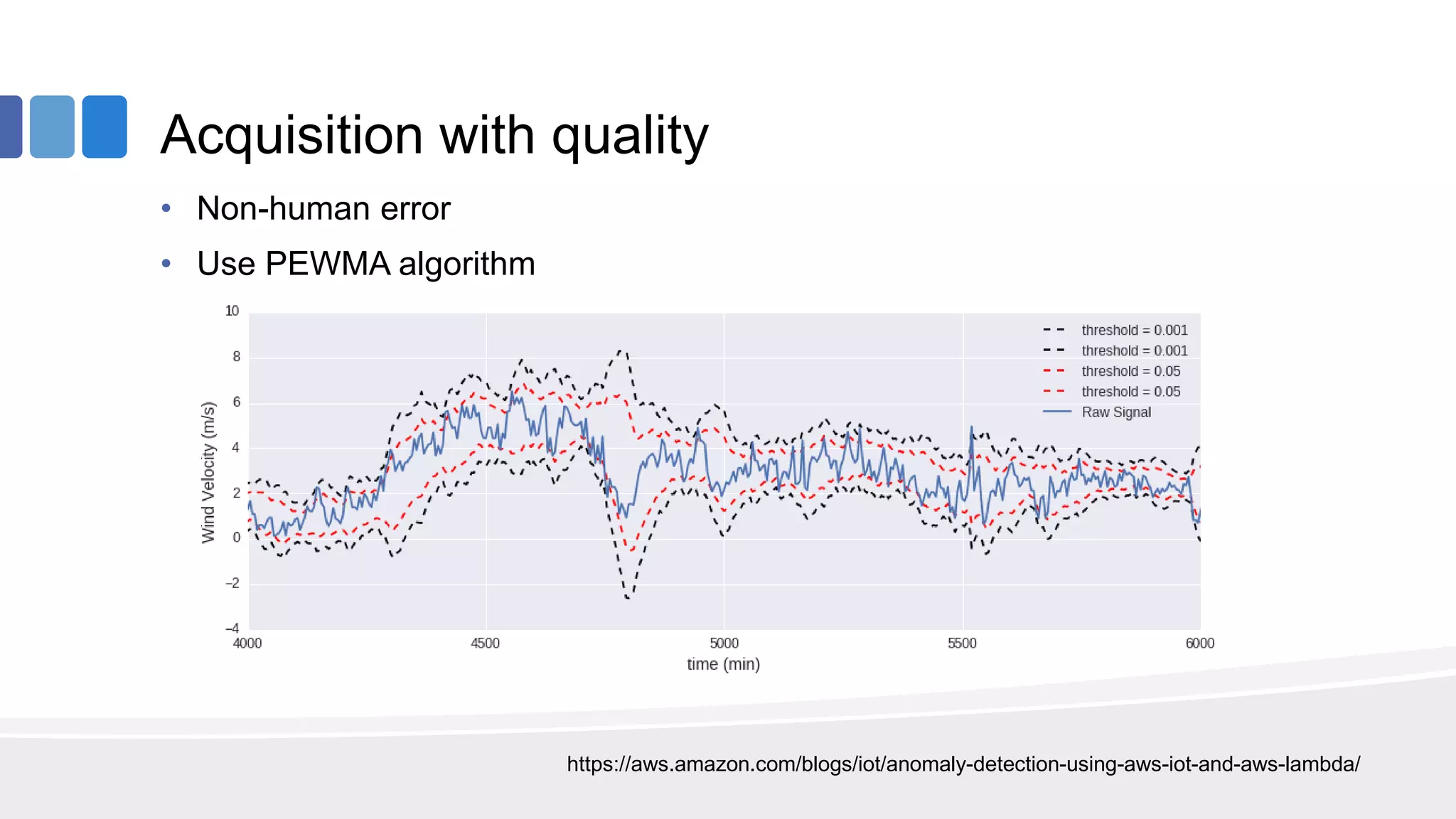






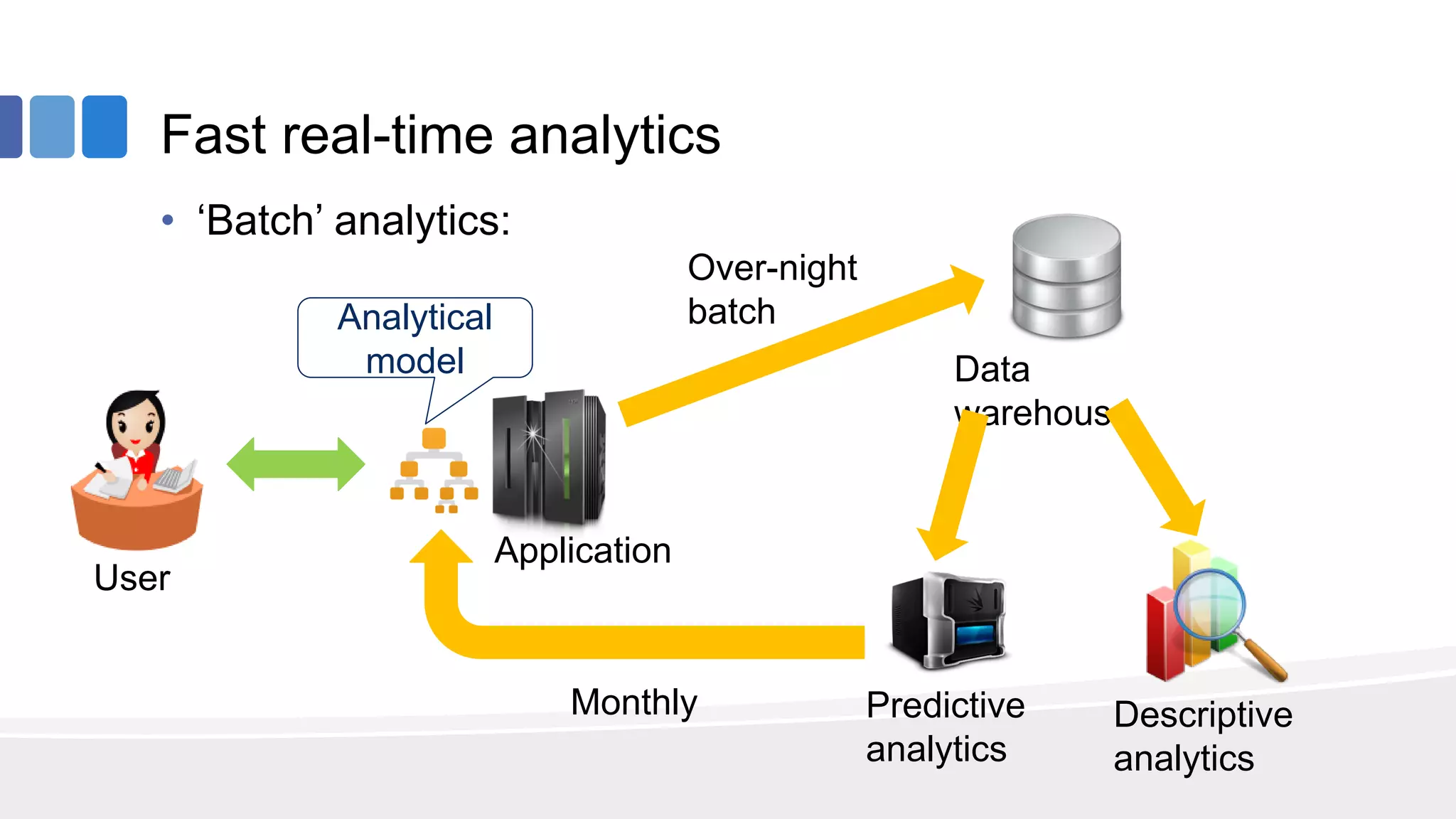
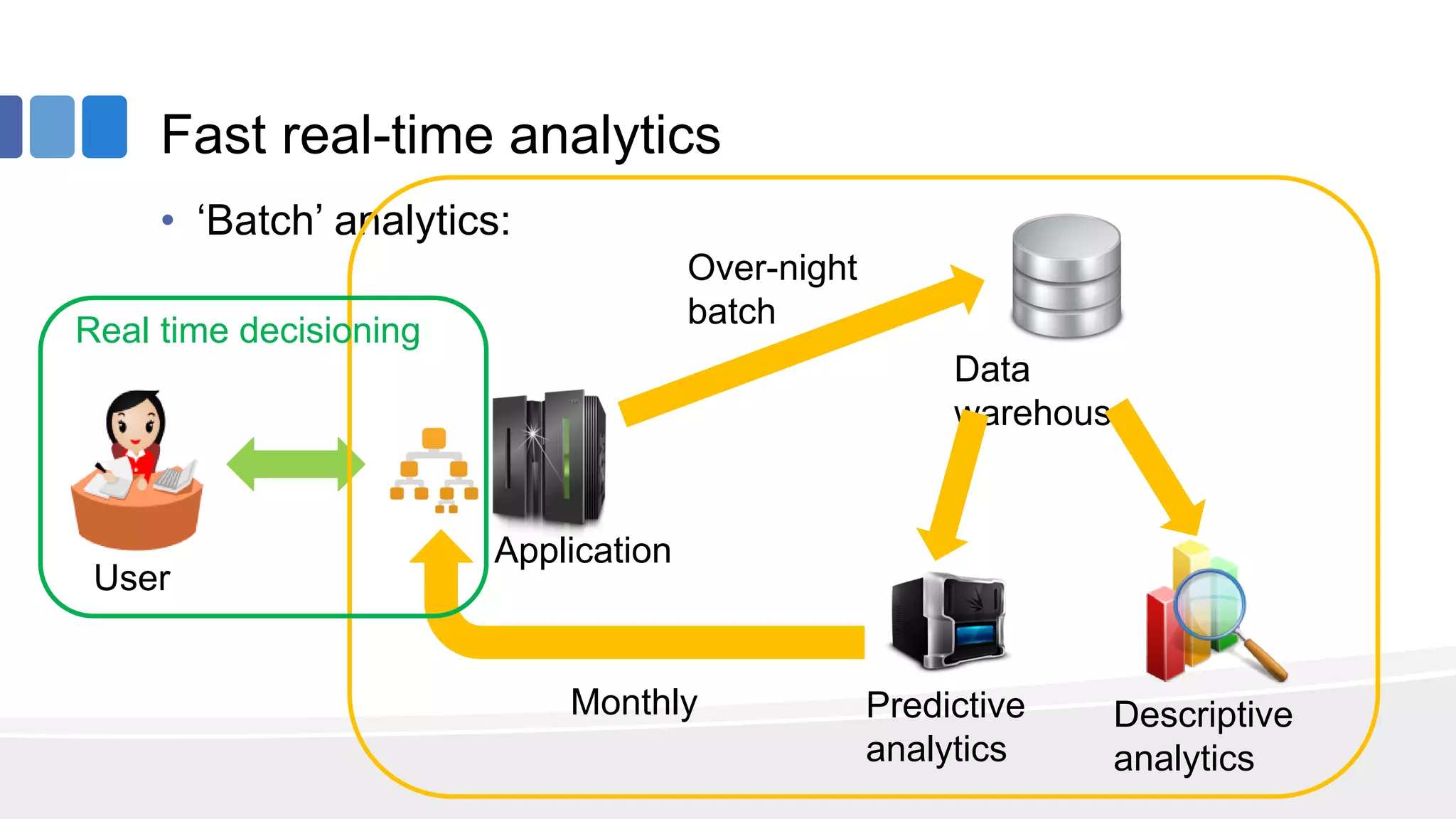
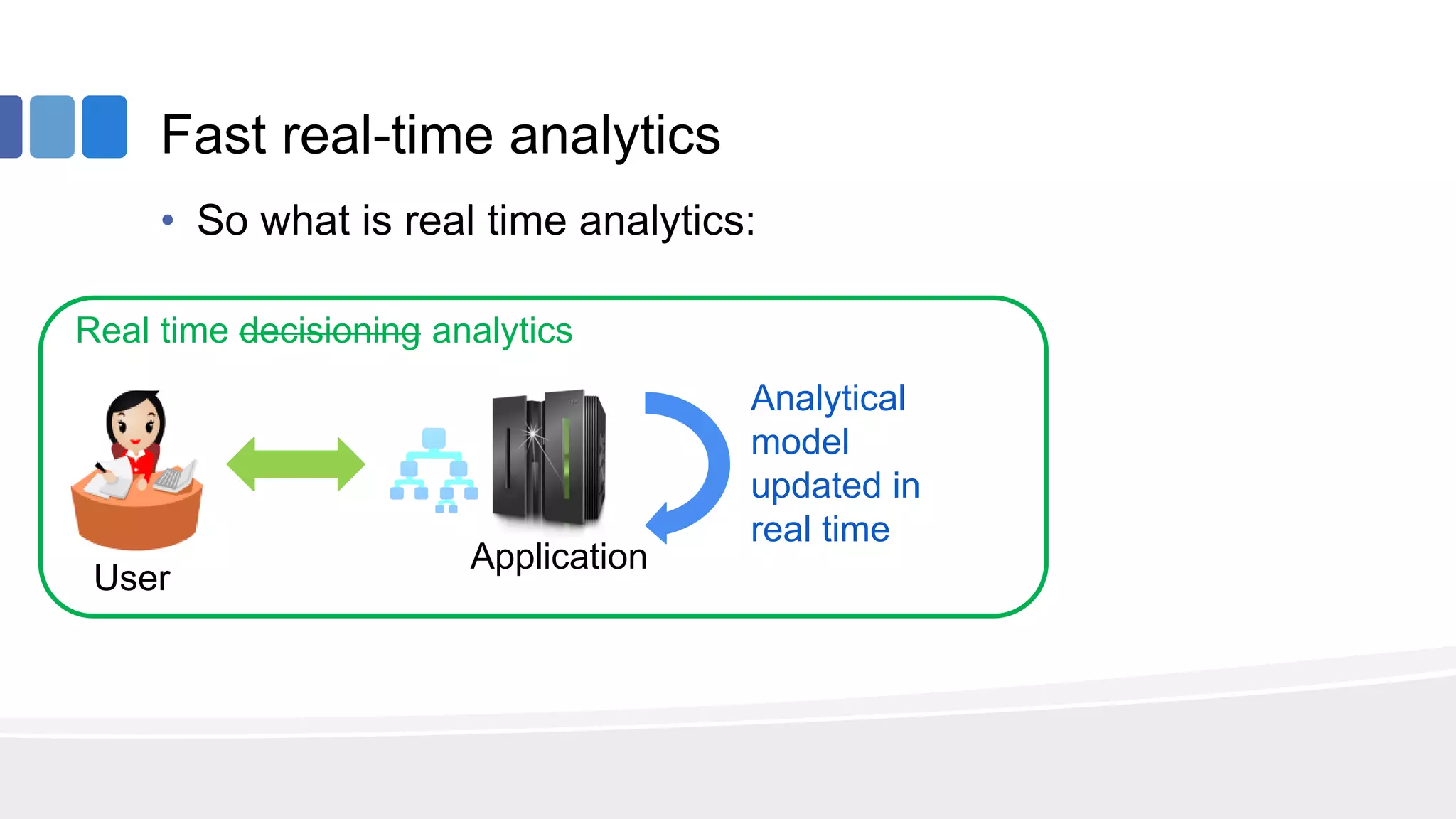
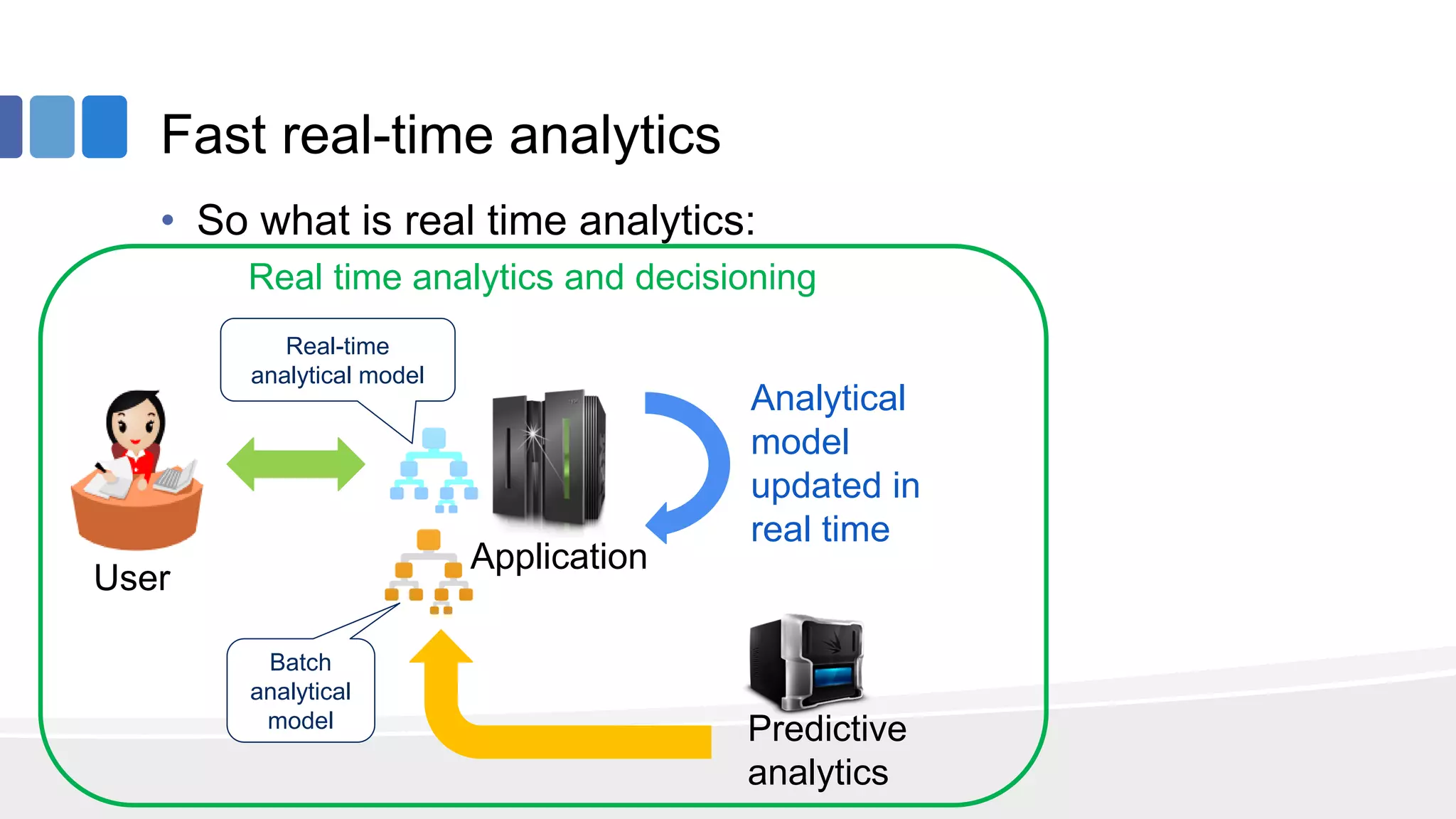
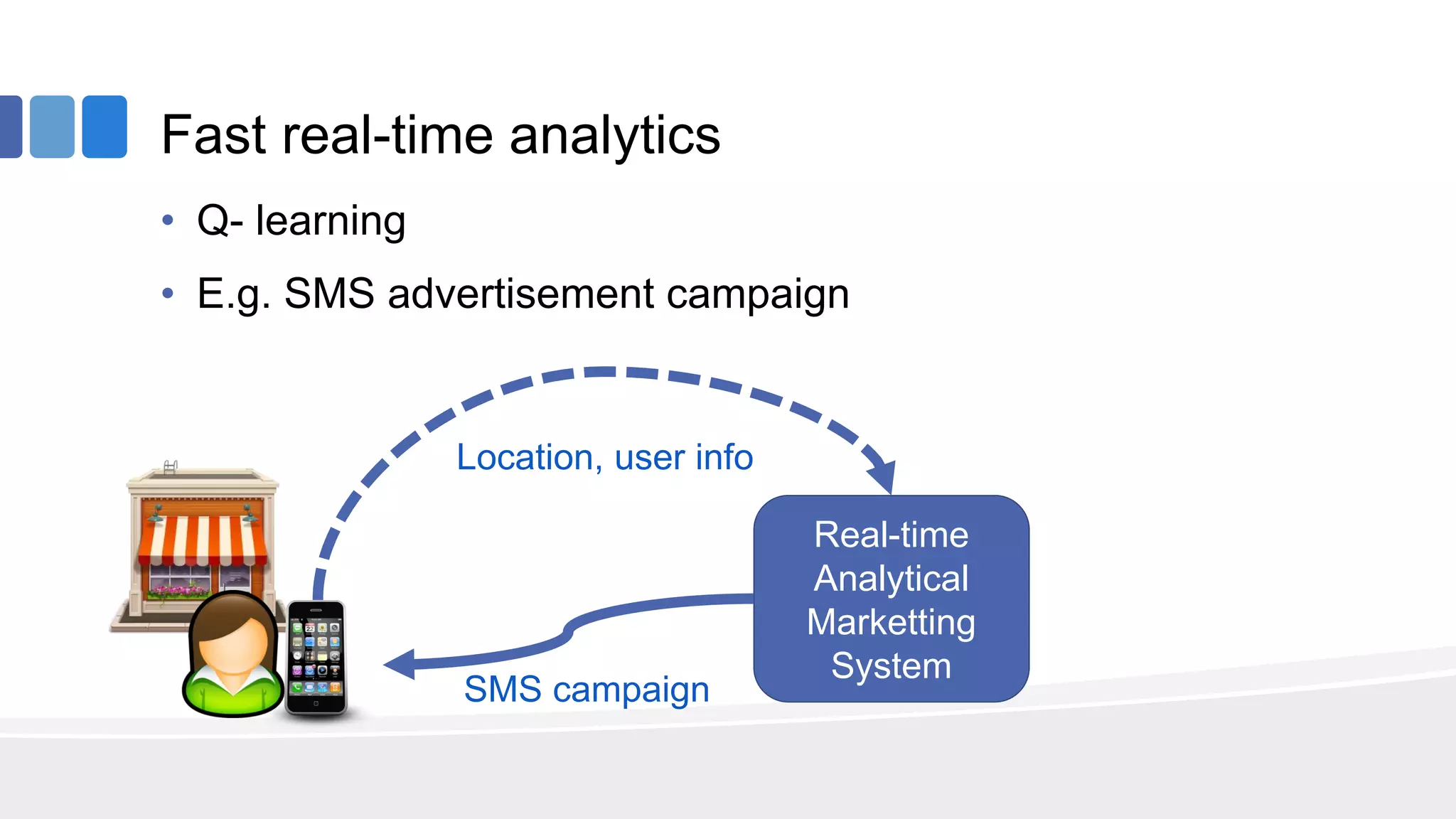
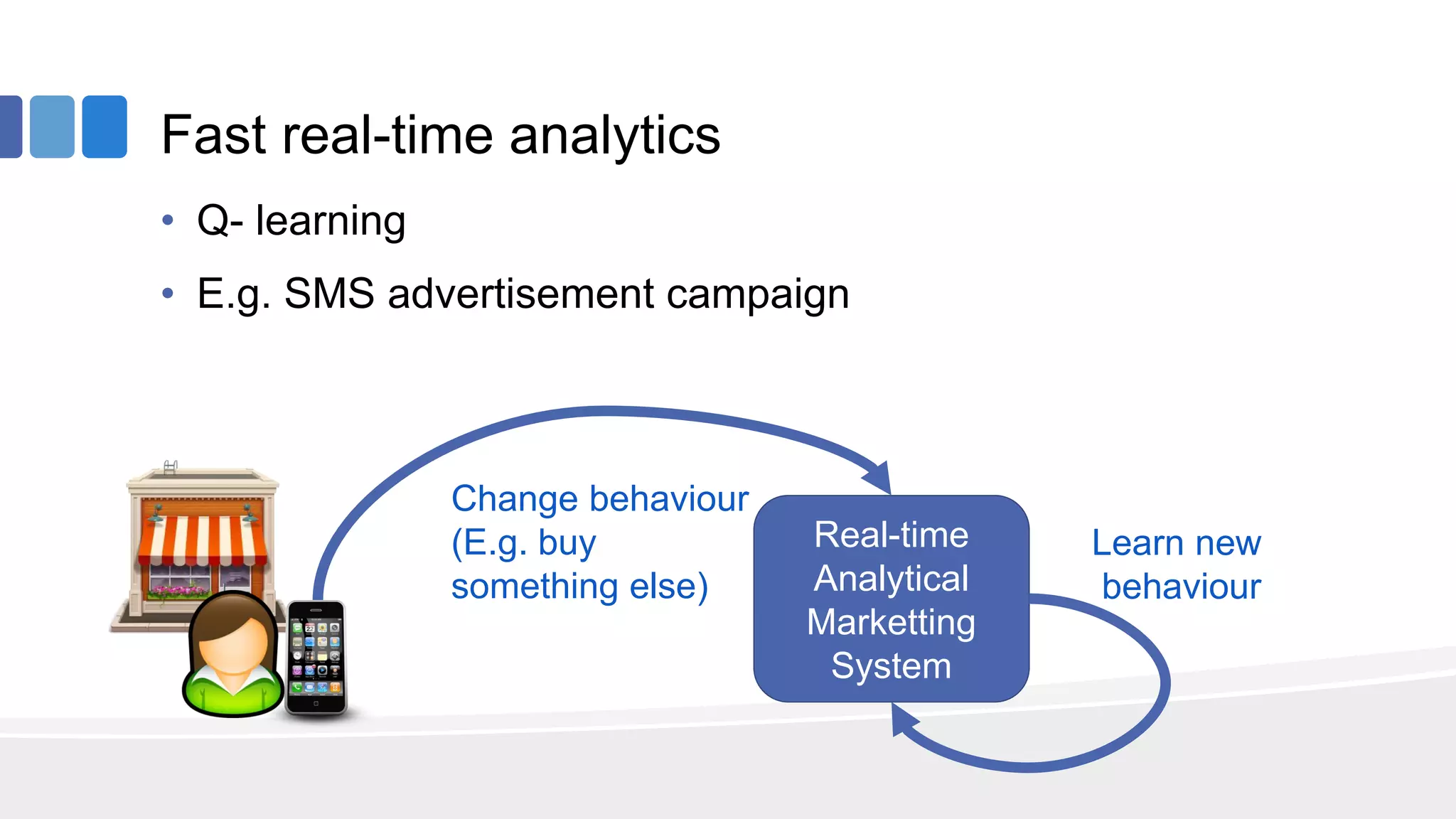
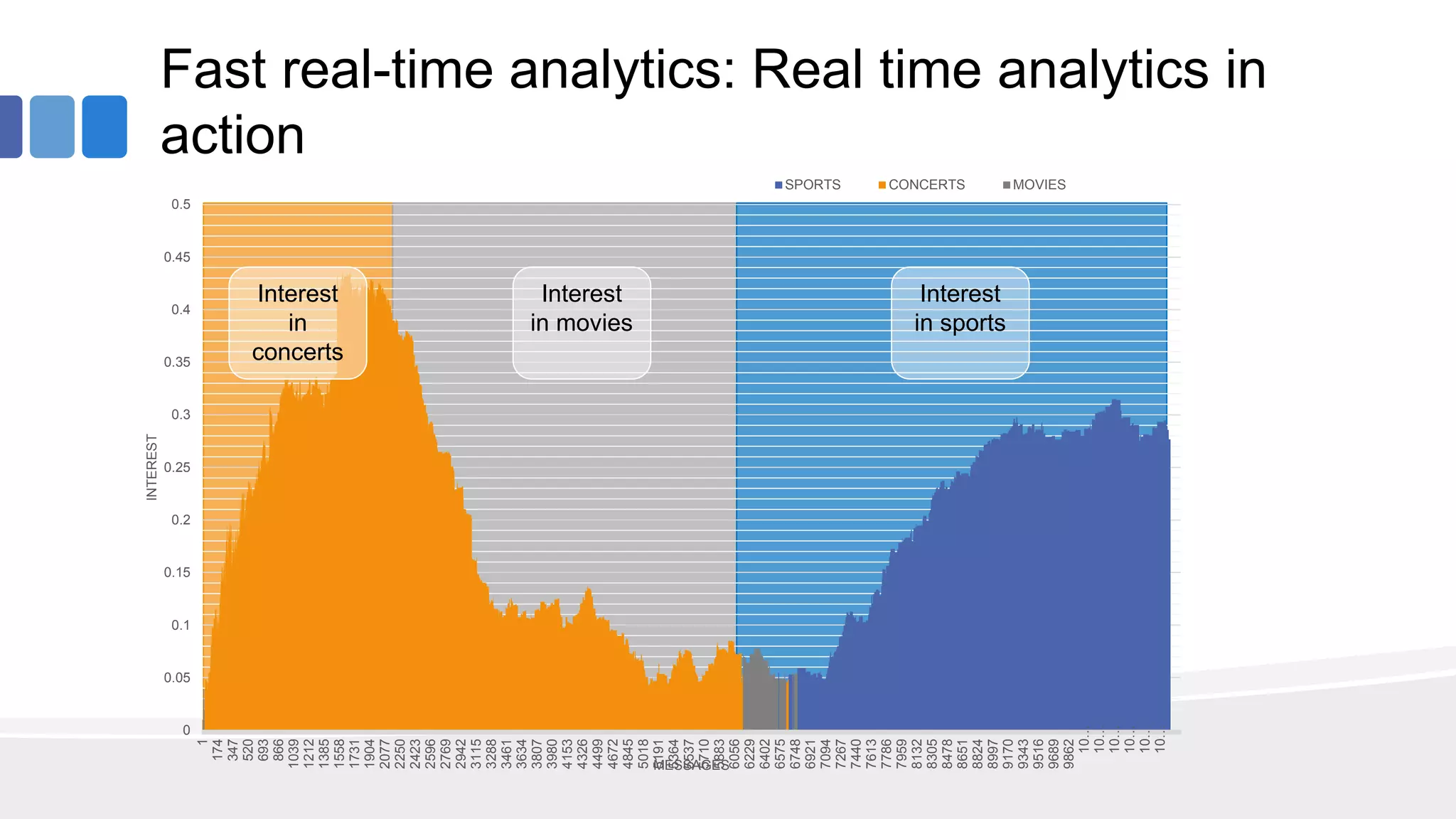
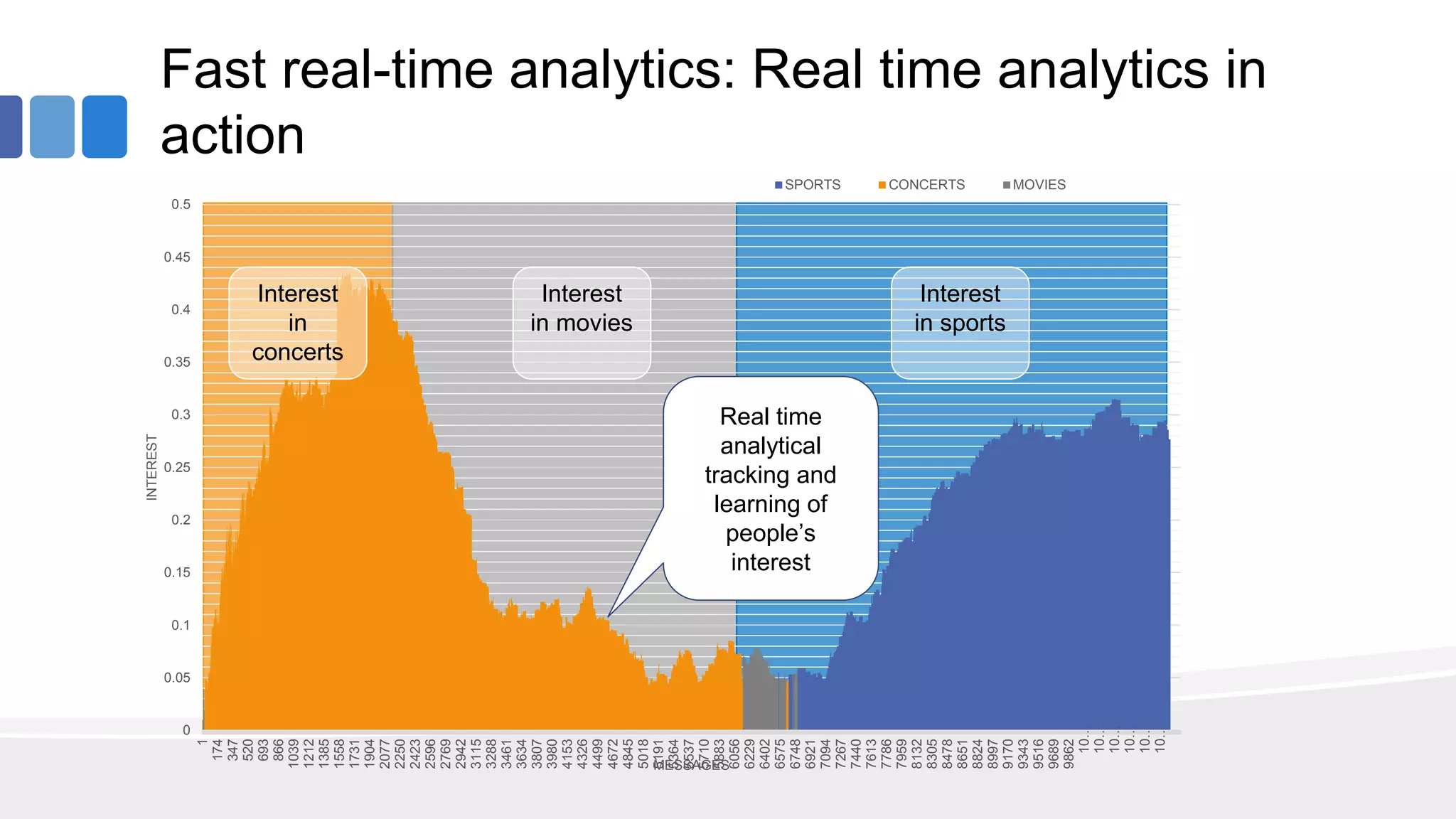


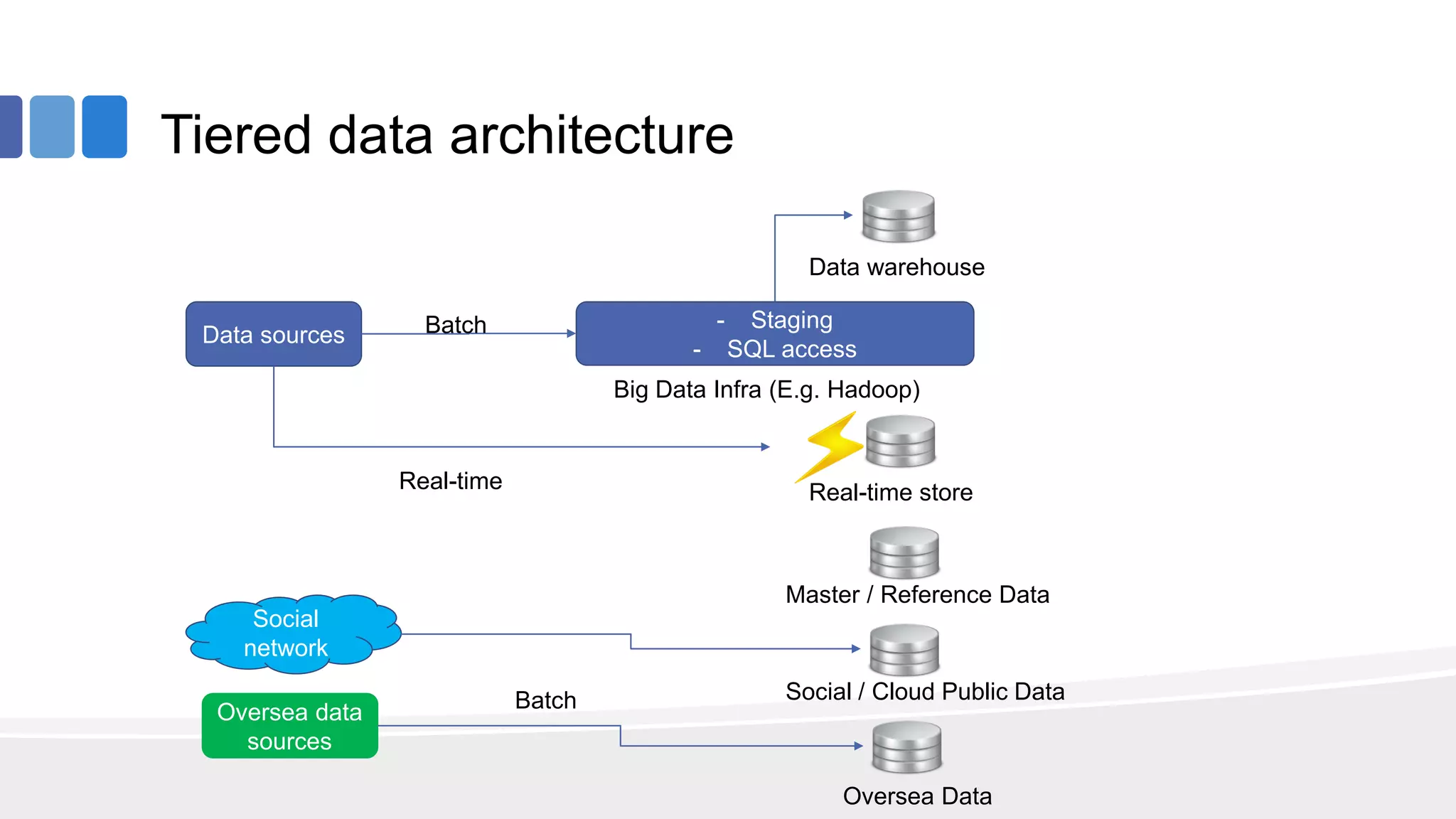
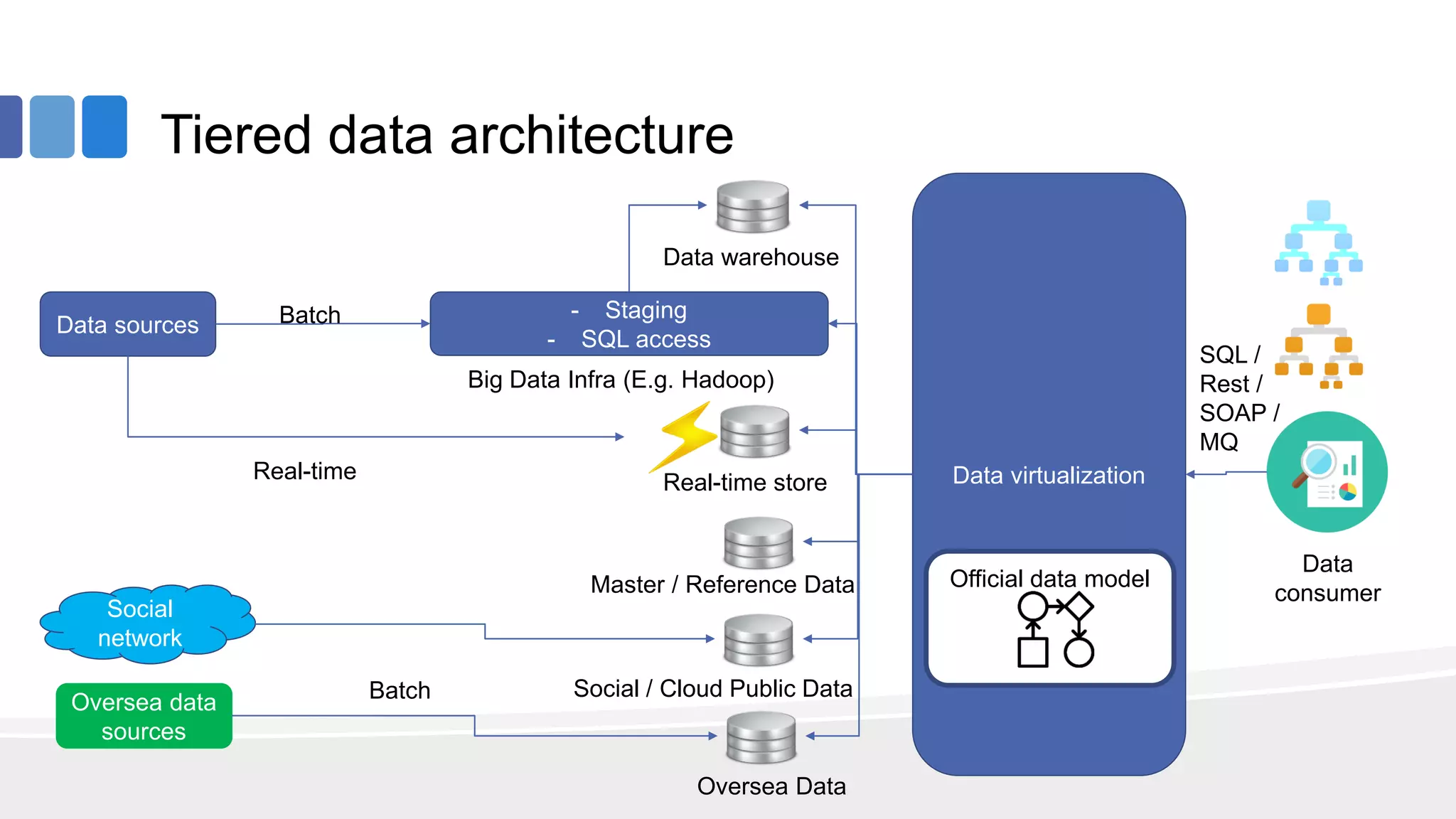




This document provides an overview of big data concepts from the perspective of an enterprise data architect. It discusses the data journey from acquisition to analytics and highlights best practices for data quality, sandboxing data on the cloud, balancing real-time and batch analytics, and putting these concepts together under a tiered data architecture. The architecture proposes investing more in fast data sources and less in cold data, using data virtualization to provide a unified view, and keeping sensitive customer data localized to comply with regulations.

















































![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)



