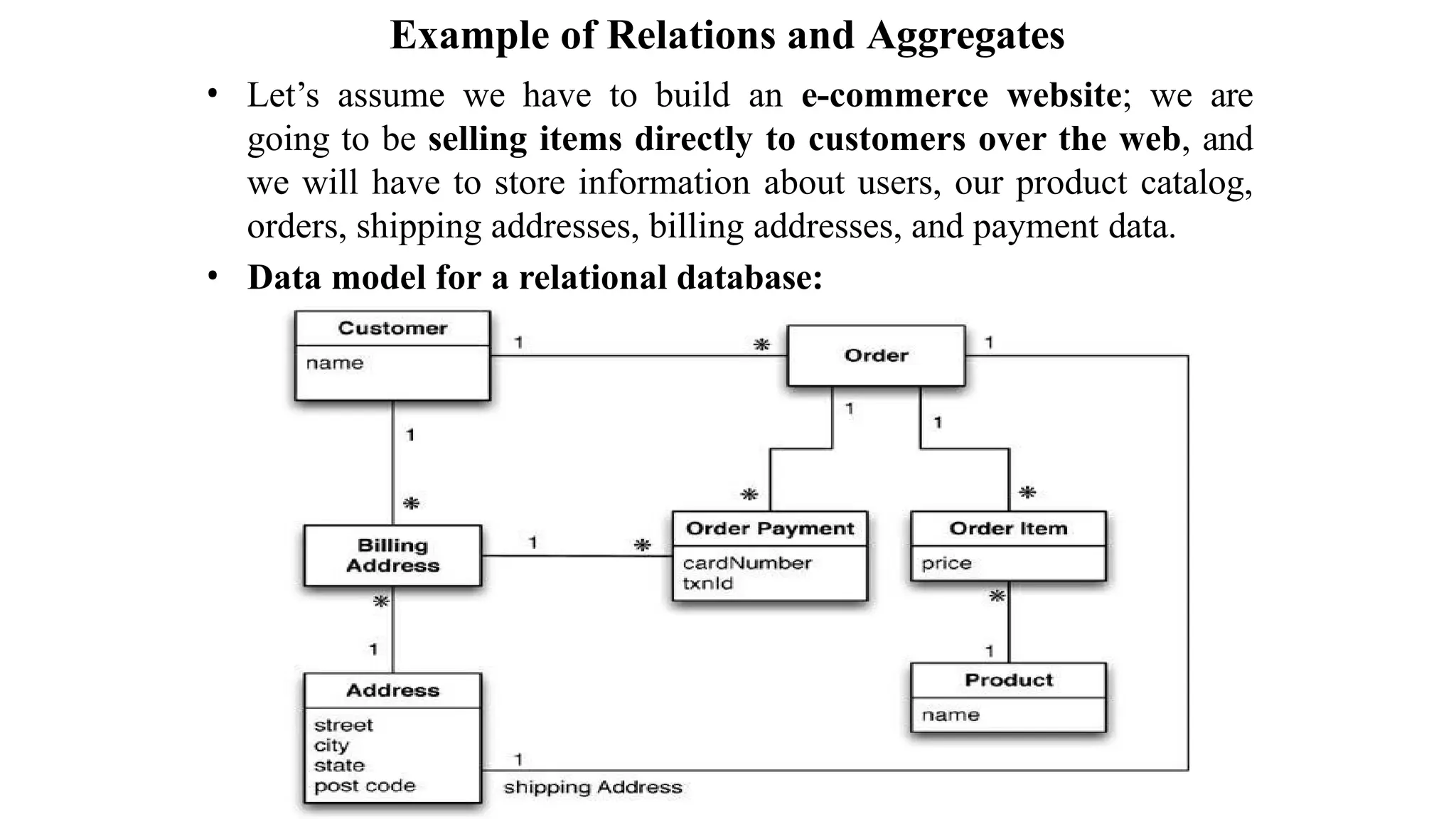
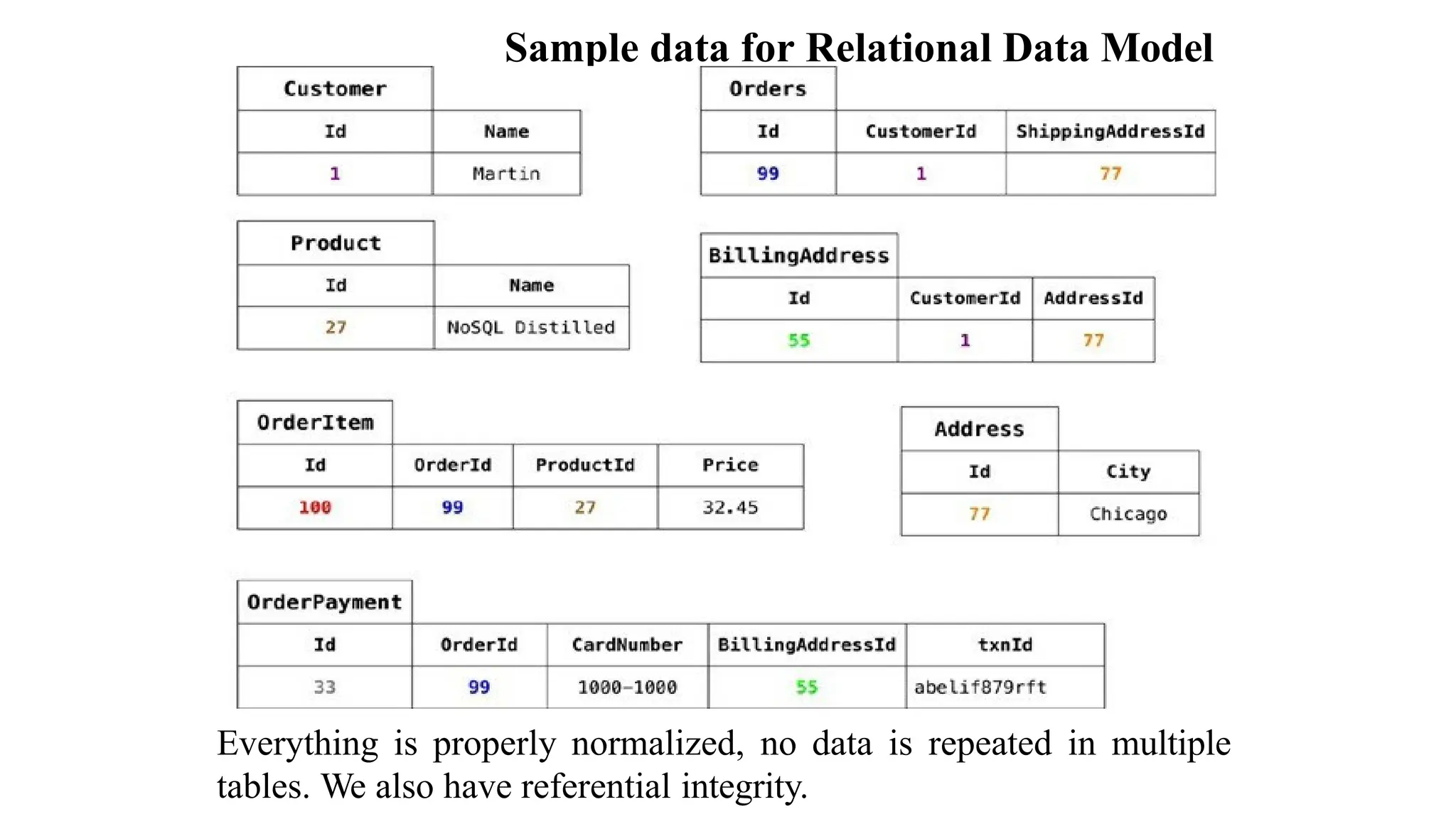
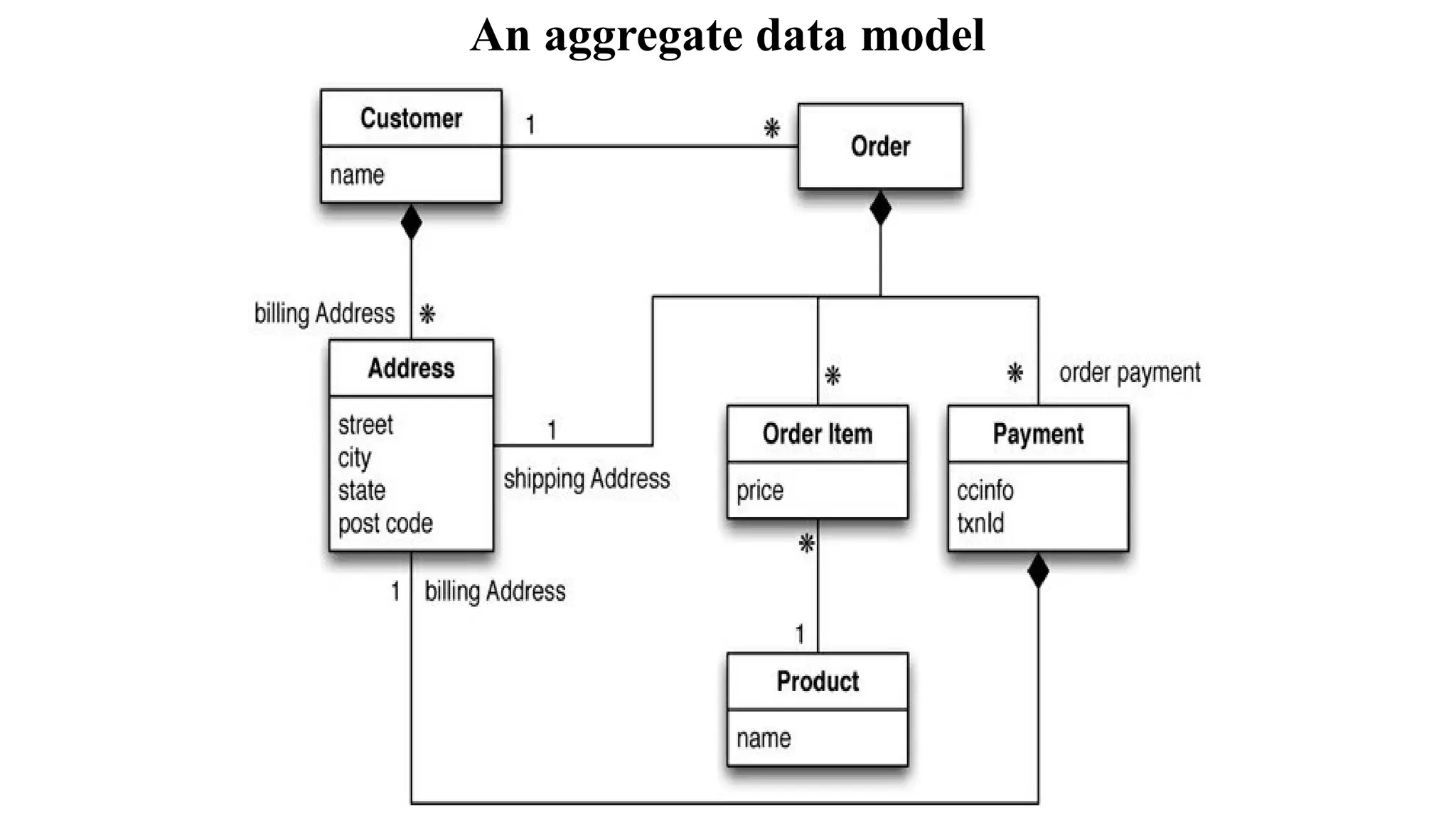
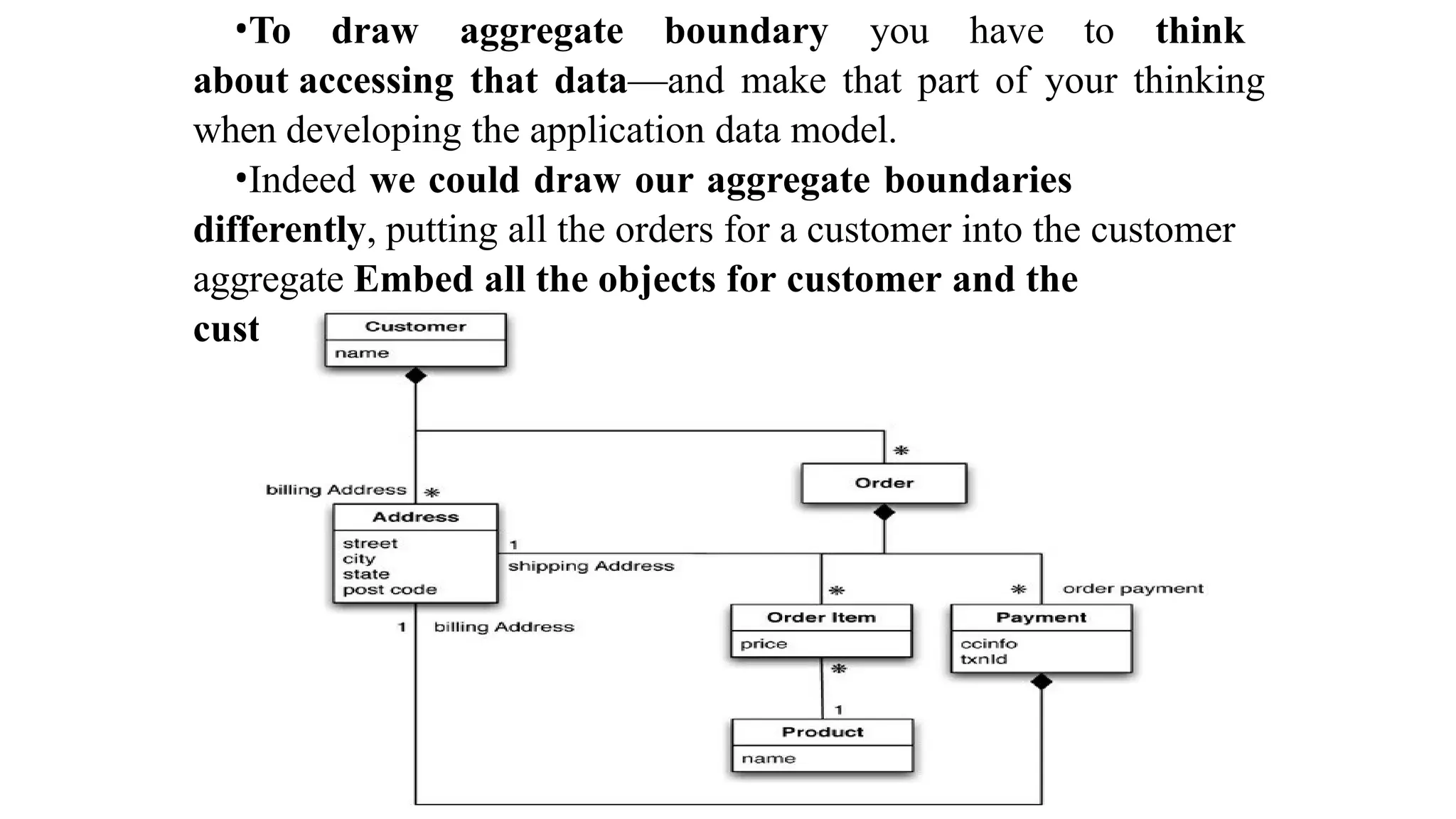
The document discusses different data models, focusing on the differences between relational and NoSQL aggregate data models. It outlines how aggregates, which can contain complex structures like lists and nested records, enable efficient data manipulation and management, particularly in distributed systems. The implications of using aggregates on transactions and data access patterns are also explored, highlighting the trade-offs between aggregate orientation and relational models.




![Sample Data for aggregate data model
// in customers
{
“id":1,
"name":"Martin", "billingAddress":
[{"city":"Chicago"}]
}
// in orders
{ "id":9
9,
"custome
rId":1,
"orderIt
ems":[
{
"productId":27,
"price": 32.45,
"productName":
"NoSQL
Distilled"
}],
"shippingAddress":
[{"city":"Chicago"}]
"orderPayment":[
{
"ccinfo":"1000-
1000-1000-
1000",](https://image.slidesharecdn.com/aggregatedatamodels-250117052246-b628fb53/75/Aggregate-Data-Models-pptxszfsfsfsafsafsafasf-8-2048.jpg)


![Sample Data for above aggregate data model
// in customers
{ "customer":
{
"id": 1,
"name": "Martin",
"billingAddress": [{"city": "Chicago"}],
"orders": [
{
"id":99,
"customerId":1,
"orderItems":[
{
"productId":27,
"price": 32.45,
"productName":
"NoSQL
Distilled"
}],
"shippingAddress":
[{"city":"Chicago"}]
"orderPayment":[
{
"ccinfo":"1000-
1000-1000-
1000",
"txnId":"abelif879rft",](https://image.slidesharecdn.com/aggregatedatamodels-250117052246-b628fb53/75/Aggregate-Data-Models-pptxszfsfsfsafsafsafasf-12-2048.jpg)