Download as PDF, PPTX











![[SLI][SLO][t]
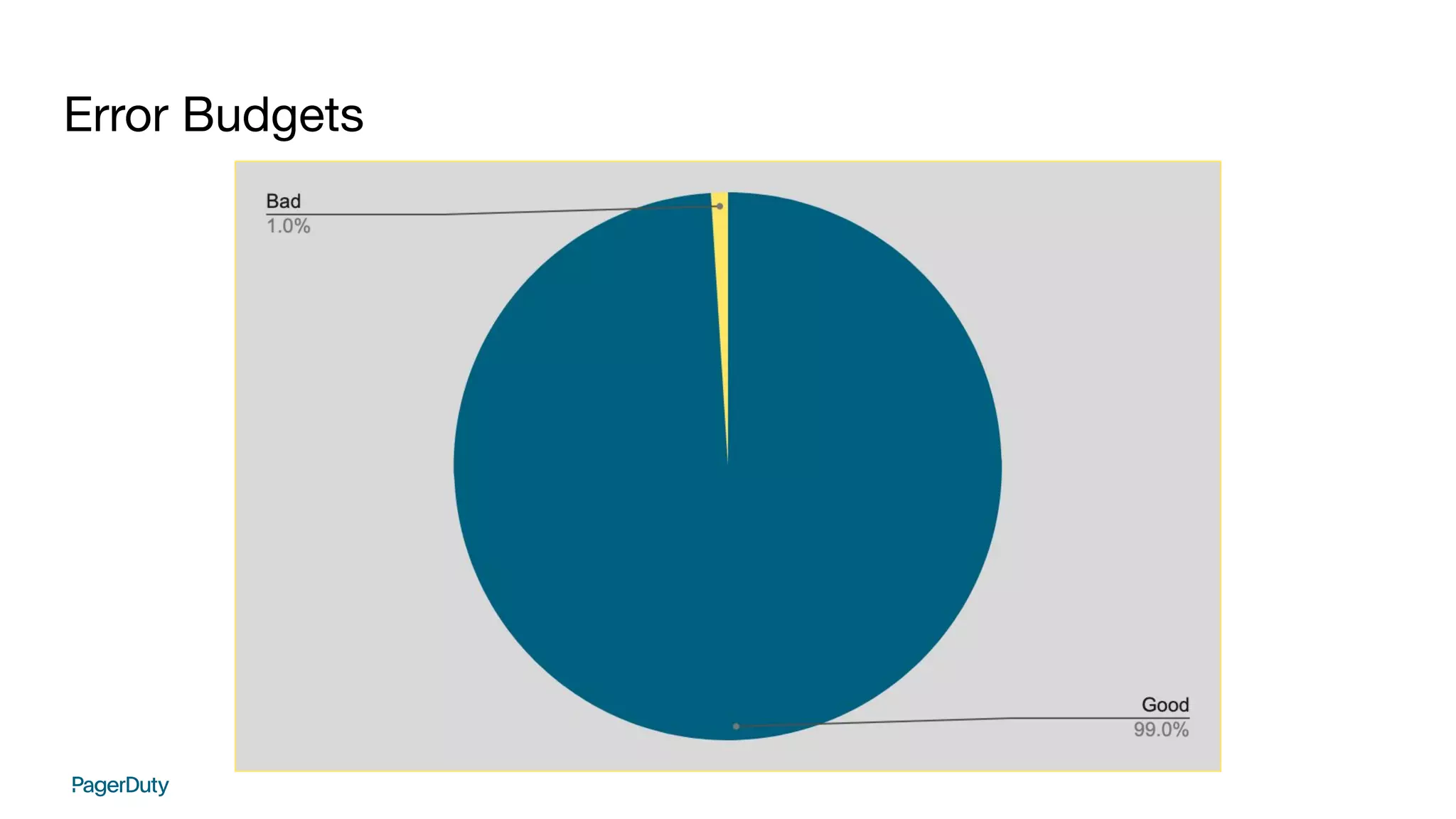
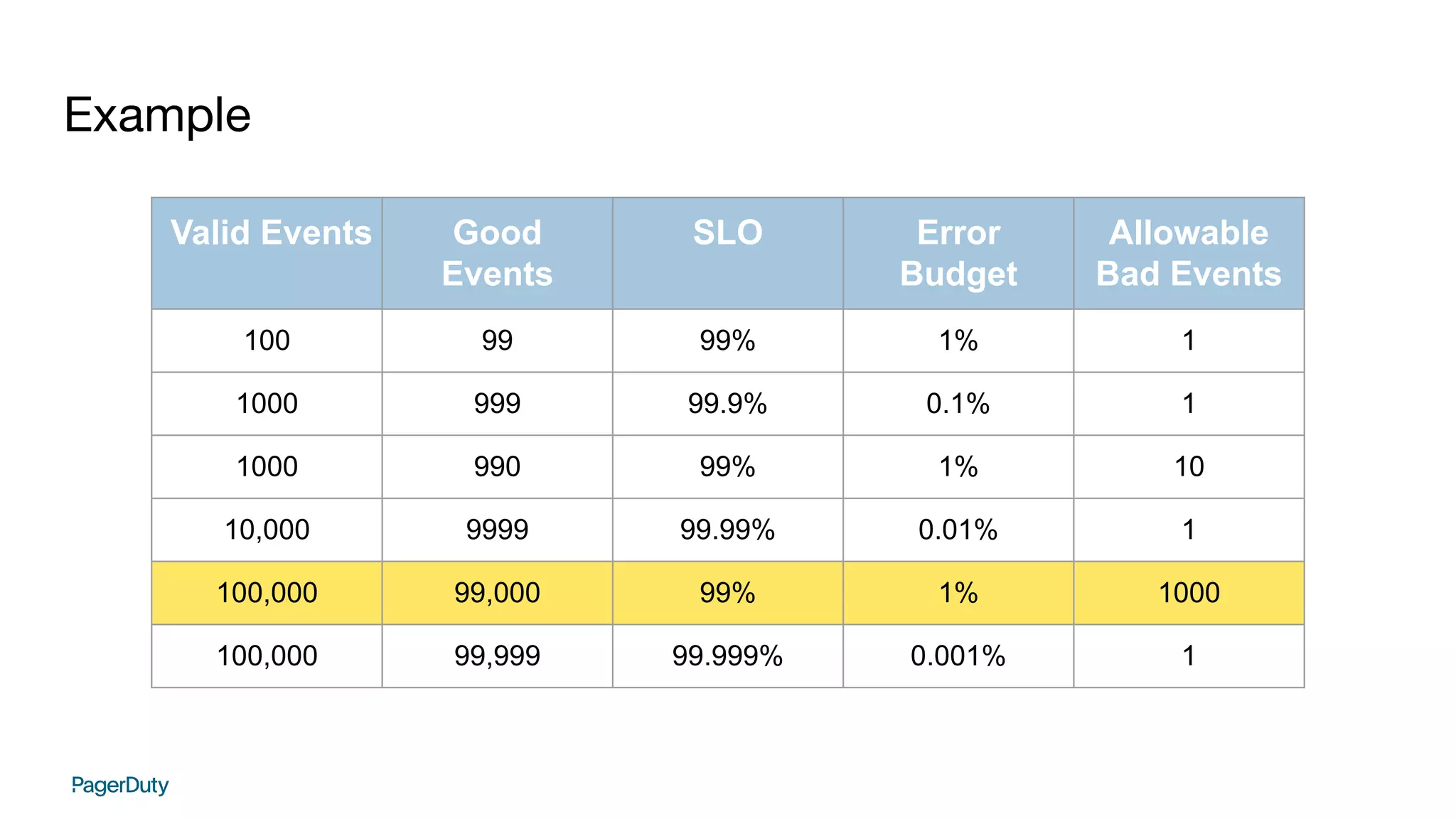
SLI = (good/valid) * 100
eb = 100 - SLI](https://image.slidesharecdn.com/addoreducingtraumainorganizationswithslosandchaosengineering-211029003201/75/Addo-reducing-trauma-in-organizations-with-SLOs-and-chaos-engineering-18-2048.jpg)




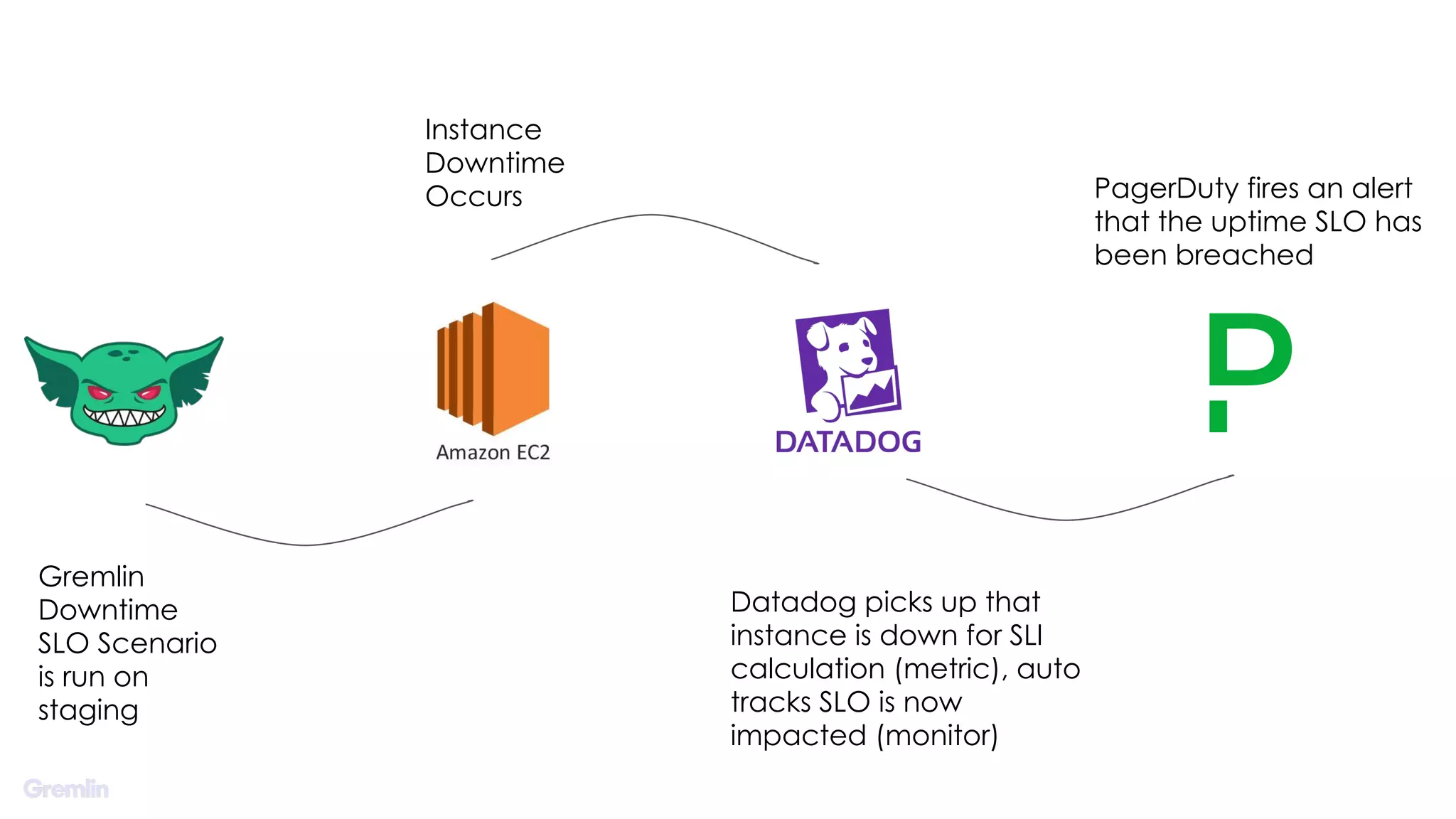











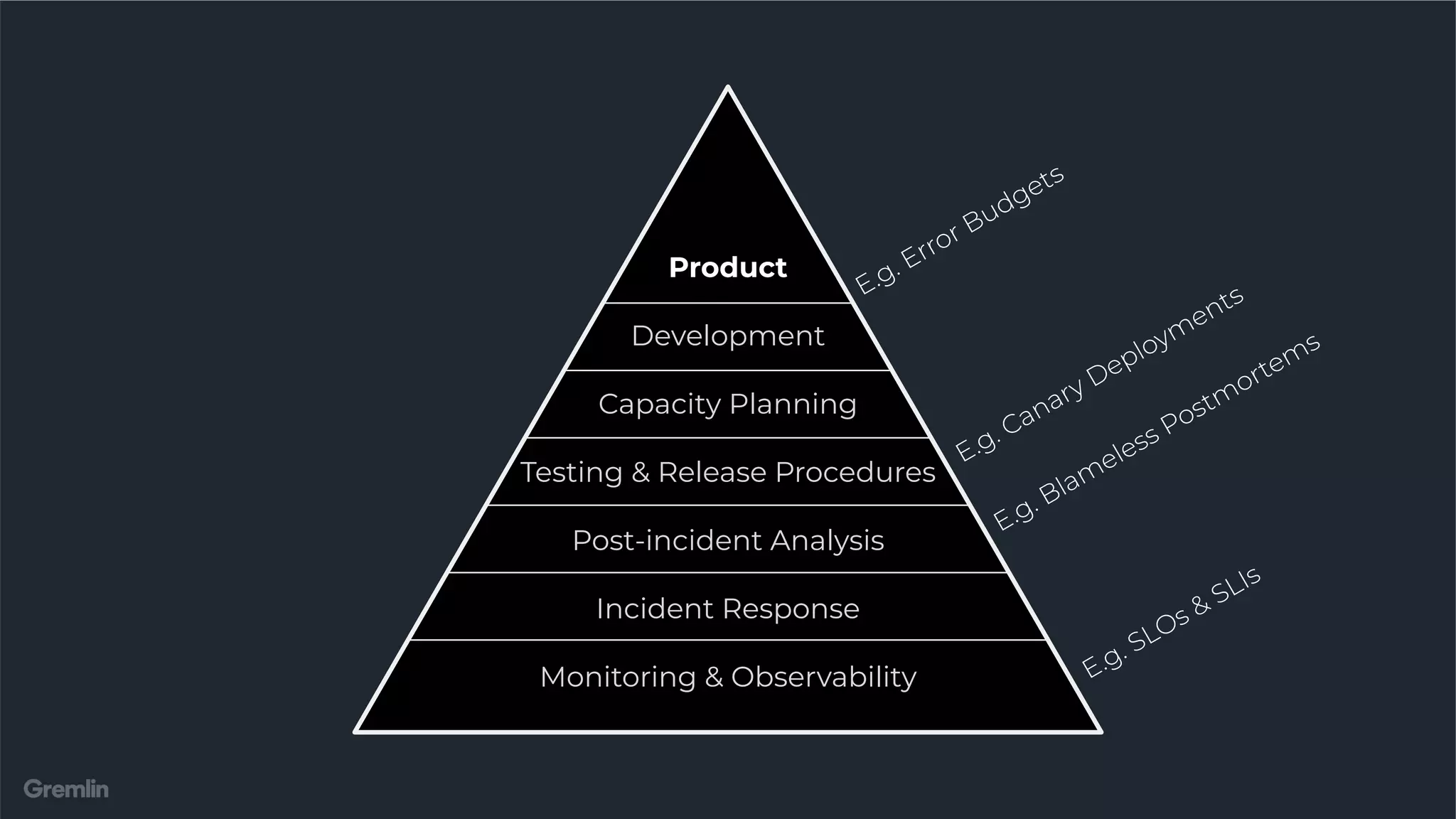
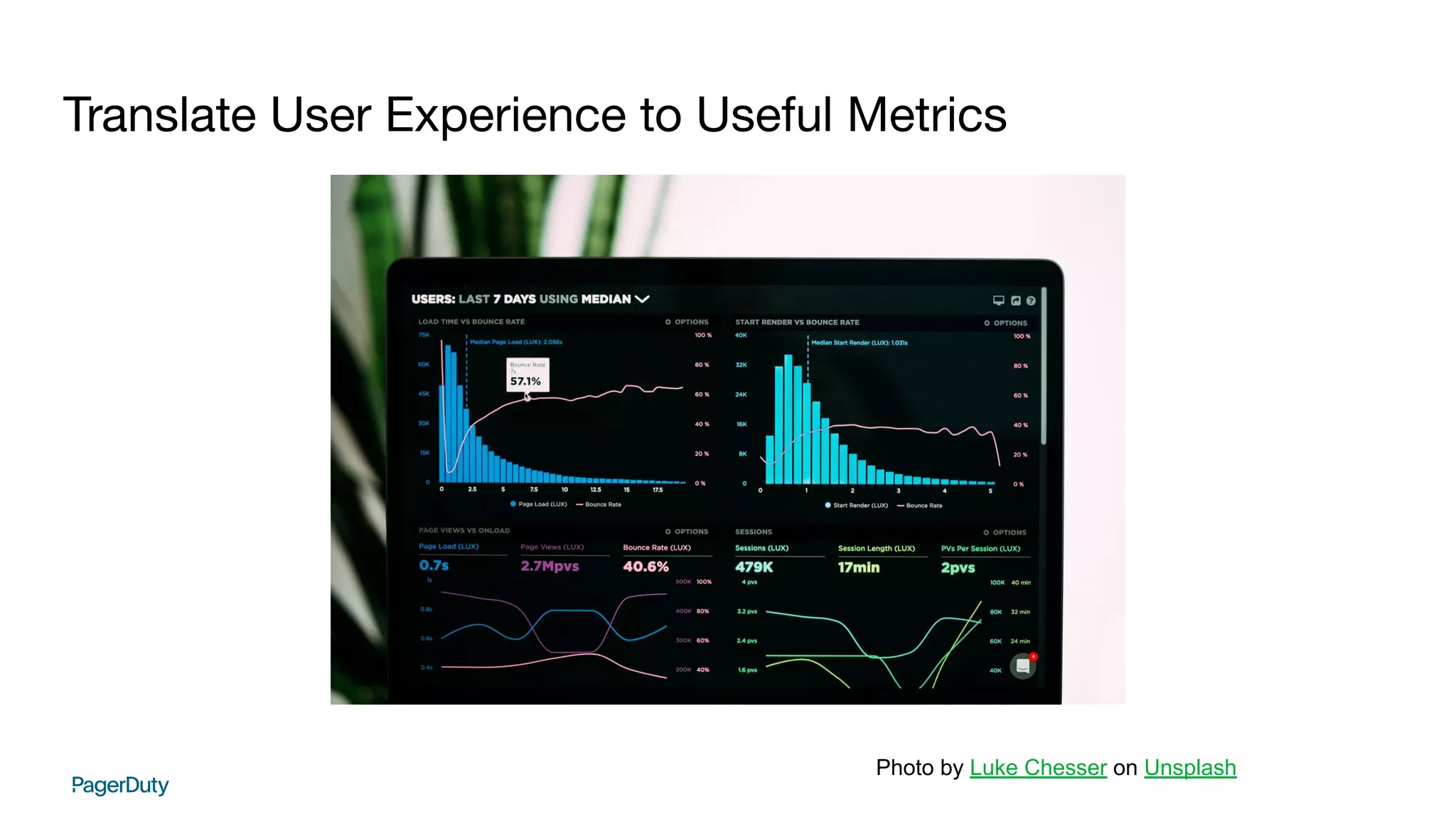
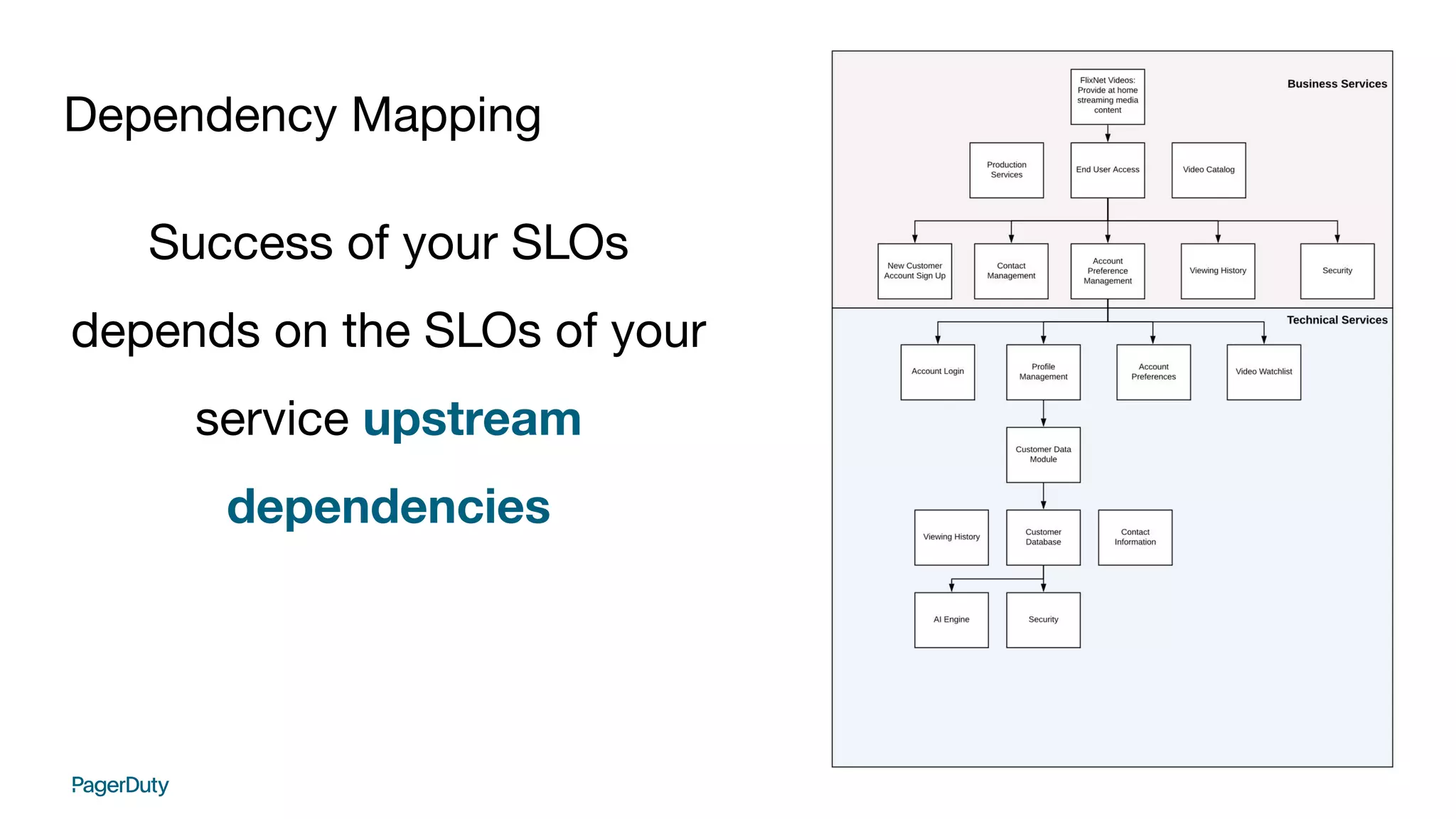
This document discusses establishing service level objectives (SLOs) and indicators (SLIs) to quantify user experience and prioritize work. It recommends using chaos engineering to validate SLOs and dependencies by injecting failures. Key points: - SLOs quantify goals for SLIs to measure user experience quality like load times and errors - Error budgets set thresholds for acceptable failures to meet SLOs - Chaos engineering tests new features and validates SLOs and dependencies by inducing failures - Incidents provide opportunities to revisit SLOs and prioritize work to improve experience























































































