










![Solution: Subsampling Training Data
● Any query for which at least one of the ads was clicked.
● A fraction r ∈ (0, 1] of the queries where none of the ads were clicked.
The expected contribution of a randomly chosen event t in
the unsampled data to the sub-sampled objective function
FIXING THE SAMPLING BIAS
12](https://image.slidesharecdn.com/presentation-ad-clickprediction-aviewfromthetrenches-161017121827/85/Ad-Click-Prediction-Paper-review-12-320.jpg)



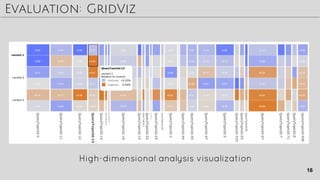






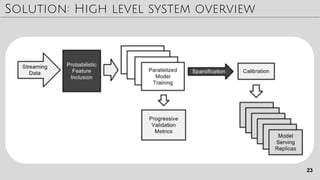

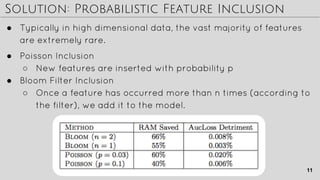
The document discusses techniques for improving ad click prediction, a crucial task for online advertising. It presents the FTRL-Proximal learning algorithm, which combines the accuracy of online gradient descent with the sparsity of regularized dual averaging. Memory saving techniques are also key, including probabilistic feature inclusion, subsampling training data, and encoding values with fewer bits. Evaluation shows the approaches improve AUC by 11.2% over baselines. The techniques aim to efficiently handle massive online advertising data at scale.










































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)
