Download as PDF, PPTX






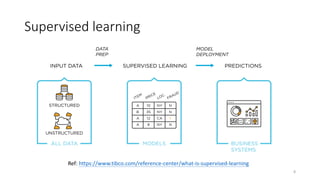





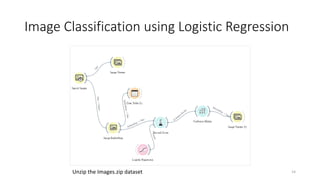



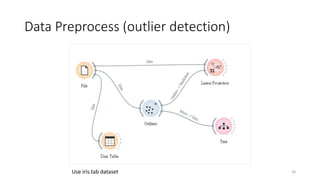



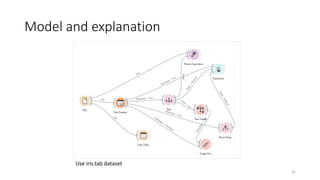

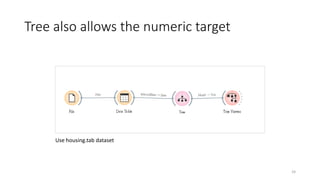

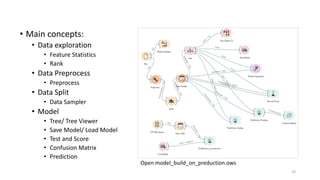


The document outlines key concepts of supervised learning, including its definition, differences from unsupervised learning, and applications such as classification and regression. It provides tutorials on image classification using logistic regression and discusses various real-life applications like spam detection and price forecasting. It also includes homework assignments to implement different models on binary datasets, focusing on model evaluation and significant variables.
























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)










