Download as PDF, PPTX



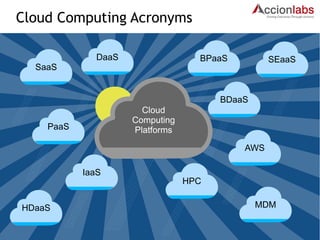
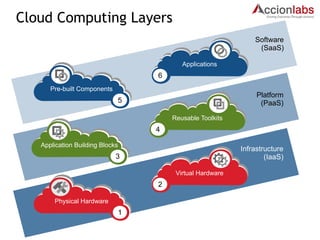
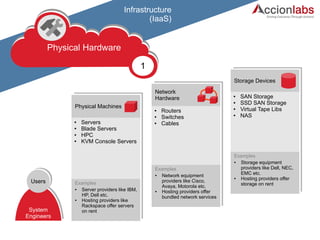
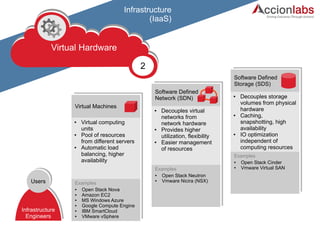
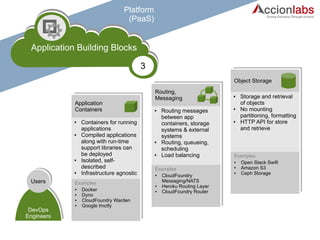
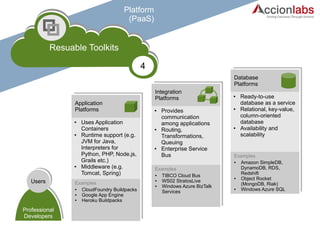
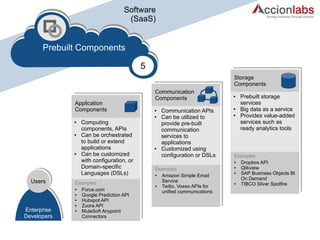
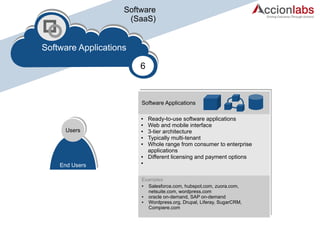

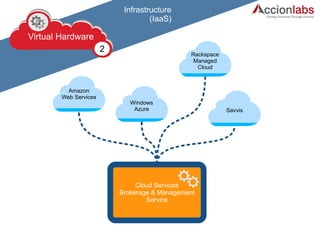



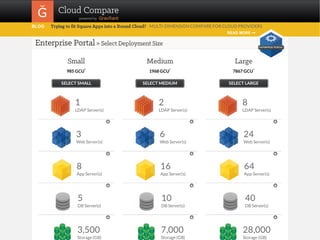
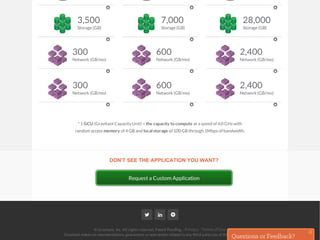
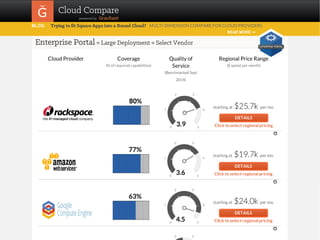
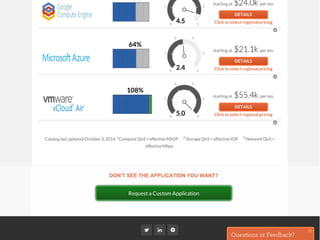

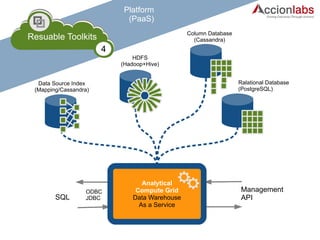

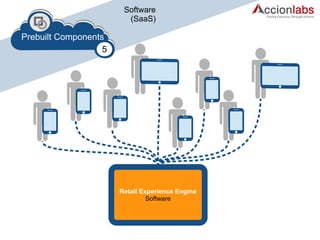



The document provides a comprehensive framework to classify and compare various cloud computing services, detailing the Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS) layers. It includes examples of providers, applications, and the functionalities within each cloud layer, along with typical use cases and user demographics. Additionally, it highlights key acronyms and definitions relevant to cloud computing.