Downloaded 92 times



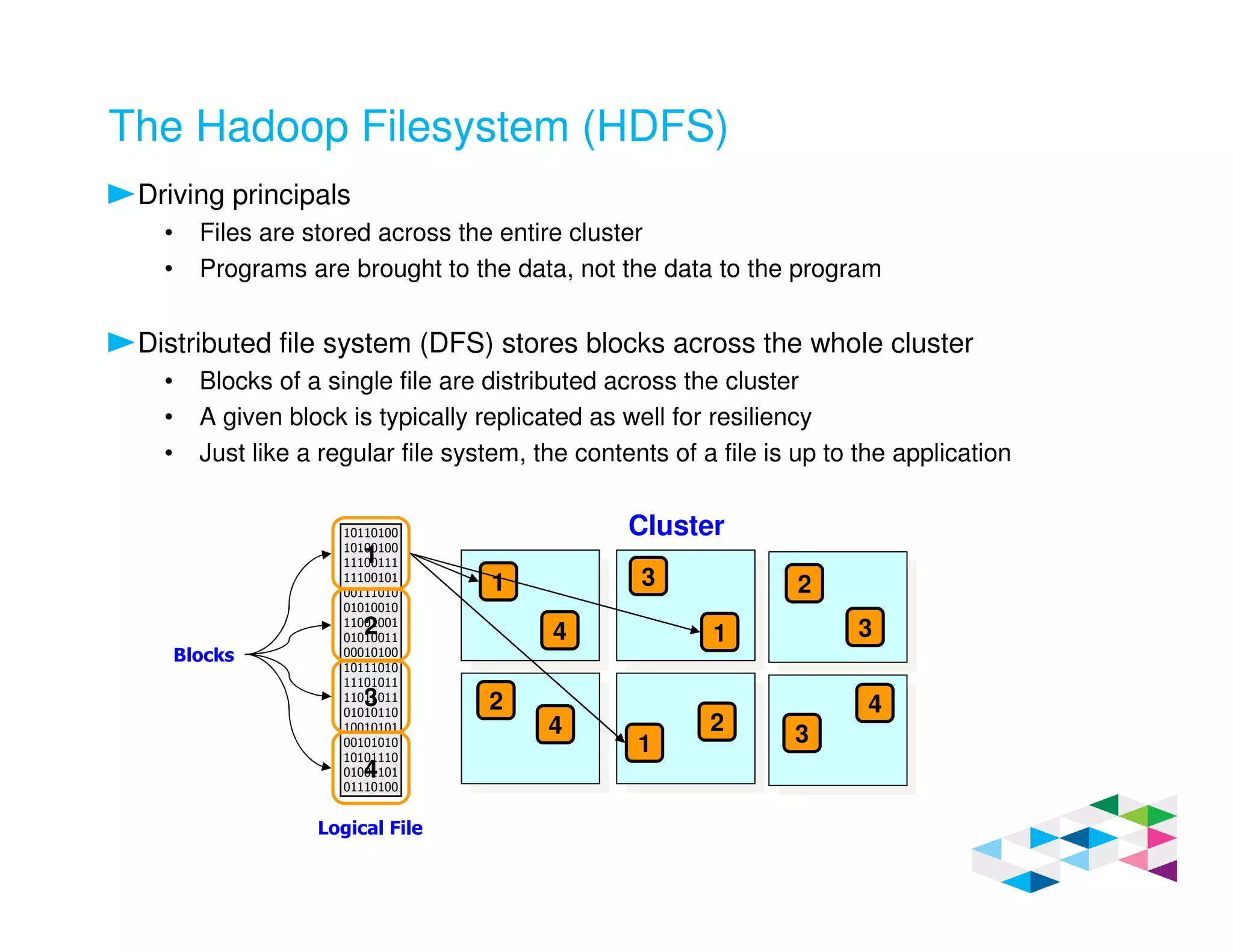
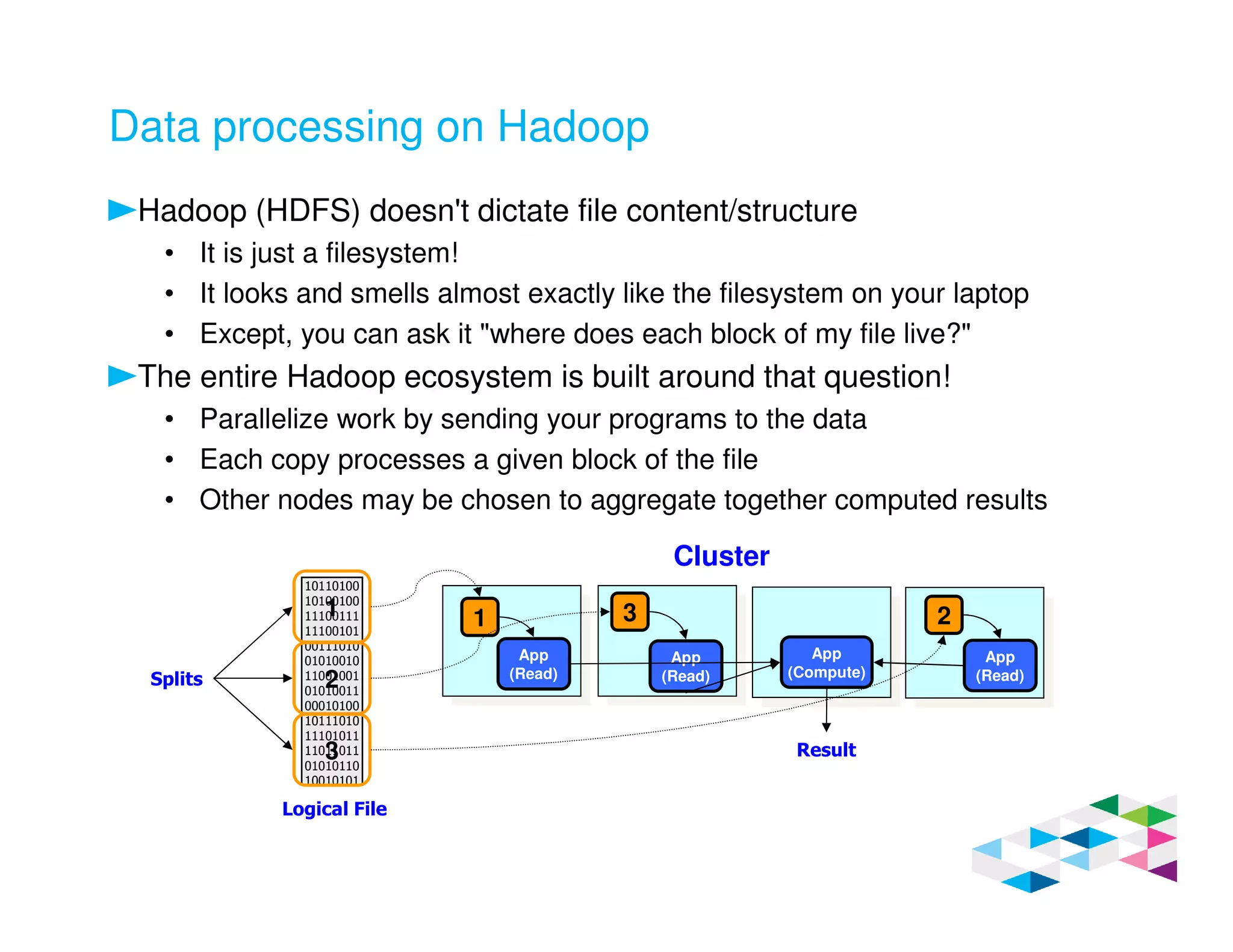

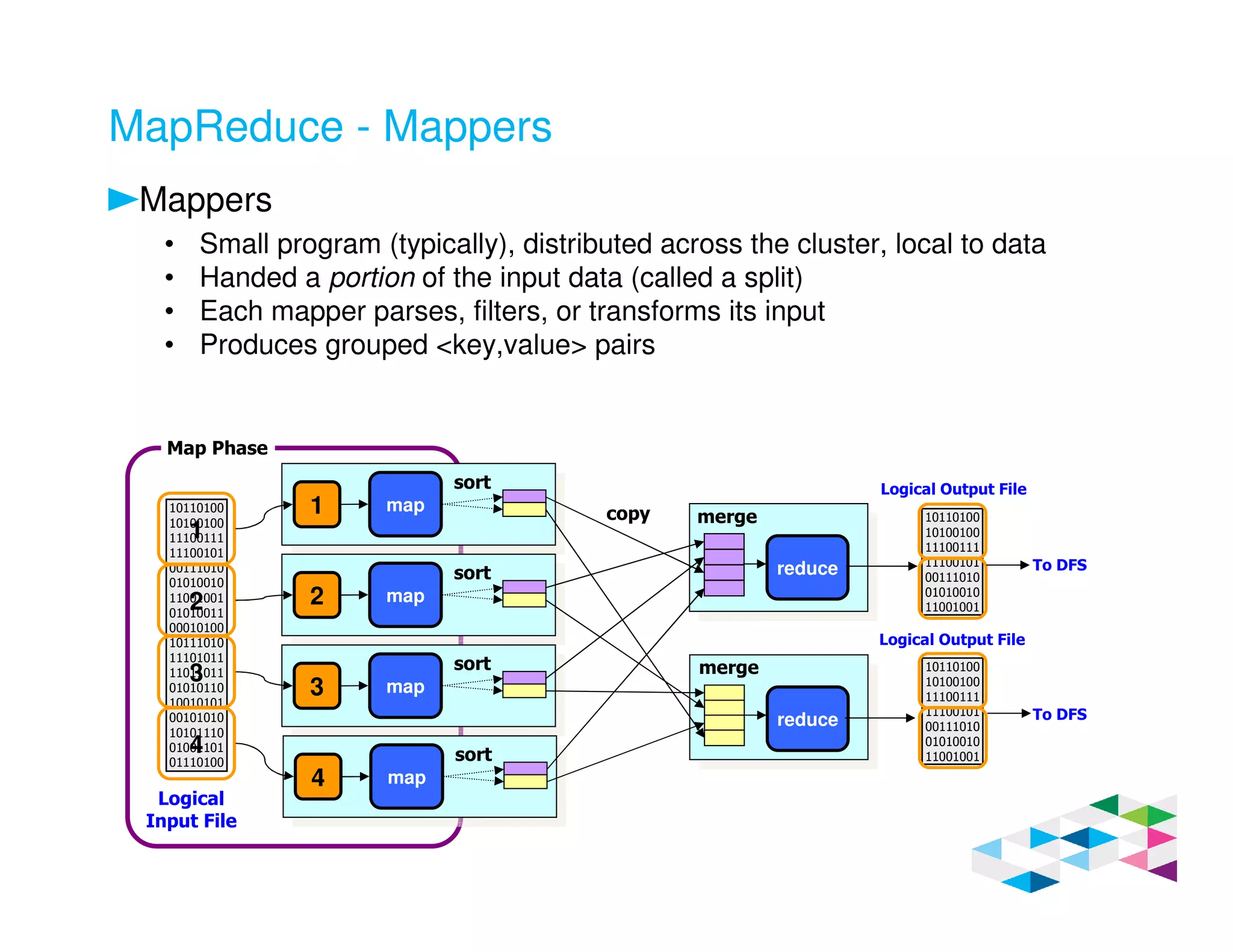
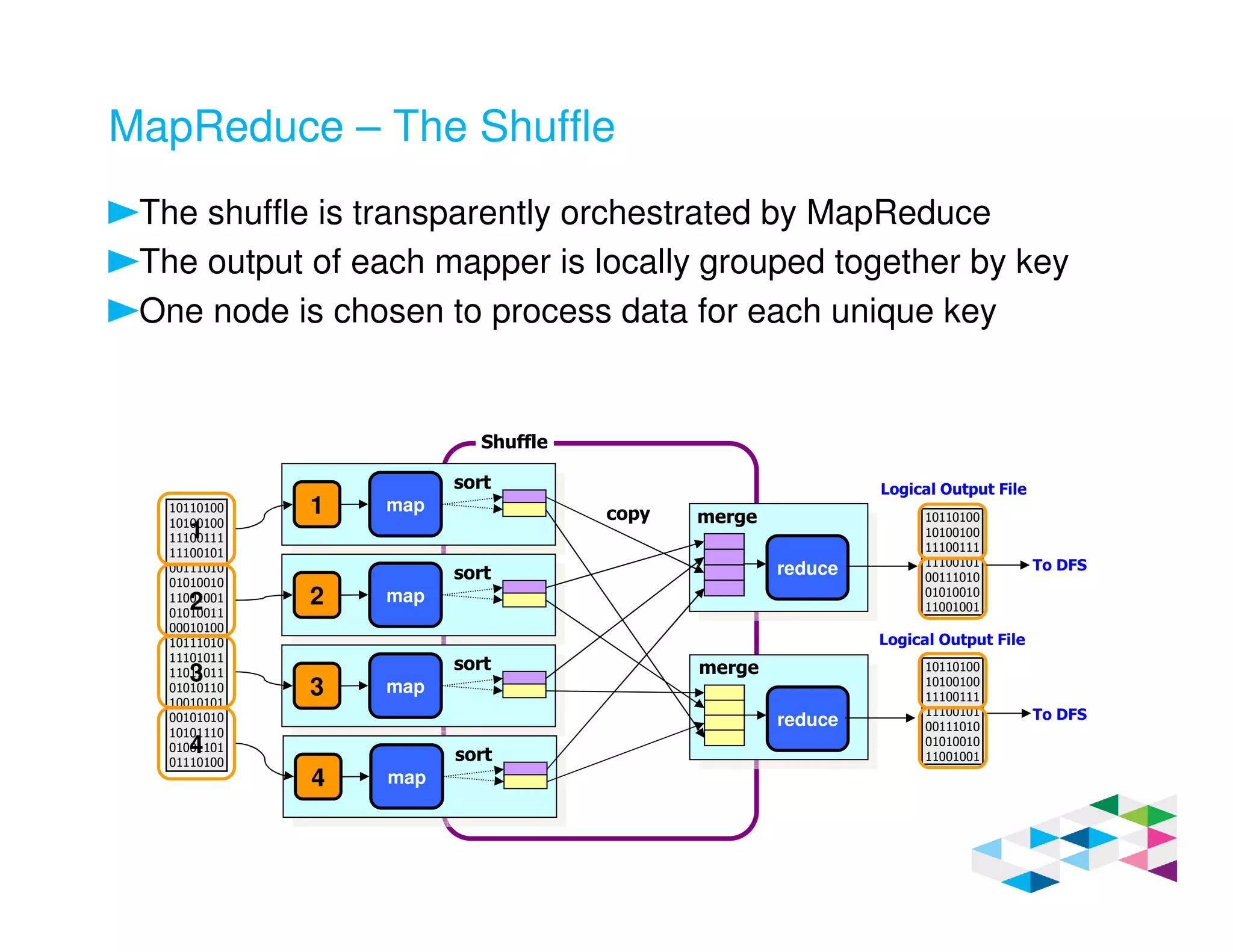
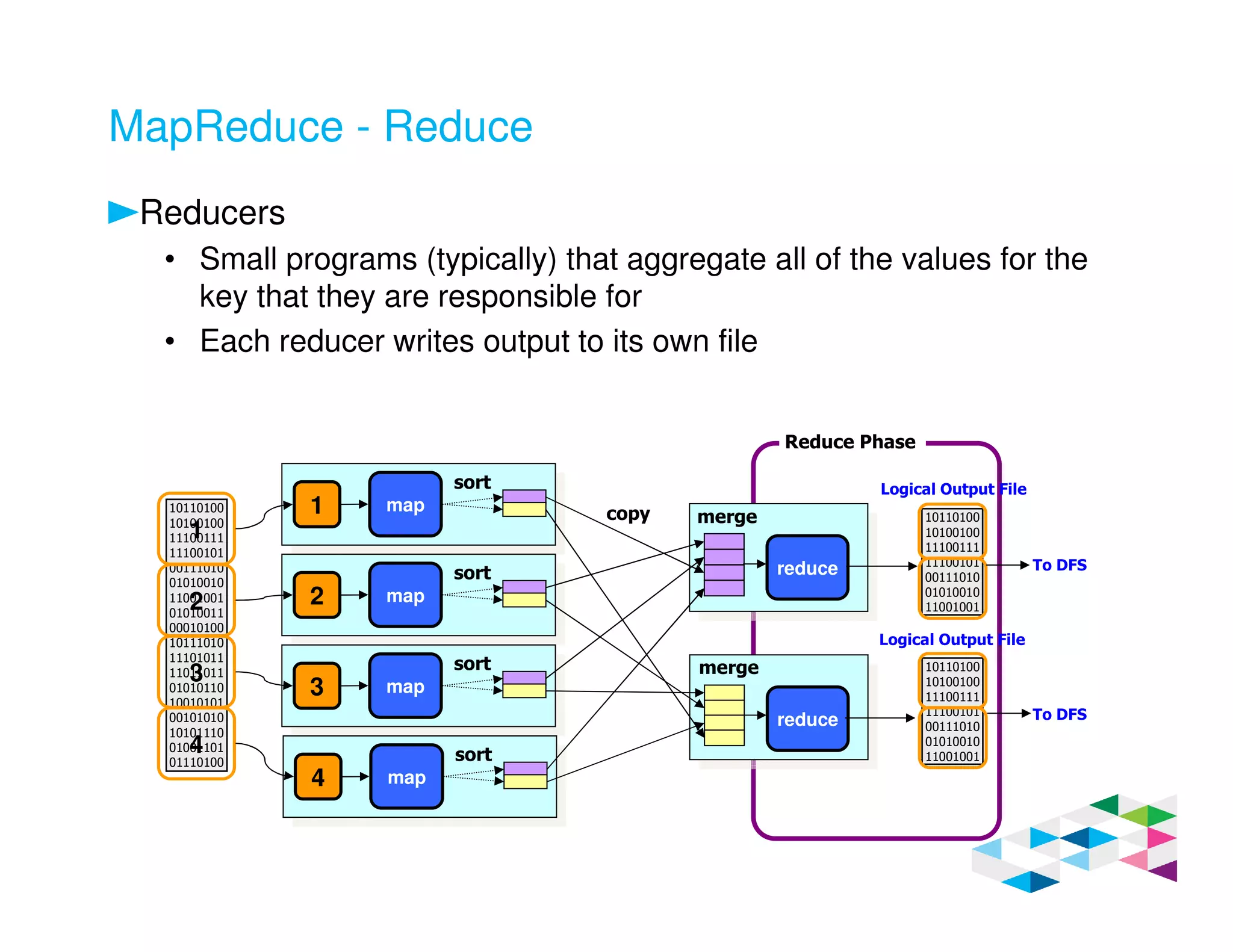






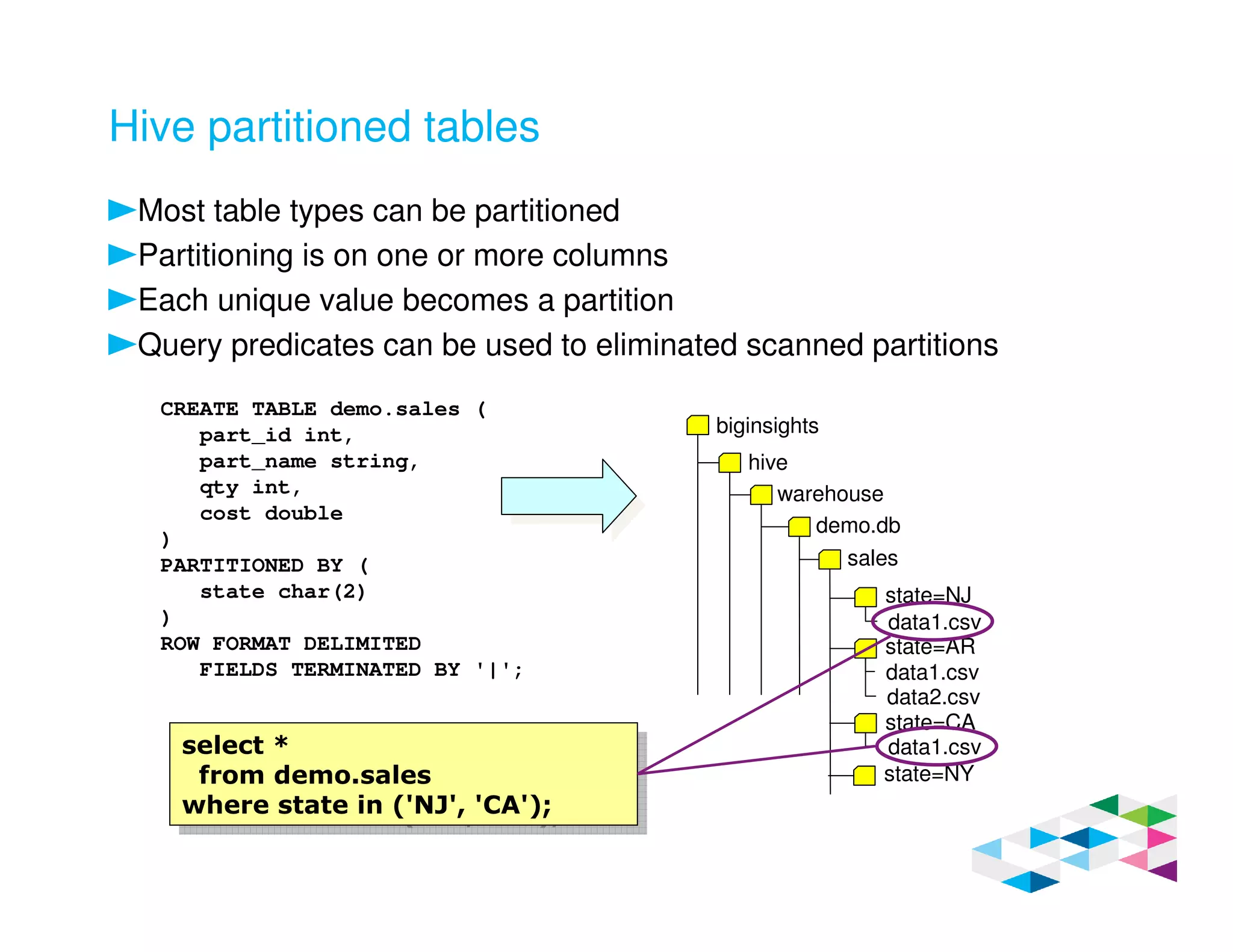


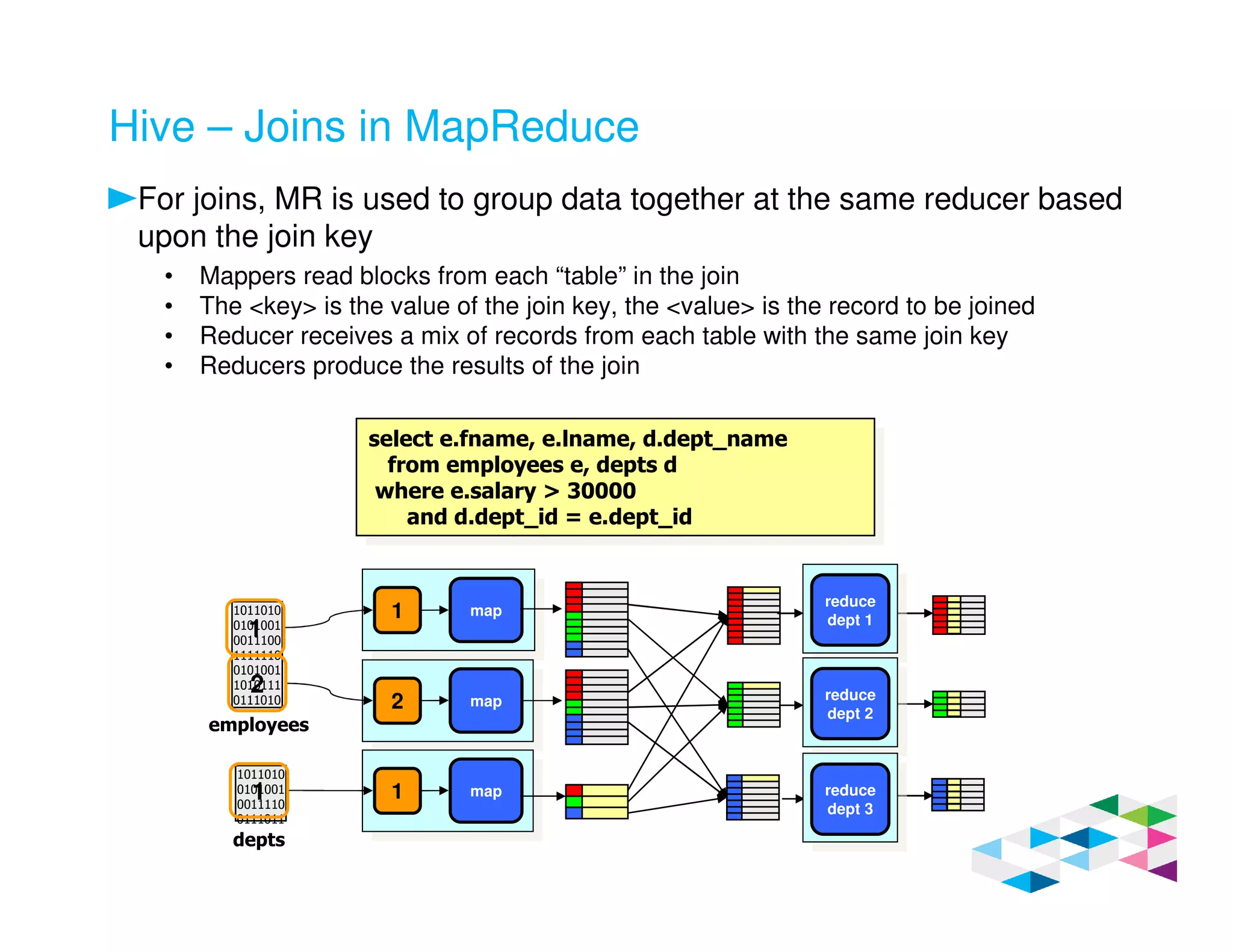
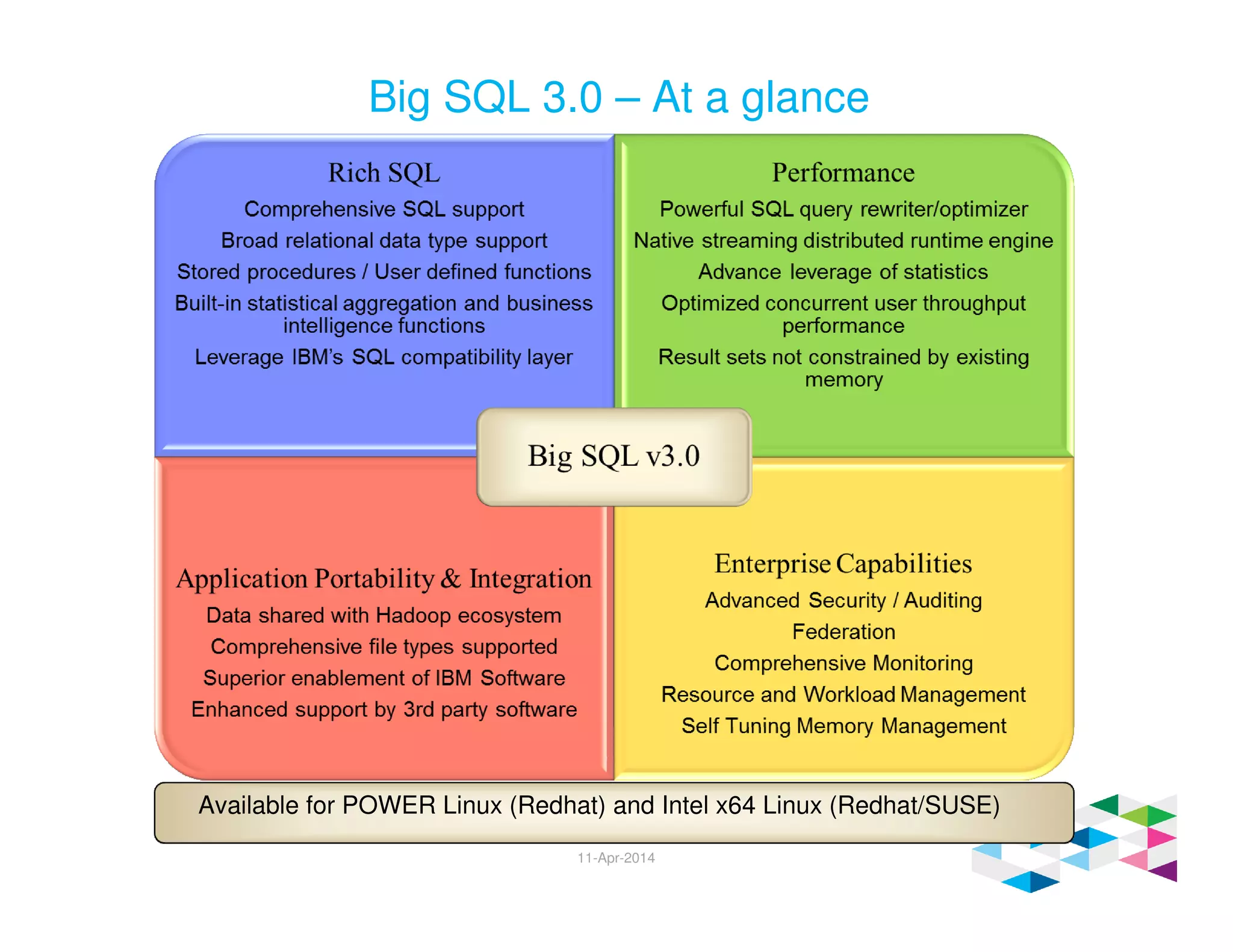


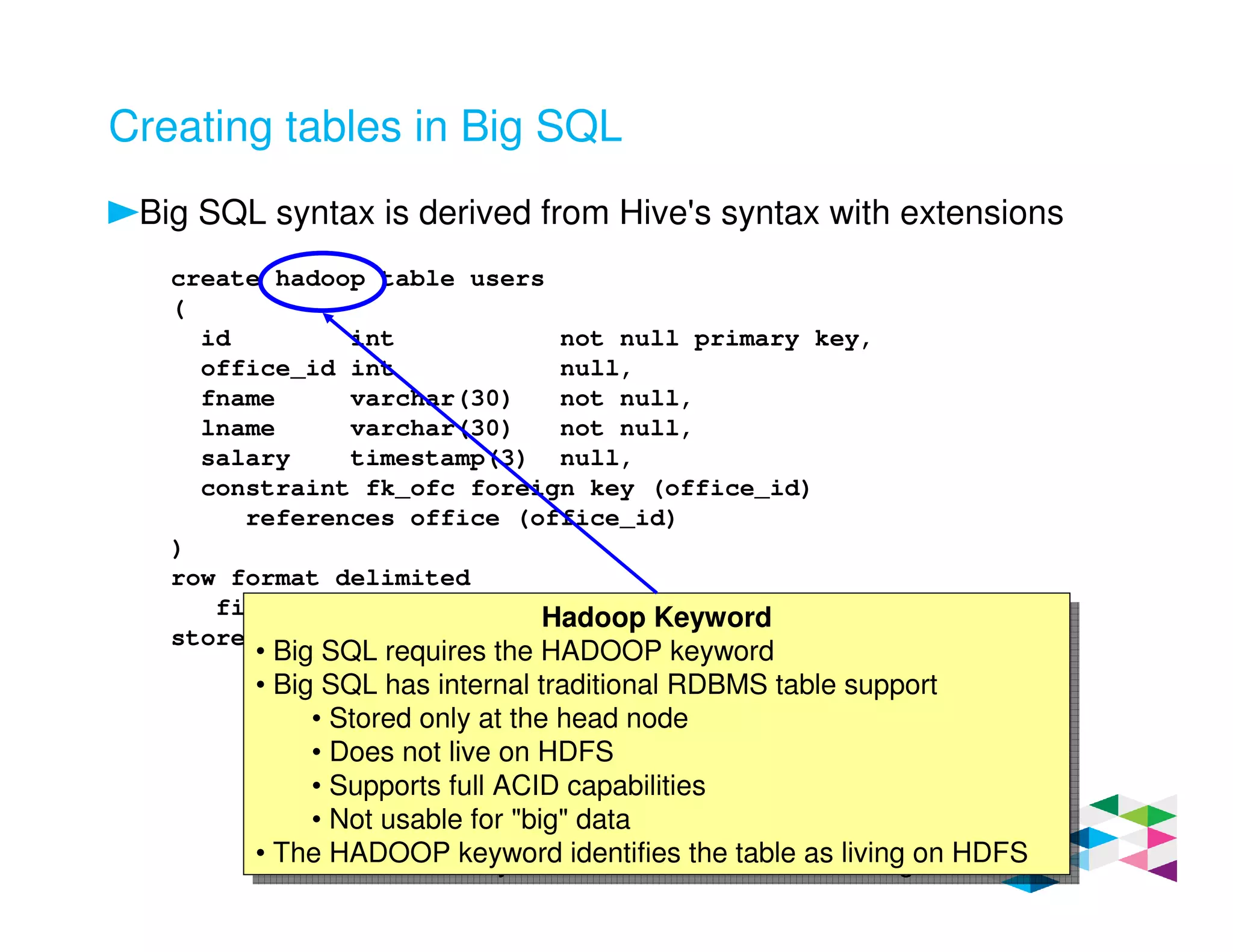











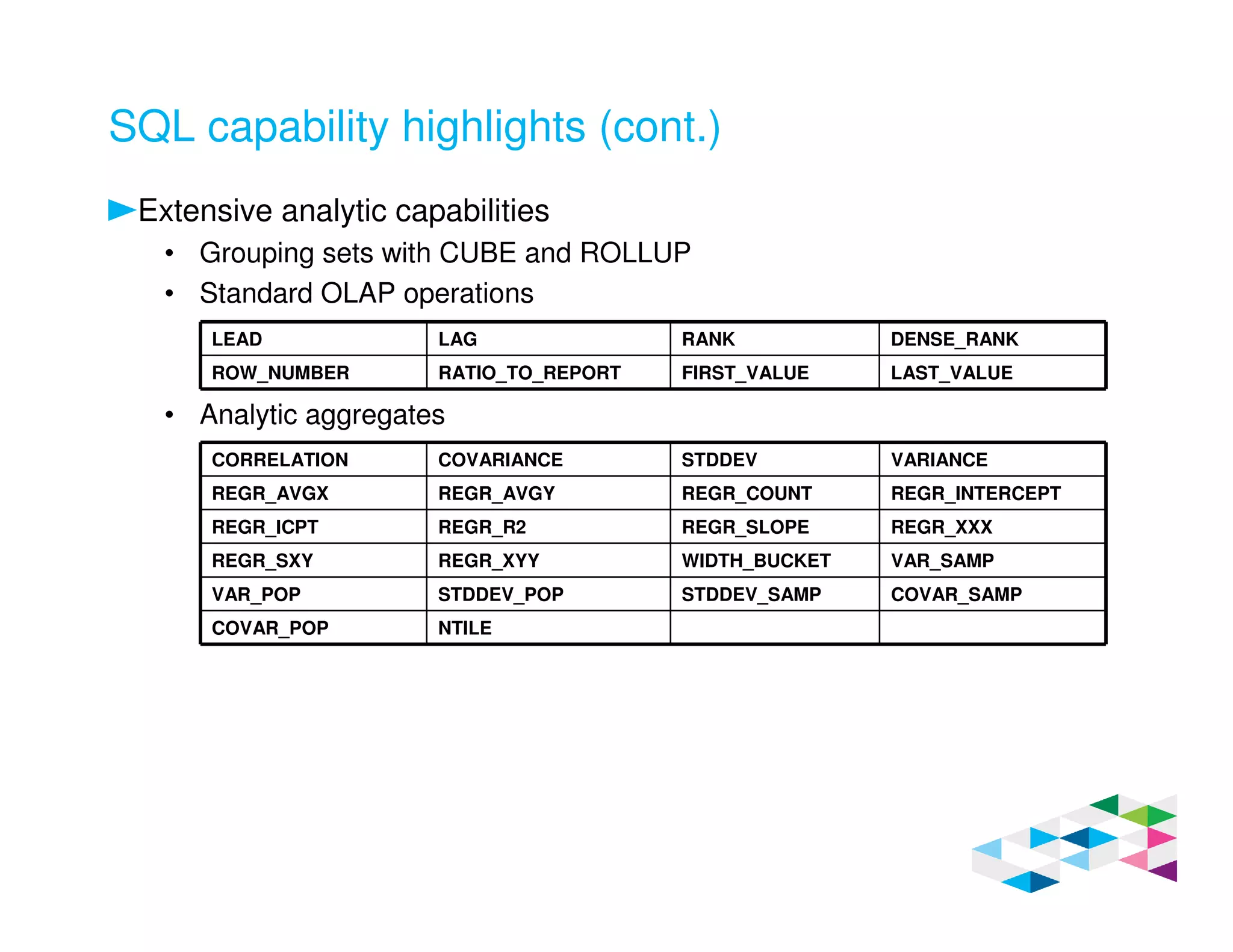
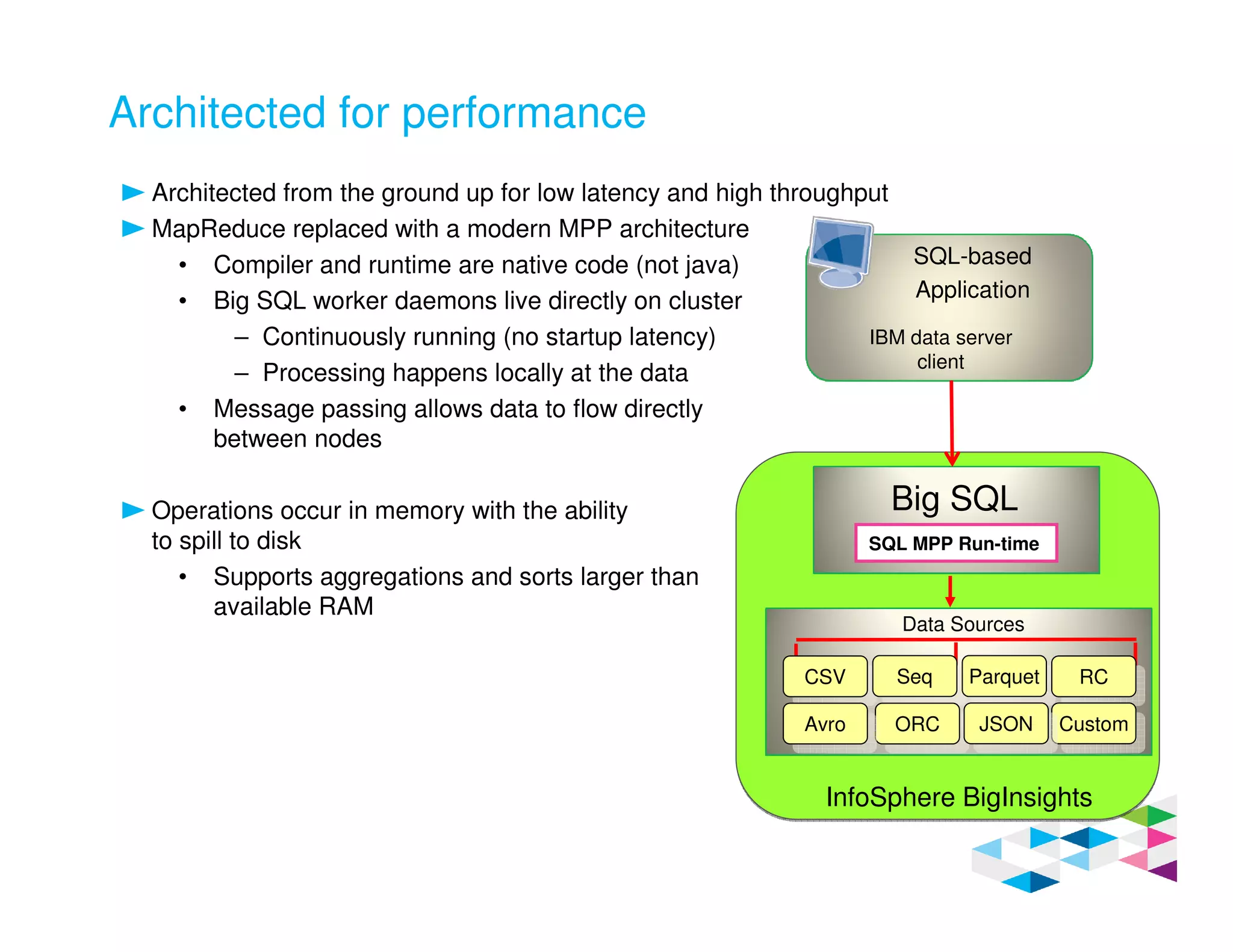
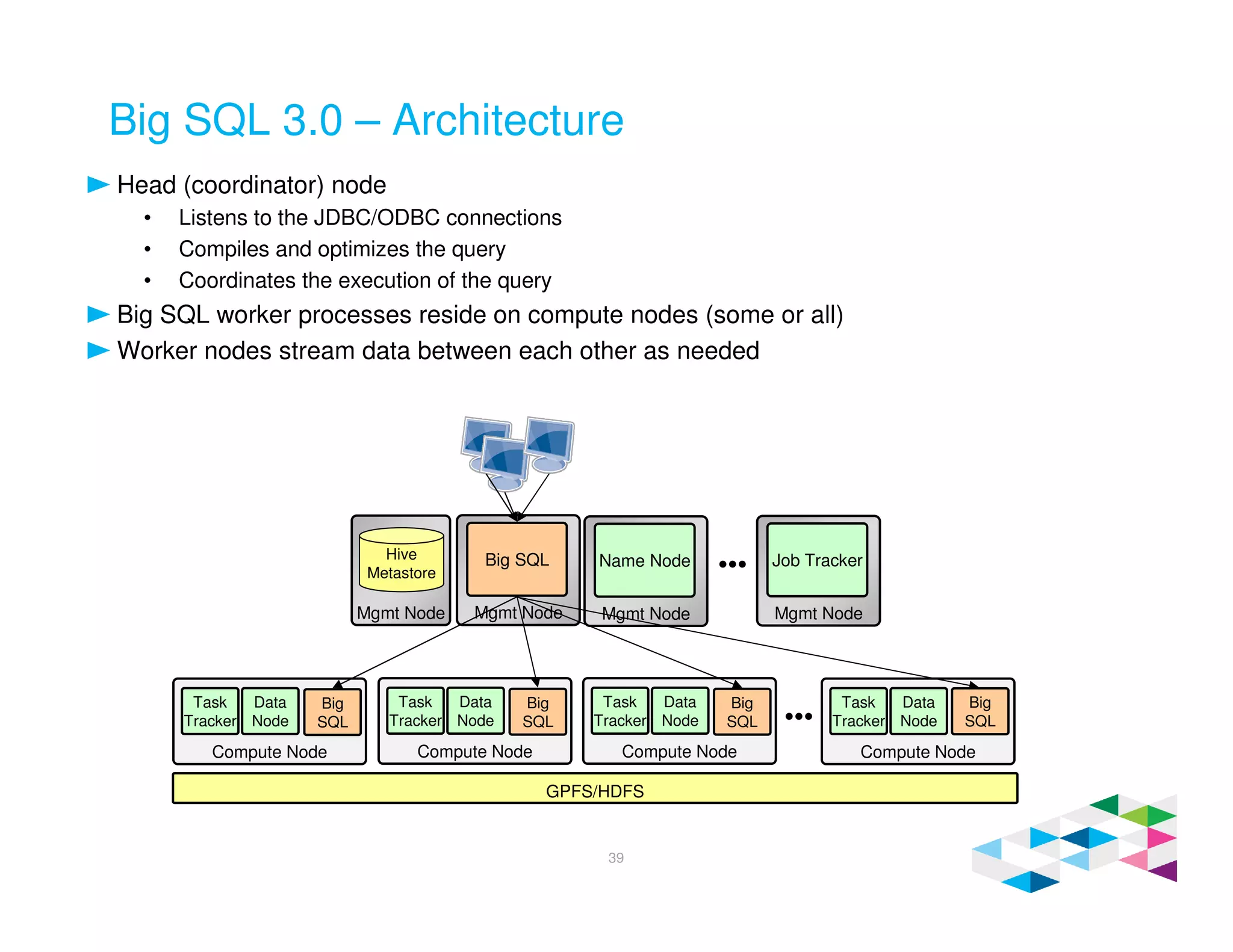

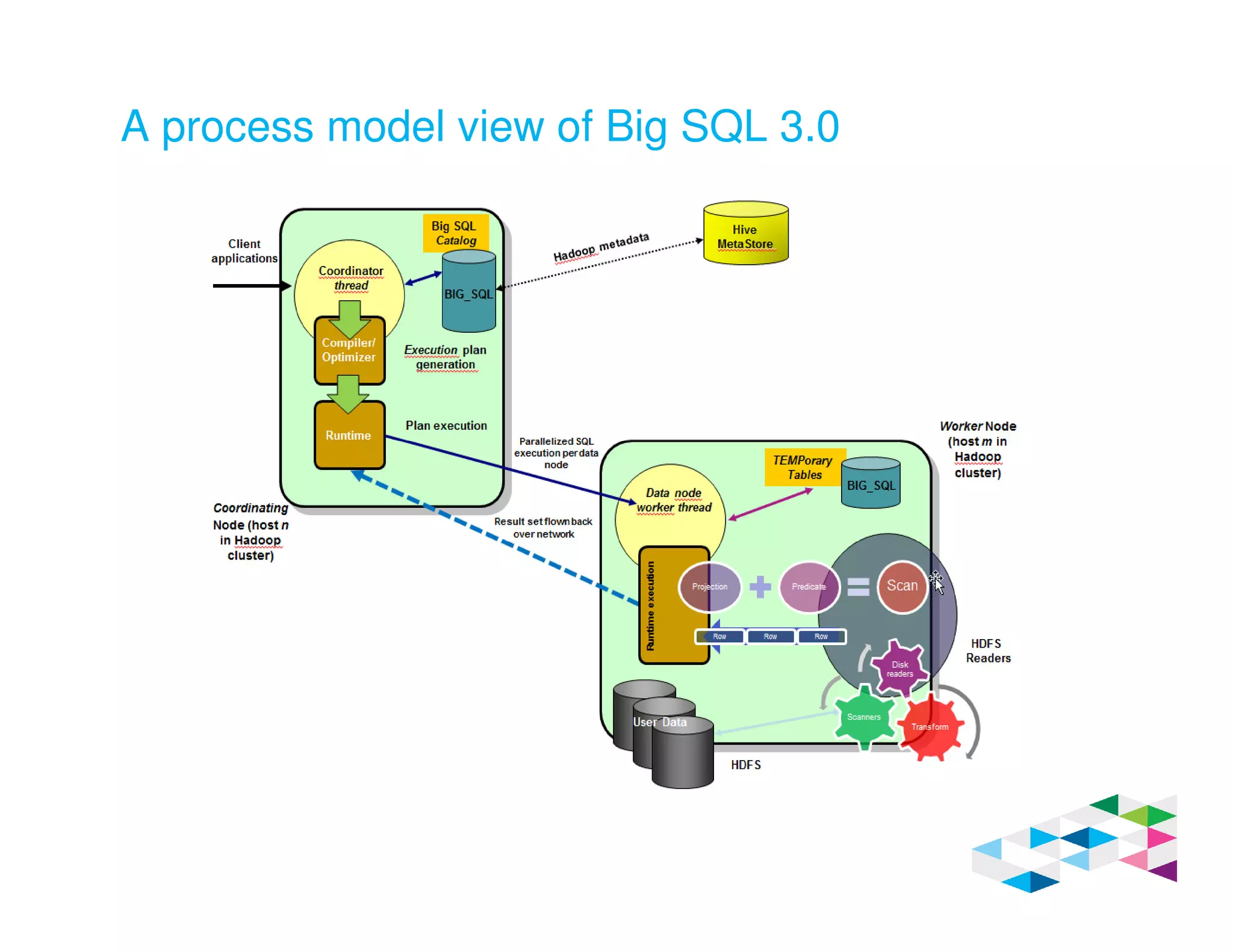



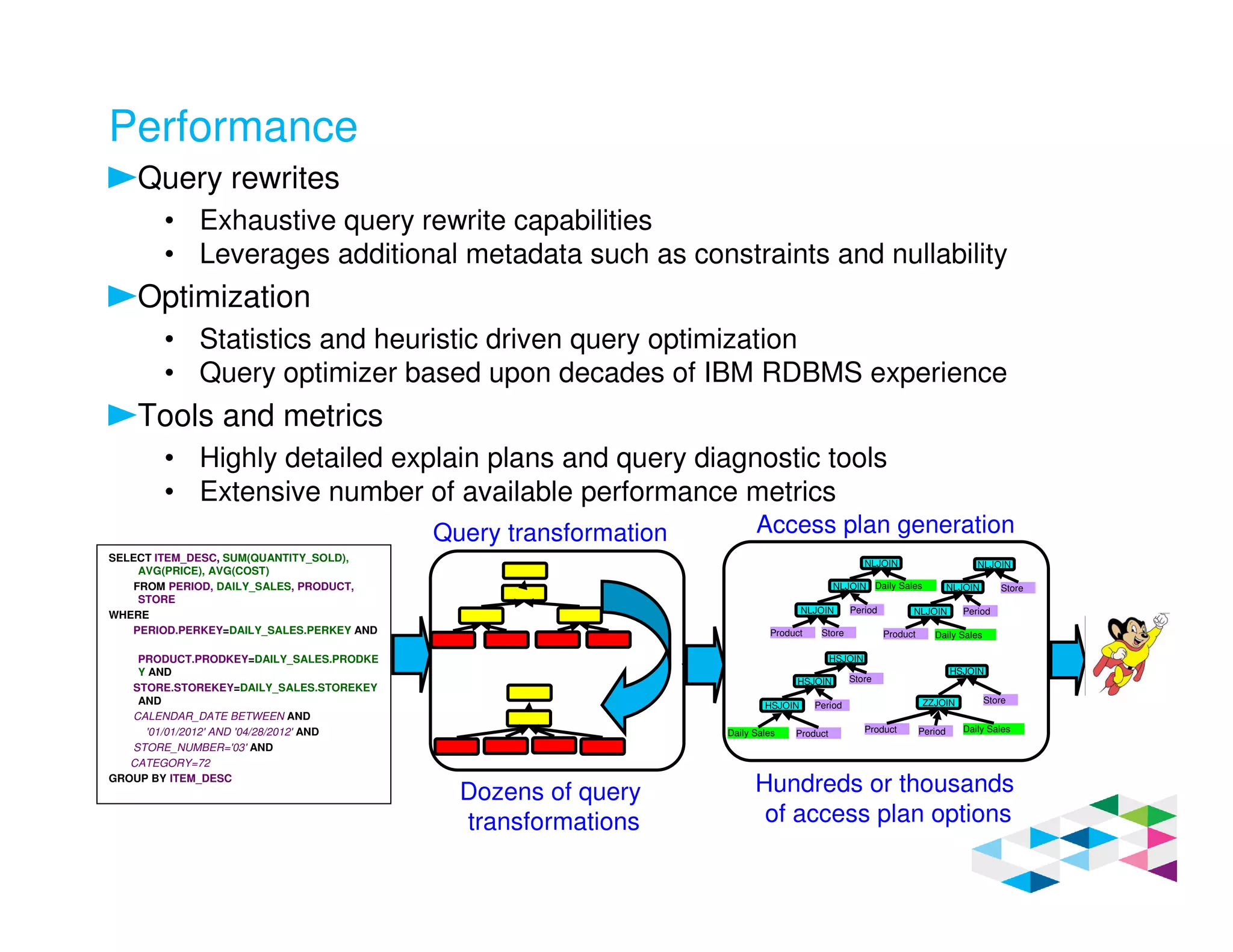
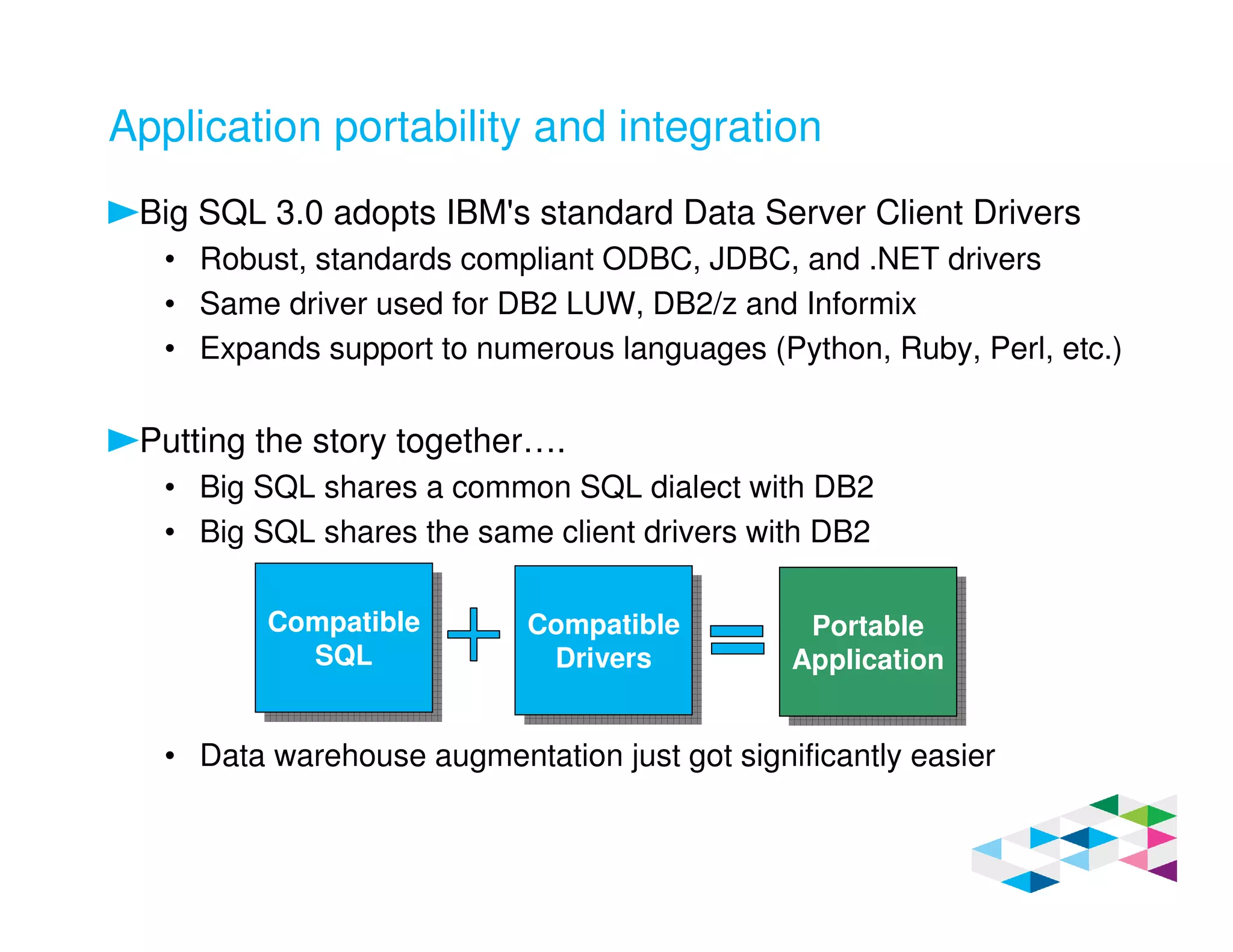


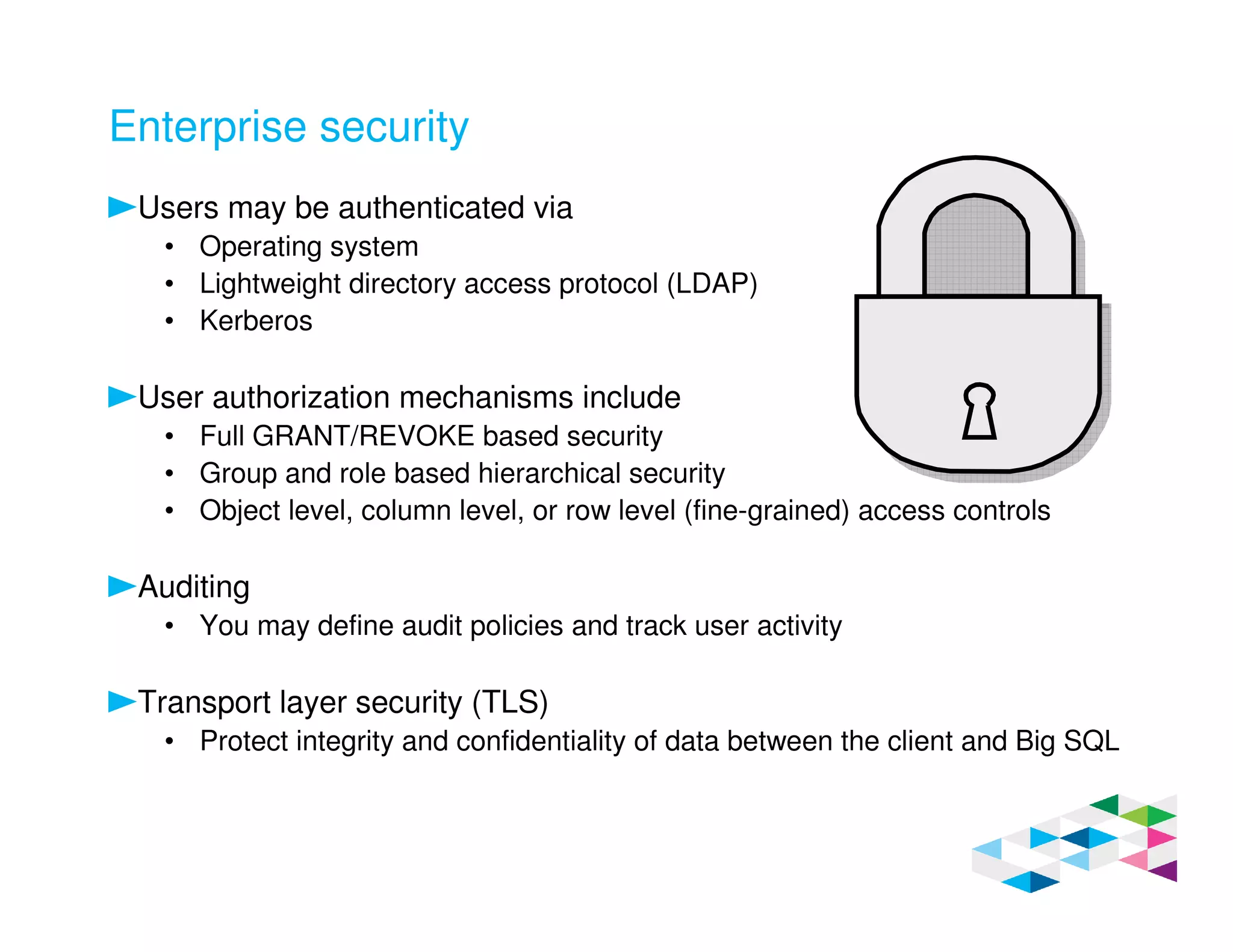
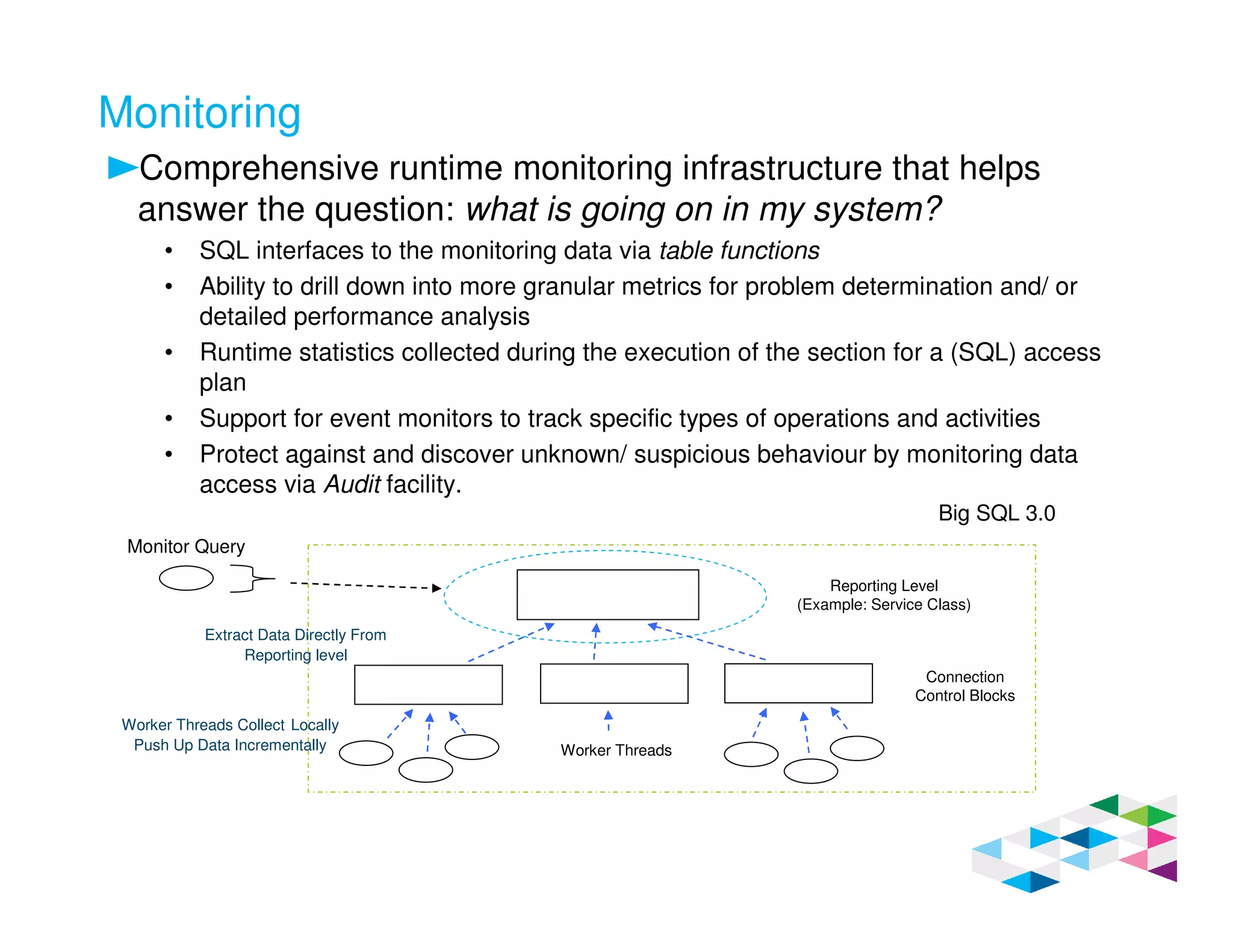

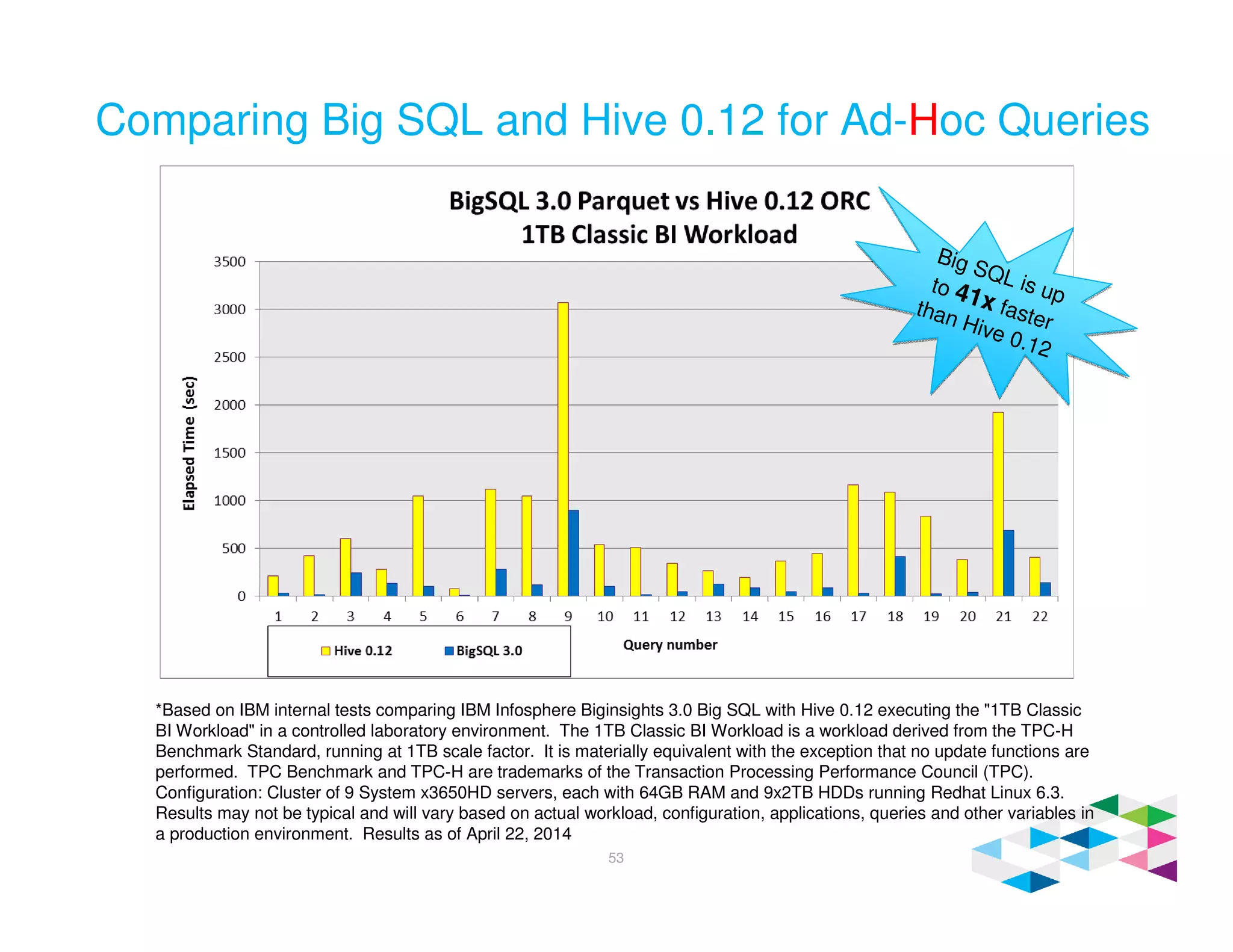

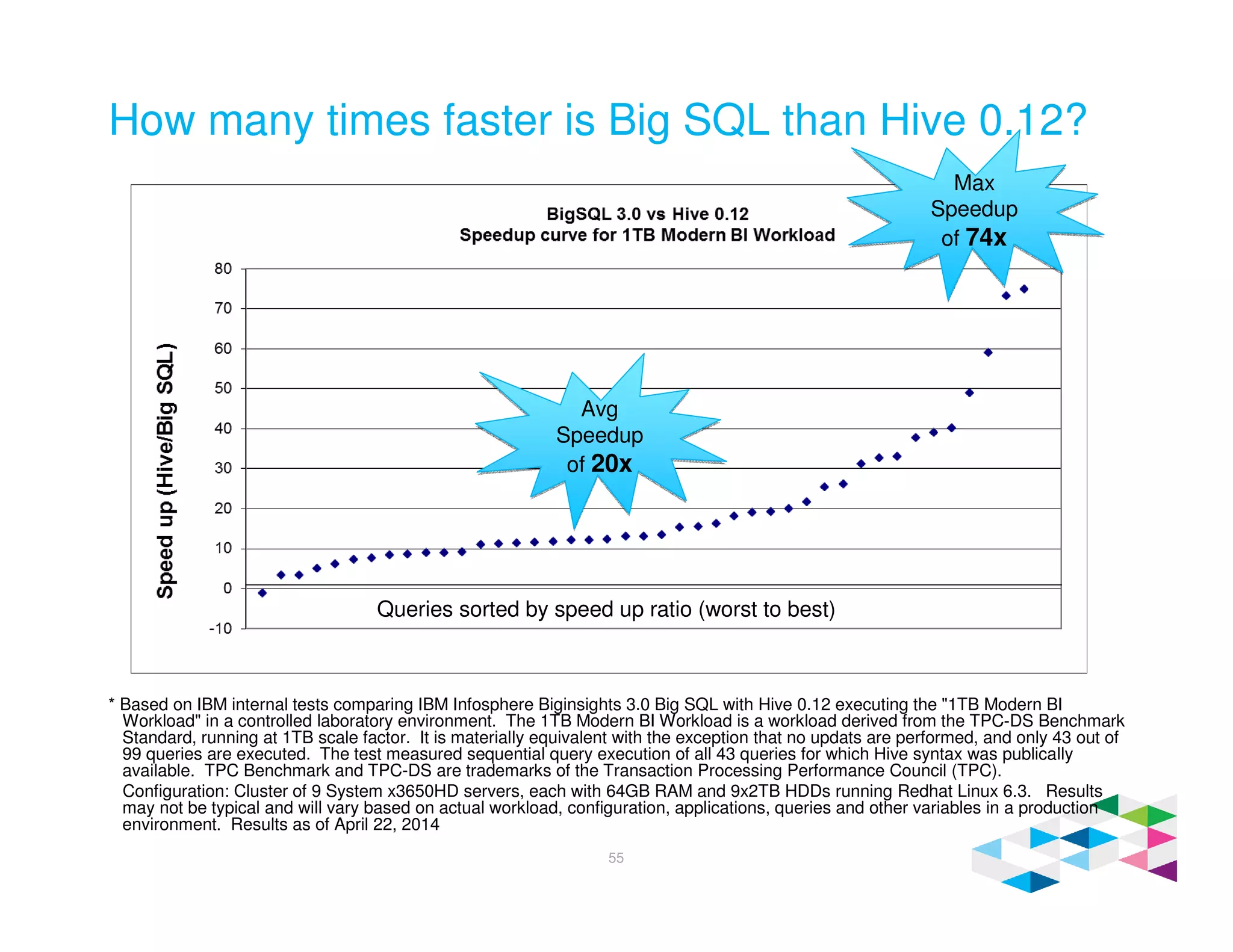




Big SQL 3.0 is a SQL-on-Hadoop solution that provides SQL access to data stored in Hadoop. It uses the same table definitions and metadata as Hive, accessing data already stored in Hadoop without requiring a proprietary format. Big SQL extends Hive's syntax with features like primary keys and foreign keys. Tables in Big SQL and Hive represent views of data stored in Hadoop rather than separate storage structures.











































































