1.1. RBMT
Rule basedMachine Translation (RBMT)
• 두 언어의 문법 규칙(Rule)을 기반으로 개발.
• 문법 규칙(Rule) 추출의 어려움
• 번역 언어 확장의 어려움
5.
1.2. SMT
Statistical MachineTranslation (SMT)
• 두 언어의 Parallel Corpus에서
Co-occurrence 기반의 통계 정보를 바탕으로 번역을 수행
• 여러 Component의 조합으로 시스템 구성
• Translation Model
• Language Model
• Reordering Model
6.
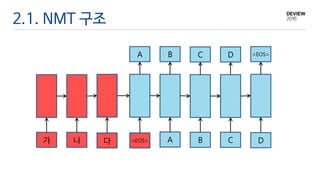
1.3. NMT
Neural MachineTranslation (NMT)
• Neural Network 기반의 Machine Translation
• 두 언어의 Parallel Corpus를 사용하여 Neural Network 학습
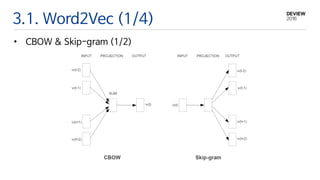
3.1. Word2Vec (2/4)
•CBOW & Skip-gram (2/2)
• 학습 목표 : Average log probability의 극대화(Maximization)
• 극대화 과정에서 Word Vector들이 조정됨.
• 그로 인한 Side-Effect로
Semantic 과 Syntactic 정보가 내재화 됨(Embedded)
14.
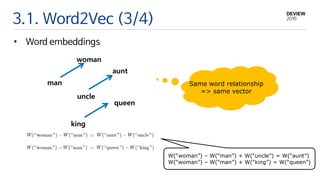
3.1. Word2Vec (3/4)
•Word embeddings
Same word relationship
=> same vector
man
uncle
woman
aunt
queen
king
W(“woman”) – W(“man”) + W(“uncle”) = W(“aunt”)
W(“woman”) – W(“man”) + W(“king”) = W(“queen”)
15.
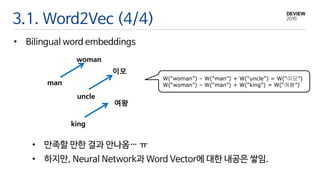
3.1. Word2Vec (4/4)
•Bilingual word embeddings
man
uncle
woman
이모
여왕
king
W(“woman”) – W(“man”) + W(“uncle”) = W(“이모”)
W(“woman”) – W(“man”) + W(“king”) = W(“여왕”)
• 만족할 만한 결과 안나옴… ㅠ
• 하지만, Neural Network과 Word Vector에 대한 내공은 쌓임.
16.
3.2. LSTM LM(1/6)
• Language Model
• 문장(단어 열)의 생성 확률 분포
• Real World의 문장 분포를 기반으로 확률 분포 계산.
• 문장의 확률
• P(sentence) = P(w1,w2,…,wn)
• P(엄마는, 아기를, 매우, 많이, 사랑한다) = 0.000004
• 단어 열의 확률
• P(w5 | w1, w2, w3, w4)
• P(사랑한다 | 엄마는, 아기를, 매우, 많이) = 0.667
• 이 세상의 모든 문장 조합을 구할 수는 없다.
17.
3.2. LSTM LM(2/6)
• n-Gram Language Model
• N-1개의 이전 단어 열을 이용하여 다음 단어를 예측하는 방법.
• P(엄마는, 아기를, 매우, 많이, 사랑한다)
= P(매우 | 엄마는, 아기를) * P(많이 | 아기를, 매우) * P(사랑한다 | 매우, 많이)
18.
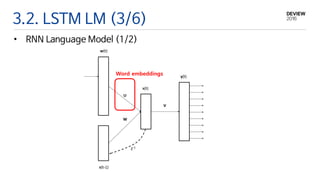
3.2. LSTM LM(3/6)
• RNN Language Model (1/2)
Word embeddings
19.
3.2. LSTM LM(4/6)
• RNN Language Model (2/2)
• “엄마는 아기를 매우 많이 사랑한다”가 학습되어 있으면,
“아빠는 아기를 매우 많이 사랑한다”의 확률을 비교적 높은 정확도로 구할 수 있다.
(엄마와 아빠의 Word embedding이 유사할 것이므로…)
• Data Sparseness 문제 완화
• 더 많은 단어를 보고, 다음 단어의 확률을 구할 수 있다.
20.
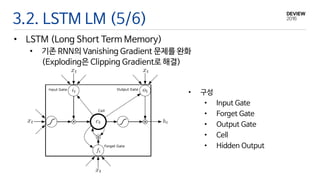
3.2. LSTM LM(5/6)
• LSTM (Long Short Term Memory)
• 기존 RNN의 Vanishing Gradient 문제를 완화
(Exploding은 Clipping Gradient로 해결)
• 구성
• Input Gate
• Forget Gate
• Output Gate
• Cell
• Hidden Output
21.
3.2. LSTM LM(6/6)
• LSTM Language Model
• 친숙해 지기 위해…
• Algorithm 추가 구현해 보기
• Bug Patch
• Performance Tuning
(학습 속도 개선)
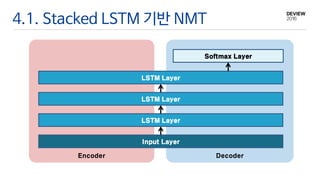
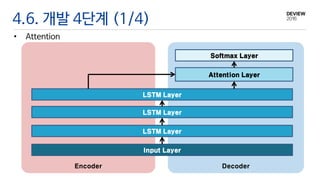
Input Layer
LSTM Layer
LSTM Layer
Softmax Layer
4.2. NMT와 LSTMLM과의 차이
• Encoder와 Decoder로 구성
• 변형 LSTM
• Weight
• Encoder와 Decoder용 각각 존재
• Cell과 Hidden Output은 Encoder와 Decoder가 공유
• Encoder
• 입력 문장을 Encoding
• 입력 문장이 LSTM의 Cell과 Hidden Output 값으로 Vector화
• Decoder
• Vector화 된 입력 문장을 Decoding하면서 번역 수행
• Softmax 연산 수행
25.
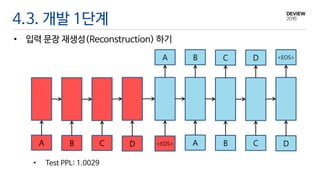
4.3. 개발 1단계
•입력 문장 재생성(Reconstruction) 하기
• Test PPL: 1.0029
D
<EOS>
DC
D
B
C
A
BA
CB <EOS>A
26.
4.4. 개발 2단계
•Small Parallel Corpus로 NMT 만들기 (한국어 -> 영어)
• 수 십만 개의 Parallel 문장
• 약 1,900만 단어 (한국어 + 영어)
• 개발 결과
• 번역 수행 되는것 확인
• 장문에 취약
• 대용량 Corpus를 Training 하기에 너무 오래 걸림
27.
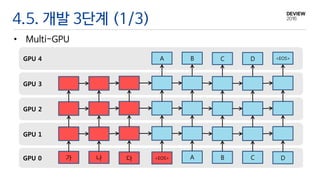
4.5. 개발 3단계(1/3)
• Multi-GPU
GPU 1
GPU 4
GPU 3
GPU 0 다
<EOS>
DC
D
B
C
A
BA
나가 <EOS>
GPU 2
4.5. 개발 3단계(3/3)
• Sampled Softmax (2/2)
• NMT에서 계산량이 가장 많은 부분
• Vocab 개수 증가 -> 계산량 증가
• 해결책
• 학습시 Vocab의 일부만 Sampling하여 학습
• Sampling 방식
• 학습 문장에 포함된 Vocab은 무조건 추가
• 그 외의 Vocab은 Random으로 추가
4.6. 개발 4단계(2/4)
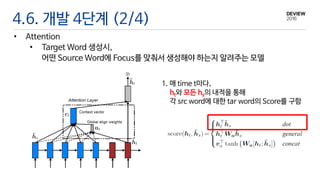
• Attention
• Target Word 생성시,
어떤 Source Word에 Focus를 맞춰서 생성해야 하는지 알려주는 모델
1. 매 time t마다,
ht와 모든 hs의 내적을 통해
각 src word에 대한 tar word의 Score를 구함
32.
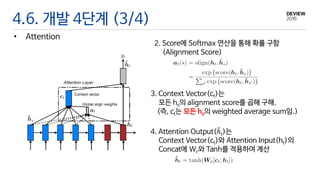
4.6. 개발 4단계(3/4)
• Attention
2. Score에 Softmax 연산을 통해 확률 구함
(Alignment Score)
3. Context Vector(ct)는
모든 hs의 alignment score를 곱해 구해.
(즉, ct는 모든 hs의 weighted average sum임.)
4. Attention Output(ℎt)는
Context Vector(ct)와 Attention Input(ht)의
Concat에 Wc와 Tanh를 적용하여 계산
33.
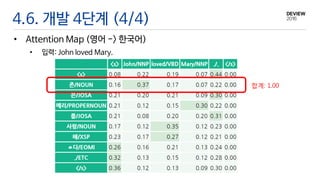
4.6. 개발 4단계(4/4)
• Attention Map (영어 -> 한국어)
• 입력: John loved Mary.
합계: 1.00
5.1. 소개
• N2MT
•NAVER Neural Machine Translation
• NSMT (NAVER Statistical Machine Translation)의 뒤를 잇는
2세대 Machine Translation
• 자체 기술로 개발 (Open Source 기반 아님)
36.
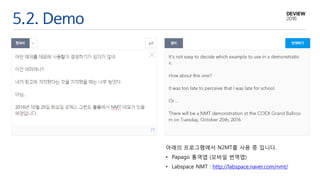
5.2. Demo
아래의 프로그램에서N2MT를 사용 중 입니다.
• Papago 통역앱 (모바일 번역앱)
• Labspace NMT : http://labspace.naver.com/nmt/
37.
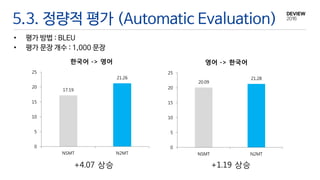
5.3. 정량적 평가(Automatic Evaluation)
• 평가 방법 : BLEU
• 평가 문장 개수 : 1,000 문장
17.19
21.26
0
5
10
15
20
25
NSMT N2MT
한국어 -> 영어
20.09
21.28
0
5
10
15
20
25
NSMT N2MT
영어 -> 한국어
+4.07 상승 +1.19 상승
38.
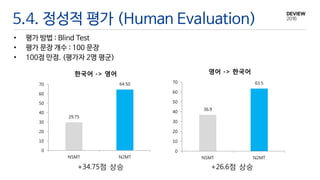
5.4. 정성적 평가(Human Evaluation)
• 평가 방법 : Blind Test
• 평가 문장 개수 : 100 문장
• 100점 만점. (평가자 2명 평군)
29.75
64.50
0
10
20
30
40
50
60
70
NSMT N2MT
한국어 -> 영어
36.9
63.5
0
10
20
30
40
50
60
70
NSMT N2MT
영어 -> 한국어
+34.75점 상승 +26.6점 상승
39.
5.4. 정성적 평가(Human Evaluation)
• 번역 결과 주요 특징
• 완전한 형태의 문장을 생성.
(비문이 생성되는 경우가 거의 없다.)
• 번역 결과가 SMT 대비 많이 우수.
(번역 결과가 틀릴 때는, 아예 딴 소리를 하는 경우도 많음.)
• Vocab 개수의 제약으로, Out Of Vocab 문제가 발생.
6. 마무리하며... (1/2)
•Deep Learning 분야에 많은 개발자들이 필요
• 기존 개발자도 노력하면, 진입할 수 있는 분야.
• 꼼꼼한 성격
• Bug가 눈에 잘 띄지 않는다.
• 학습이 제대로 안될뿐...
• 많은 인내심 필요
• 뭐 하나 고치면, 결과 보는데 몇 시간씩 걸린다.
• 개발 코드량은 얼마 되지 않는다.
42.
6. 마무리하며... (2/2)
•모든 팀원들이 같은 주특기를 갖고 있는 것 보단,
여러 가지 주특기를 갖고 있는 사람들이 Harmony를 이루면 더 강력한 팀이 됨.
• 네이버 Papago팀 =
기계번역 전문가 + Neural Network 전문가 + 시스템 전문가
• 많은 분들이 도전하셔서, 더 재미있고 좋은 세상을 만들었으면 좋겠습니다.
43.
References (1/2)
• Word2Vec& Neural Network Language Model
• Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in
Vector Space. In Proceedings of Workshop at ICLR, 2013.
• Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed Representations of
Words and Phrases and their Compositionality. In Proceedings of NIPS, 2013.
• Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic Regularities in Continuous Space Word
Representations. In Proceedings of NAACL HLT, 2013.
• LSTM
• A. Graves. Generating sequences with recurrent neural networks. In Arxiv preprint arXiv:1308.0850, 2013.
• NMT - Encoder/Decoder Model
• I. Sutskever, O. Vinyals, and Q. V. Le. Sequence to sequence learning with neural networks. In NIPS, 2014
• Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua
Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In
EMNLP, 2014
• Kyunghyun Cho, van Merri¨enboer, B., Bahdanau, D., and Bengio, Y. On the properties of neural machine
translation: Encoder–Decoder approaches. In Eighth Workshop on Syntax, Semantics and Structure in
Statistical Translation. to appear. 2014
• N. Kalchbrenner and P. Blunsom. Recurrent continuous translation models. In EMNLP, 2013
44.
References (2/2)
• NMT- Attention
• Luong, Minh-Thang, Pham, Hieu, and Manning, Christopher D. Effective approaches to attentionbased
neural machine translation. Proceedings of EMNLP, 2015.
• D. Bahdanau, K. Cho, and Y. Bengio. Neural machine translation by jointly learning to align and translate. In
ICLR, 2015
• NMT - Sampled Softmax
• S´ebastien Jean, Kyunghyun Cho, Roland Memisevic, and Yoshua Bengio. On using very large target
vocabulary for neural machine translation. In ACL, 2015
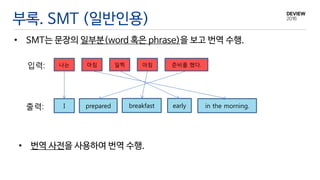
부록. SMT (일반인용)
•SMT는 문장의 일부분(word 혹은 phrase)을 보고 번역 수행.
입력:
출력: I
나는 아침 일찍 아침 준비를 했다.
prepared breakfast early in the morning.
• 번역 사전을 사용하여 번역 수행.
48.
부록. SMT (일반인용)
•번역 사전
한국어 영어 비고
나는 I
아침 in the morning 동음이의어
아침 breakfast 동음이의어
일찍 early
준비를 했다. prepared
• 두 언어의 말뭉치(Parallel Corpus)에서 통계 정보를 사용하여 구축.
• 통계 정보에 기반하므로,
의미 정보 보다는 단어의 출현 빈도만을 기반으로 번역 사전을 구축하게 됨.
(정확도 부족)
49.
부록. SMT (일반인용)
•형태가 비슷한 언어 -> 높은 번역 정확도를 보임
• 한국어 / 일본어
• 영어 / 프랑스어
• 형태가 많이 다른 언어 -> 번역 정확도 미흡
• 한국어 / 영어
50.
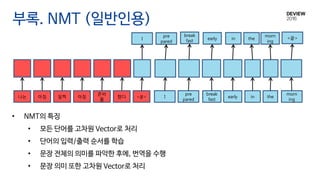
부록. NMT (일반인용)
pre
pared
I
morn
ing
break
fast
earlyin the나는 아침 일찍 아침
준비
를
했다 <끝>
pre
pared
I
morn
ing
break
fast early in the <끝>
• NMT의 특징
• 모든 단어를 고차원 Vector로 처리
• 단어의 입력/출력 순서를 학습
• 문장 전체의 의미를 파악한 후에, 번역을 수행
• 문장 의미 또한 고차원 Vector로 처리
51.
부록. NMT (일반인용)
•모든 단어와 문장을 Vector로 처리
• 단어의 입력/출력 순서를 학습
• 매끄러운 번역 문장 생성.
• 문장 Vector 기반
• 동음이의어라 하더라도, 전체 문장의 의미에 맞게 번역 가능
• 문장 Vector 정확도 하락 -> 번역 정확도 하락
• 문장 Vector 해석 정확도 하락 -> 번역 정확도 하락



















![4.5. 개발 3단계 (2/3)
• Sampled Softmax (1/2)
LSTM Output
Hidden Size
(1,000)
Softmax Weight
HiddenSize
(1,000)
Vocab Size
(50,000)
x
• Matrix 연산 크기
• [50,000 * 1,000][1,000 * 1] = [50,000 * 1]](https://image.slidesharecdn.com/224backendneuralmachinetranslation-161025025107/85/224-backend-neural-machine-translation-28-320.jpg)




















![[134]papago 김준석](https://cdn.slidesharecdn.com/ss_thumbnails/134papago-161023163724-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]대용량 텍스트마이닝 기술 하정우](https://cdn.slidesharecdn.com/ss_thumbnails/226-161025031656-thumbnail.jpg?width=640&height=640&fit=bounds)




![[216]딥러닝예제로보는개발자를위한통계 최재걸](https://cdn.slidesharecdn.com/ss_thumbnails/216-161025031655-thumbnail.jpg?width=640&height=640&fit=bounds)



![[221] 딥러닝을 이용한 지역 컨텍스트 검색 김진호](https://cdn.slidesharecdn.com/ss_thumbnails/221-161025004534-thumbnail.jpg?width=640&height=640&fit=bounds)
![[222]딥러닝을 활용한 이미지 검색 포토요약과 타임라인 최종 20161024](https://cdn.slidesharecdn.com/ss_thumbnails/22220161024-161025034006-thumbnail.jpg?width=640&height=640&fit=bounds)








![[D2 CAMPUS] 분야별 모임 '보안' 발표자료](https://cdn.slidesharecdn.com/ss_thumbnails/random-170117071928-thumbnail.jpg?width=640&height=640&fit=bounds)



![[222]neural machine translation (nmt) 동작의 시각화 및 분석 방법](https://cdn.slidesharecdn.com/ss_thumbnails/222neuralmachinetranslationnmt-171016102621-thumbnail.jpg?width=640&height=640&fit=bounds)















![[싸이그램즈 2018] 텍스트 데이터 전처리로 시작하는 NLP](https://cdn.slidesharecdn.com/ss_thumbnails/psygramsnlp101-180704045500-thumbnail.jpg?width=640&height=640&fit=bounds)

![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)