Abstract
Neural Module Network
Learningto compose Neural Networks for Question Answering
VQA는 이미지와 이미지에 대한 비공식적인 질문을 포함하는 데이터셋
앞의 두 가지의 논문은 Jacob Andreas가 VQA작업을 위해 제한한 아키텍처
후자의 논문은 NMN에서 개선된 아키텍처임
1. 학습이 가능한 뉴럴 네트워크 Layout Predictor를 제안
2. 이미지에서만 사용이 가능한 Visual Primitive를 knowledge base에 대해서도 추론이 가능하게
2
3.
Neural Module Network
특징
논문에서제시한 NMN(Neural Module Network)의 특징 중 하나는 구조가 전통적인 신경망
모델처럼 하나가 아닌 모듈형태의 네트워크로 구성된다는 점.
VQA데이터 셋을 기반으로 각 질문에 대한 네트워크를 정의하고 접근함
NMN모델의 네트워크는 질문의 언어 구조에 따라 동적으로 생성됨
3
4.
Neural Module Network
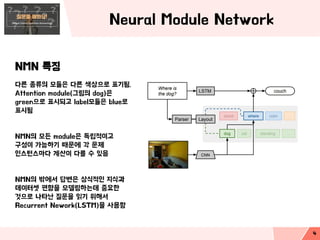
NMN특징
다른 종류의 모듈은 다른 색상으로 표기됨.
Attention module(그림의 dog)은
green으로 표시되고 label모듈은 blue로
표시됨
NMN의 모든 module은 독립적이고
구성이 가능하기 때문에 각 문제
인스턴스마다 계산이 다를 수 있음
NMN의 밖에서 답변은 상식적인 지식과
데이터셋 편향을 모델링하는데 중요한
것으로 나타난 질문을 읽기 위해서
Recurrent Nework(LSTM)을 사용함
4
5.
Training Data Input
TrainingData Input
Training data 항목은 3-tuple형태의 (w, x, y)를
사용함
W : natural-language question
X : image
Y : answer
모델은 모듈 {m}의 집합과 각각 연관된 매개변수
theta(오른쪽 그림에서는 W) 와 string에서
network로 매핑하는 network layout predictor P로
구성됨
모델은 P(w)를 기반으로 네트워크를 인스턴스화하고 x를
입력으로 전달한 이후에 레이블을 통해 분포를 얻어냄
(ex. VQA작업을 위해서 출력 모듈을 Classifier로 설정)
5
6.
Modules
Modules
목표는 작업에 필요한모든 구성으로 assemble할 수 있는 모듈 셋을 식별하는 것. 이는 최소한의
조합 가능한 vision primitive 요소 식별에 해당
Module들은 3가지의 basic data type에 대해서 operation을 수행
A. Images
B. Unnormalized attention
C. Labels
TYPE[INSTANCE](ARG, …)
A. TYPE : high-level module type(Attention, Re-Attention, …)
B. INSTANCES : particular instance of model under consideration
6
7.
Attention module
Attention Module
Attend모듈 attend[c] 은 입력 이미지의 모든 위치를 heatmap 또는 unnormalized
attention을 생성하기 위해서 weight vector(각각의 C에 대해 구별됨. Ex. cat, dog, …)로
convolution을 수행
그림에서 고양이가 들어 있는 이미지의 영역이 존재해야 하고 나머지는 구별되게 끔
7
8.
Re-attention module
Re-Attention Module
re-attend모듈은MLP와 ReLU로 구성되어 있고 하나의 attention에서 다른 attention으로
mapping을 수행하는 역할을 갖음
Mapping을 수행할 때 weight는 각각의 attend모듈과 마찬가지로 C마다 구별된다는 것을 기억
Ex) re-attend[above]는 above라는 단어처럼 그림의 위의 방향으로 이동해서 attention을
수행
8
9.
Combination module
Combination Module
Combine모듈은2가지의 attention을 하나의 attention으로 merge하는 기능을 갖음
Ex) Combine[and] 같은 경우는 두 개의 input에서 모두 activation되어 있는 영역만을
결과물로 activation시킴
Ex) Combine[except]의 경우는 두 가지의 input 중에서 첫번째의 input이 activation된
region과 두번째 input의 activation을 inactive하게 변경시켜서 결과물을 얻어냄
9
String to networks
Stringto Network
Natural language질문에서 인스턴스화 된 신경망으로의 변환은 크게 2가지 스텝을 갖음
A. Natural language질문에서 Layout으로 mapping을 수행함 :
: 주어진 질문에 대답하는데 사용이 되는 모듈의 세트들과 모듈들 간에 연결을 지정하는 역할
B. 이렇게 만들어진 Layout을 사용해서 예측 네트워크를 assemble함
12
13.
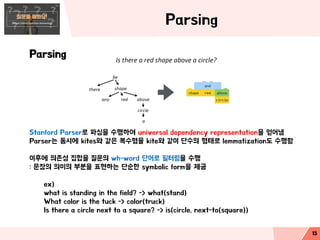
Parsing
Parsing
Stanford Parser로 파싱을수행하여 universal dependency representation을 얻어냄
Parser는 동시에 kites와 같은 복수형을 kite와 같이 단수의 형태로 lemmatization도 수행함
이후에 의존성 집합을 질문의 wh-word 단어로 필터링을 수행
: 문장의 의미의 부분을 표현하는 단순한 symbolic form을 제공
ex)
what is standing in the field? -> what(stand)
What color is the tuck -> color(truck)
Is there a circle next to a square? -> is(circle, next-to(square))
13
14.
Layout
Layout
모든 leaf는 attendmodule, internal nodes는 re-attend 혹은 combine module, root
node는 YES/NO를 대답하는 QA태스크에서는 measure module로 나머지 QA의 경우는
classify module로 연결
Parameter는 연결되어 있음
동일한 high-level 구조를 갖지만 개별 모듈들의 다른 instance들은 동일하게 batch처리가
가능하기 때문에 효율적
ex. “what color is the cat?” -> classify[color](attend[cat]),
“where is the truck?” -> classify[where](attend[truck]))
14
15.
Answering natural
language questions
LSTMquestion Encoder
A. parser만 사용하는 경우 질문을 단순화하기 때문에 문제의 의미를 실질적으로 바꾸지 않지만 응답에 영향을
줄 수 있는 문법적인 단서가 폐기됨
ex) “What is flying”, “What are flying?” -> what(fly)로 convert됨.
하지만 정답은 각각 kites와 kite가 되어야 함
=> question encoder는 데이터의 syntactic(구문론) regularities를 모델링하게
설정함
B. semantic(의미론) regularities을 포착할 수 있음.
ex) “what color is the bear?”라는 질문을 일반적인 “bear”라고 대답하는 것이 합리적임.
“green”이라고 추론하는 것인 이상함
=> question encode는 이런 종류의 효과. 즉, semantic(의미론) regularities를 모델링할 수 있음
15
16.
Answering natural
language questions
LSTMquestion Encoder
A. parser만 사용하는 경우 질문을 단순화하기 때문에 문제의 의미를 실질적으로 바꾸지 않지만 응답에 영향을
줄 수 있는 문법적인 단서가 폐기됨
ex) “What is flying”, “What are flying?” -> what(fly)로 convert됨.
하지만 정답은 각각 kites와 kite가 되어야 함
=> question encoder는 데이터의 syntactic(구문론) regularities를 모델링하게
설정함
B. semantic(의미론) regularities을 포착할 수 있음.
ex) “what color is the bear?”라는 질문을 일반적인 “bear”라고 대답하는 것이 합리적임.
“green”이라고 추론하는 것인 이상함
=> question encode는 이런 종류의 효과. 즉, semantic(의미론) regularities를 모델링할 수 있음
최종모델은
Neural Module Network
의 Output과
LSTM question
Encoder를
결합
16
17.
Answering natural
language questions
1024hidden unit을 갖는 standard
single-layer LSTM을 사용
Question modeling의 구성요소는
NMN의 root module과 같이 대답에
대한 분포를 예측함. 모델로부터 최종
예측은 두 확률 분포의 geometry
average이고, text 및 image
feature를 사용해서 동적으로 다시
reweighted됨
NMN과 sequence modeling 구성
요소를 포함한 전체 모델을 공동으로
학습
17
18.
Training
Optimizer
질문에 대답하는데 사용되는dynamic network structure 때문에 일부 weigh는 다른 것보다 자주
업데이트되는 경향이 있음. 이러한 이유 때문에 adaptive per-weight learning rate를 갖는
알고리즘이 단순한 SGD보다 좋은 성능을 내는 것을 확인함.
그래서 AdaDelta를 사용하여 접근
기억할 점
detect[cat] 은 고양이 인식기로 고정되거나 초기화되지 않으며 combine[and]는 attention의
교집합을 계산하기 위해서 고정되는 것이 아니라는 것을 기억해야 함
End-to-End방식의 학습과정의 결과물로 이러한 behavior를 습득함.
18






A. TYPE : high-level module type(Attention, Re-Attention, …)
B. INSTANCES : particular instance of model under consideration
6](https://image.slidesharecdn.com/neuralmodulenetworkpaulkim-190123111310/85/Neural-module-Network-6-320.jpg)
![Attention module
Attention Module
Attend 모듈 attend[c] 은 입력 이미지의 모든 위치를 heatmap 또는 unnormalized
attention을 생성하기 위해서 weight vector(각각의 C에 대해 구별됨. Ex. cat, dog, …)로
convolution을 수행
그림에서 고양이가 들어 있는 이미지의 영역이 존재해야 하고 나머지는 구별되게 끔
7](https://image.slidesharecdn.com/neuralmodulenetworkpaulkim-190123111310/85/Neural-module-Network-7-320.jpg)
![Re-attention module
Re-Attention Module
re-attend모듈은 MLP와 ReLU로 구성되어 있고 하나의 attention에서 다른 attention으로
mapping을 수행하는 역할을 갖음
Mapping을 수행할 때 weight는 각각의 attend모듈과 마찬가지로 C마다 구별된다는 것을 기억
Ex) re-attend[above]는 above라는 단어처럼 그림의 위의 방향으로 이동해서 attention을
수행
8](https://image.slidesharecdn.com/neuralmodulenetworkpaulkim-190123111310/85/Neural-module-Network-8-320.jpg)
![Combination module
Combination Module
Combine모듈은 2가지의 attention을 하나의 attention으로 merge하는 기능을 갖음
Ex) Combine[and] 같은 경우는 두 개의 input에서 모두 activation되어 있는 영역만을
결과물로 activation시킴
Ex) Combine[except]의 경우는 두 가지의 input 중에서 첫번째의 input이 activation된
region과 두번째 input의 activation을 inactive하게 변경시켜서 결과물을 얻어냄
9](https://image.slidesharecdn.com/neuralmodulenetworkpaulkim-190123111310/85/Neural-module-Network-9-320.jpg)
![Classification Module
Classification Module
Classification모듈은 attention과 input이미지를 각각의 라벨에 대한 분포로 매핑을 수행
Ex) Classify[color]는 color의 특정 region의 attention을 수행하면서 라벨에 대한 분포를
리턴함
10](https://image.slidesharecdn.com/neuralmodulenetworkpaulkim-190123111310/85/Neural-module-Network-10-320.jpg)


,
“where is the truck?” -> classify[where](attend[truck]))
14](https://image.slidesharecdn.com/neuralmodulenetworkpaulkim-190123111310/85/Neural-module-Network-14-320.jpg)



![Training
Optimizer
질문에 대답하는데 사용되는 dynamic network structure 때문에 일부 weigh는 다른 것보다 자주
업데이트되는 경향이 있음. 이러한 이유 때문에 adaptive per-weight learning rate를 갖는
알고리즘이 단순한 SGD보다 좋은 성능을 내는 것을 확인함.
그래서 AdaDelta를 사용하여 접근
기억할 점
detect[cat] 은 고양이 인식기로 고정되거나 초기화되지 않으며 combine[and]는 attention의
교집합을 계산하기 위해서 고정되는 것이 아니라는 것을 기억해야 함
End-to-End방식의 학습과정의 결과물로 이러한 behavior를 습득함.
18](https://image.slidesharecdn.com/neuralmodulenetworkpaulkim-190123111310/85/Neural-module-Network-18-320.jpg)







![[컴퓨터비전과 인공지능] 7. 합성곱 신경망 2](https://cdn.slidesharecdn.com/ss_thumbnails/lec7convolutionnetworks2-210213150820-thumbnail.jpg?width=640&height=640&fit=bounds)










![[컴퓨터비전과 인공지능] 8. 합성곱 신경망 아키텍처 5 - Others](https://cdn.slidesharecdn.com/ss_thumbnails/lec8convolutionnetworksarcitecture5others-210215060452-thumbnail.jpg?width=640&height=640&fit=bounds)
![[스프링 스터디 1일차] 템플릿](https://cdn.slidesharecdn.com/ss_thumbnails/0ik3cjatjavaqqyrb8cl-signature-d53fe98faa10235f97293b3ac37b6748da06835df43b7af4e7632fe535e72c12-poli-170706090018-thumbnail.jpg?width=640&height=640&fit=bounds)

![[컴퓨터비전과 인공지능] 10. 신경망 학습하기 파트 1 - 2. 데이터 전처리](https://cdn.slidesharecdn.com/ss_thumbnails/lec10trainingneuralnetworkspart12datapreprocessing-210223065837-thumbnail.jpg?width=640&height=640&fit=bounds)







![[224] backend 개발자의 neural machine translation 개발기 김상경](https://cdn.slidesharecdn.com/ss_thumbnails/224backendneuralmachinetranslation-161025025107-thumbnail.jpg?width=640&height=640&fit=bounds)






















