Show and Tell:Lessons learned from the 2015
MSCOCO Image Captioning Challenge
IEEE Transactions on Pattern analysis and Machine Learning (2016)
Oriol Vinyals, Alexander Toshev, Dumitru Erhan and Samy Bengio (Google Inc.)
자연어처리연구실
발표자: 허광호
Show and Tell: A Neural Image Caption Generator (CVPR 2015, Google Inc. 830 citations)
Oriol Vinyals
Alexander Toshev Dumitru Erhan Samy Bengio
1
2.
Image Captioning
• Givenan input image, describe the content of an image using properly formed
natural language like English.
• This task is significantly harder than image classification or object recognition task.
• 1) A description must capture not only the objects, (물체 인식)
• 2) it also must express how these objects relate to each other, (물체들 사이의 관계)
• 3) as well as their attributes (물체의 속성: 색상, 모양)
• 4) and the activities they are involved in (물체들의 행위)
입력이미지
자연어출력
The above semantic knowledge has
to be expressed in a natural
language like English.
2
3.
Neural Image Caption(NIC Model)
• Present a single joint model
• 이미지 𝐼를 입력으로 받아, Likelihood 𝑝(𝑆|𝐼)를 최대로 하는 문장 𝑆 = {𝑆1, 𝑆2, …𝑆 𝑛}를
출력하도록 학습함.
• Inspiration comes from machine translation
• DNN을 사용하기 전 기계번역 방법은 여러 개의 독립적인 task로 나누어서 해결
• (e.g. translating words individually, aligning words, reordering, etc.)
• 최근 기계번역에서 RNN을 사용하여 간결한 방법으로 state-of-the-art 성능.
S RNN
“encoder”
Fixed-length
VectorRNN
“decoder”
T
RNN 기계번역
NIC 모델
3
4.
Related Works
• Objects사이의 관계 triplet을 찾고 templates을 이용하여 text 생성. (Farhadi et al. 2010)
• 좀 더 복잡한 Graph로 triplet을 대체 후 template-based text generation. (Kulkani et al. 2011)
• Language parsing기반 language model로 template-based 대체. (논문 5개, 2010~2013)
• Co-embedding of images and text in the same vector space. (논문 5개, 2013~2015)
• Or even image crops (부분 이미지) and sub-sentences (부분 문장).
• 논문에서 주장하는 가장 큰 구별점
• Visual input을 RNN모델에 직접 연결하여, RNN모델이 text에 언급된 objects를 추적할 수 있게 함.
• 이와 유사한 방법들을 심도 있게 분석한 논문 Devlin et al. (ACL 2015)
Heavily hand-designed and rigid.
Do not attempt to generate novel descriptions.
4
5.
Model Architecture (1)
•Generate descriptions from image in “end-to-end” fashion.
• RNN 모델 → ℎ 𝑡+1 = 𝑓(ℎ 𝑡, 𝑥𝑡)
• 1) non-linear function 𝑓 를 어떻게 선택할 것인가?
• Long-Short Term Memory (LSTM) 사용
• 2) 이미지와 단어를 어떻게 입력 𝑥𝑡로 표현할 것인가?
• 이미지는 CNN (ILSVRC 2014 competition에서 우승한 모델)
• 단어는 word embedding (word2vec)
일반적인 language model과 매우 유사
𝑝(𝑆|𝐼)를 RNN으로 모델링 할 수 있음.
5
6.
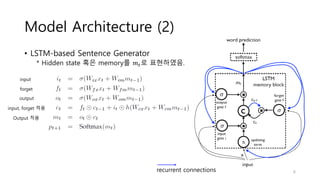
Model Architecture (2)
•LSTM-based Sentence Generator
* Hidden state 혹은 memory를 𝑚 𝑡로 표현하였음.
input
forget
output
input, forget 적용
Output 적용
recurrent connections 6
7.
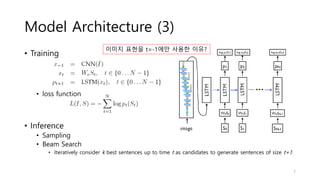
Model Architecture (3)
•Training
• loss function
• Inference
• Sampling
• Beam Search
• Iteratively consider k best sentences up to time t as candidates to generate sentences of size t+1.
이미지 표현을 t=-1에만 사용한 이유?
7
8.
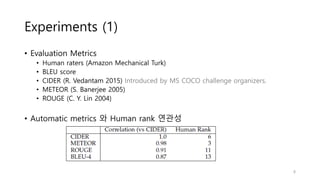
Experiments (1)
• EvaluationMetrics
• Human raters (Amazon Mechanical Turk)
• BLEU score
• CIDER (R. Vedantam 2015) Introduced by MS COCO challenge organizers.
• METEOR (S. Banerjee 2005)
• ROUGE (C. Y. Lin 2004)
• Automatic metrics 와 Human rank 연관성
8
9.
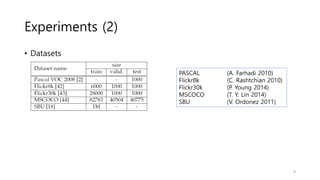
Experiments (2)
• Datasets
PASCAL(A. Farhadi 2010)
Flickr8k (C. Rashtchian 2010)
Flickr30k (P. Young 2014)
MSCOCO (T. Y. Lin 2014)
SBU (V. Ordonez 2011)
9
10.
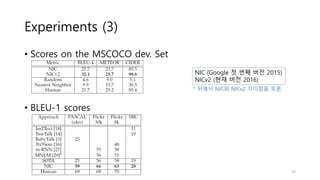
Experiments (3)
• Scoreson the MSCOCO dev. Set
• BLEU-1 scores
NIC (Google 첫 번째 버전 2015)
NICv2 (현재 버전 2016)
* 뒤에서 NIC와 NICv2 차이점을 토론.
10
11.
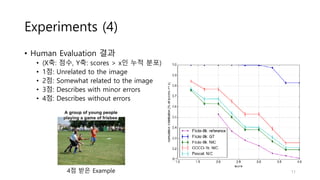
Experiments (4)
• HumanEvaluation 결과
• (X축: 점수, Y축: scores > x인 누적 분포)
• 1점: Unrelated to the image
• 2점: Somewhat related to the image
• 3점: Describes with minor errors
• 4점: Describes without errors
4점 받은 Example 11
12.
Generation Diversity
• GenerationDiversity에 관한 질문
• 1) whether the model generates novel captions?
• 2) whether the generated captions are diverse and high quality?
• 실험에서 얻은 결과
• Best 문장 하나만 고려할 경우 training set caption과 80%가 겹침.
• Top 15개 문장을 고려할 경우 50% 정도의 novel description을 생성할 수 있음.
12
13.
Improvements Over CVPR15Model (1)
• 새로 적용한 기법과 향상된 BLEU-4 성능
• Image Model Improvement (+2% BLUE-4)
• 당시 GoogleLeNet 모델을 사용함. (22 layers, 2014 ImageNet competition 우승)
• 나중에 “Batch Normalization” 기법을 적용하여
• ImageNet task에서 top-5 error가 6.67%에서 4.8%로 감소 (2% 향상)
• Batch Normalization (S. Ioffe 2015)
• Normalize each layer of a neural network with respect to the current batch of example.
13
14.
Improvements Over CVPR15Model (2)
• Image Model Fine Tuning (+1% BLUE-4)
• 기존 CNN 모델은 ImageNet에서 학습한 params를 고정하였고 (For generalization)
• LSTM params만 MS COCO 데이터로 훈련.
• NICv2에서 CNN모델을 MS COCO데이터로 Fine tuning.
• Fine tuning할 때 발견한 점.
• LSTM의 params를 일정한 수준까지 학습하고 안정된 후 CNN Fine tuning 수행.
• Why? → LSTM의 initial gradients가 pre-trained CNN params를 corrupt시킴.
• 1) CNN params을 freezing 후 500K steps을 학습하고
• 2) CNN과 LSTM을 100K steps만큼 joint 학습함.
• 1 step당 3초 정도 걸려 총 3주정도 소요. (Single GPU – Nvidia K20)
• 병렬로 학습할 경우 converge는 빠르나 학습 후 성능이 낮아짐.
• Fine-tuning 후 color feature를 더 잘 catch하여 “A blue and yellow train…” 문장 출력
14
15.
Improvements Over CVPR15Model (3)
• Scheduled Sampling (+1.5% BLEU-4) (S. Bengio NIPS 2015)
• LSTM 모델의 학습과정과 Inference과정에 차이가 존재
• 𝑝 𝑆𝑡 𝑆1, 𝑆2, … , 𝑆𝑡−1
• 𝑆𝑡를 학습할 때 조건으로 하는 Previous words (𝑆1, 𝑆2, … , 𝑆𝑡−1)은 모두 정답임.
• 그러나 Inference단계에서는 기존에 생성한 단어를 previous words로 할 수밖에 없음.
• 이를 해결하기 위하여 Curriculum learning strategy를 도입.
• 정답 previous words로 Fully guided scheme로 학습하는 기존 방식에서
• 생성한 previous words로 Less guided scheme로 학습하도록 변경함
15
16.
Improvements Over CVPR15Model (4)
• Ensemble (+1.5% BLEU)
• 5 models trained with Scheduled Sampling.
• 10 models trained with fine-tuning image model.
• Beam Size Reduction (+2% BLUE)
• 기존 Beam Size 20에서 3으로 줄임.
• 일반적으로 large beam size로 학습하면 성능이 높지만, training set을 over-fitting 했다고 함
• Training caption 중복율 80%에서 60%로 감소 (즉 Novel caption이 20% → 40%)
16
Future Works
• “Despitethe exciting results on captioning, we believe it is just the beginning.”
• Have a system which is capable of more targeted descriptions
• anchoring the descriptions to given image properties and locations.
• being a response to a user specified question or task.
• Further research direction
• better evaluation metrics
• evaluation through higher level goals (e.g. application such as robotics)
Tensorflow 소스코드 - https://github.com/tensorflow/models/tree/master/im2txt
18
















































![[부스트캠프 Tech Talk] 배지연_Structure of Model and Task](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkbaejiyeon-211210113740-thumbnail.jpg?width=640&height=640&fit=bounds)











