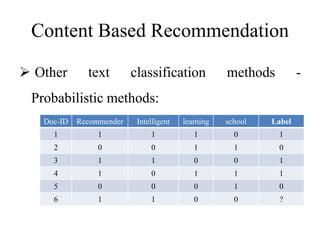
The document discusses content-based recommendation systems. It describes how these systems work by analyzing item content and user preferences to recommend items that match a user's interests. It covers techniques like using TF-IDF to represent items as vectors, calculating similarity between items and profiles to find nearest neighbors, and using machine learning methods like naive Bayes classification. Feature selection methods are also discussed to choose the most useful terms for modeling items and users.




























































![[系列活動] 人工智慧與機器學習在推薦系統上的應用](https://cdn.slidesharecdn.com/ss_thumbnails/merged-161217165734-thumbnail.jpg?width=640&height=640&fit=bounds)













































