Download as PDF, PPTX














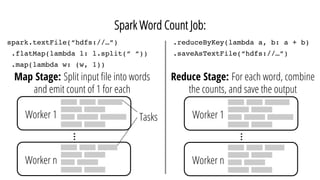
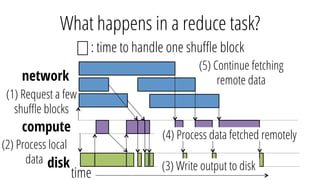
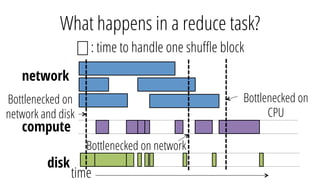
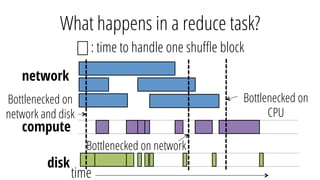
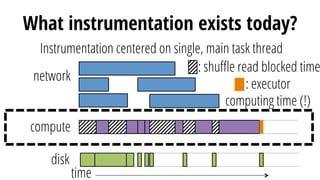
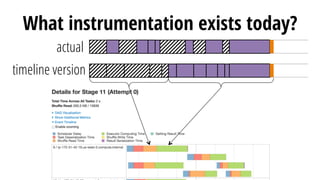

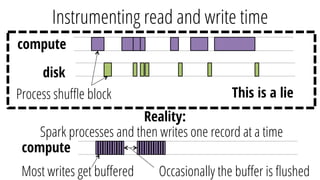



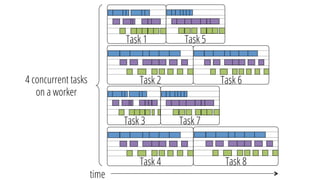
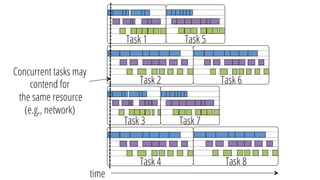
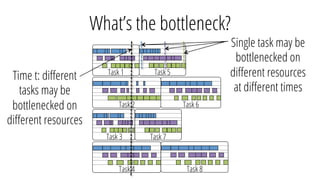
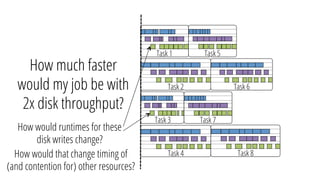

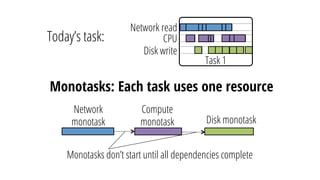
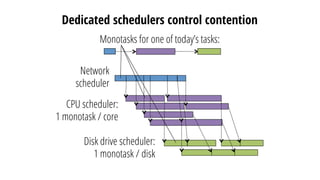
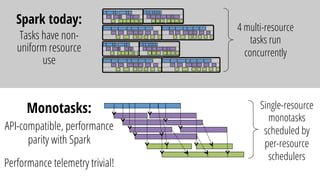
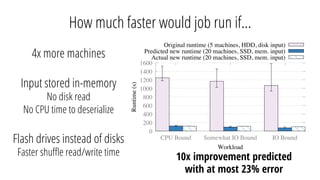


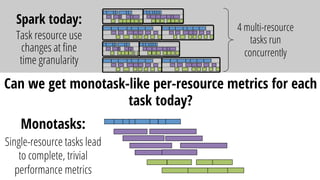
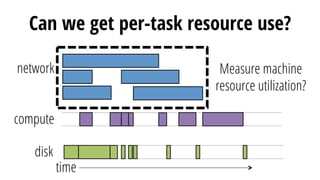
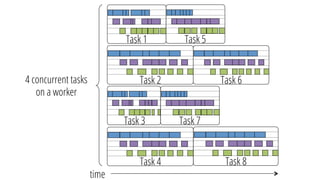
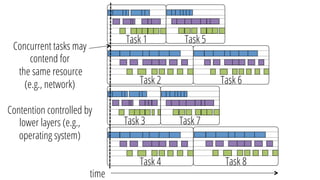
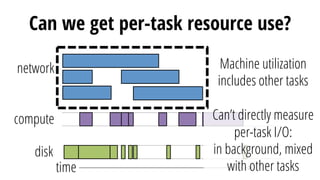
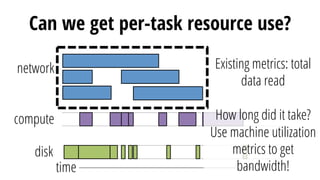




This document discusses improving performance instrumentation in Apache Spark. It summarizes that existing instrumentation focuses on blocked times in the main task thread, but opportunities exist to better instrument read/write times and machine-level resource utilization. The author proposes combining per-task I/O metrics with machine utilization data to provide complete metrics about time spent using each resource on a per-task basis, improving performance clarity for users. More details are available at the listed website.























































































