Download as PDF, PPTX





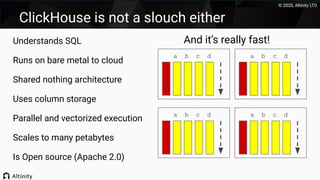
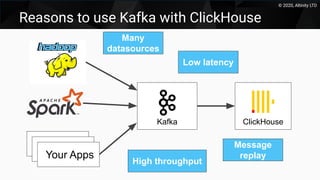

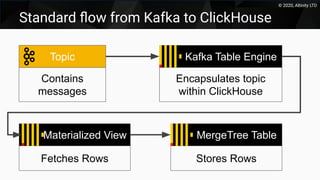

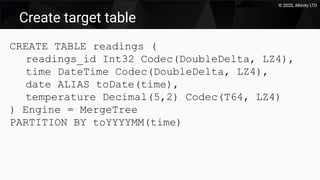



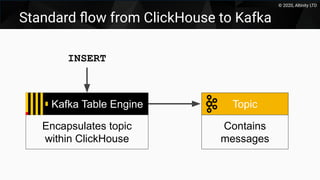




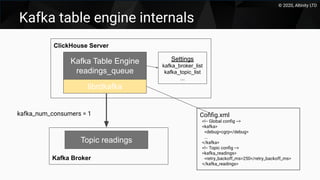






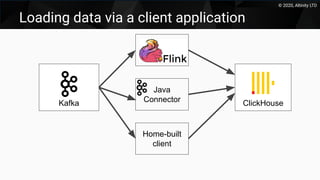





This document discusses using Kafka as a messaging system with ClickHouse for high throughput and low latency data ingestion. It provides an overview of Kafka and how it can be used with ClickHouse, including creating Kafka topics, Kafka and ClickHouse tables, materialized views to transfer data, and best practices. It also covers alternatives to the ClickHouse Kafka engine and the roadmap for further improving the Kafka integration.








































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)














