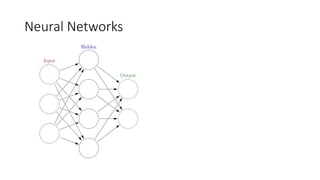
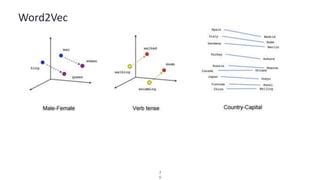
This document discusses GPU programming with Java, focusing on use cases, device types, and Java libraries. Major applications include deep learning and video encoding, with an overview of device pricing for AWS GPU instances. It also covers concepts like term frequency-inverse document frequency (tf-idf) and word2vec in the context of parallel computation and machine learning.











![OpenCL: Example C code
__kernel void matvec(__global const float *A, __global const float *x,
uint ncols, __global float *y)
{
size_t i = get_global_id(0);
__global float const *a = &A[i*ncols];
float sum = 0.f;
for (size_t j = 0; j < ncols; j++) {
sum += a[j] * x[j];
}
y[i] = sum;
}
Source: https://en.wikipedia.org/wiki/OpenCL](https://image.slidesharecdn.com/gpuprogrammingwithjava-180217155834/85/Gpu-programming-with-java-14-320.jpg)
![CPU side
vector<float> h_A(SIZE);
vector<float> h_B(SIZE);
vector<float> h_C(SIZE); // Initialize matrices on the host
for (int i=0; i<N; i++){
for (int j=0; j<N; j++){
h_A[i*N+j] = sin(i); h_B[i*N+j] = cos(j);
}
}
Source: https://www.quantstart.com/articles/Matrix-Matrix-
Multiplication-on-the-GPU-with-Nvidia-CUDA](https://image.slidesharecdn.com/gpuprogrammingwithjava-180217155834/85/Gpu-programming-with-java-15-320.jpg)
![CPU side
// Allocate memory on the device
dev_array<float> d_A(SIZE);
dev_array<float> d_B(SIZE);
dev_array<float> d_C(SIZE);
d_A.set(&h_A[0], SIZE);
d_B.set(&h_B[0], SIZE);
matrixMultiplication(d_A.getData(), d_B.getData(), d_C.getData(), N);
Source: https://www.quantstart.com/articles/Matrix-Matrix-
Multiplication-on-the-GPU-with-Nvidia-CUDA](https://image.slidesharecdn.com/gpuprogrammingwithjava-180217155834/85/Gpu-programming-with-java-16-320.jpg)

![jCuda
int deviceId = 0;
JCudaDriver.setExceptionsEnabled(true);
CUdevice device = new CUdevice();
cuDeviceGet(device, deviceId);
long total[] = new long[]{ 0 };
long free[] = new long[]{ 0 };
cuInit(0);
cuDeviceGet(device, deviceId);
CUcontext context = new CUcontext();
cuCtxCreate(context, 0, device);
cuMemGetInfo(free, total);
cuCtxDestroy(context);](https://image.slidesharecdn.com/gpuprogrammingwithjava-180217155834/85/Gpu-programming-with-java-18-320.jpg)





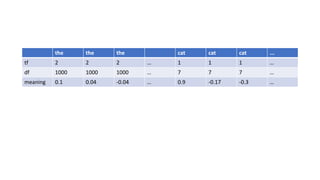
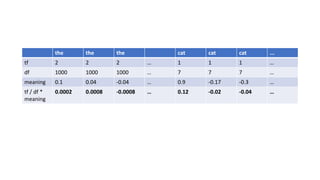
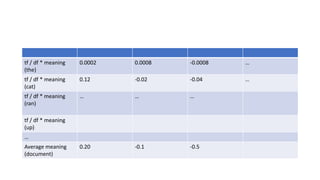
![TF / DF * meaning
Words = [“the”, “cat”, “ran” “up” “the” “hill”]
Term Frequency = [2, 1, 1, 1, 2, 1 ]
Document Frequency = [1000, 7, 57, 50, 1000, 9 ]
Meanings[“the”] = [0.1, 0.04, -0.4, ….]
Meanings[“cat”] = [0.9, -0.17, -0.3, ….]
Meanings[“ran”] = [0.5, 0.1, 0.4, ….]](https://image.slidesharecdn.com/gpuprogrammingwithjava-180217155834/85/Gpu-programming-with-java-25-320.jpg)











![Nd4j – Shape
int[] shape = data.shape();
for (int i = 0; i < shape.length; i++) {
System.out.println(shape[i]);
}
3
1500](https://image.slidesharecdn.com/gpuprogrammingwithjava-180217155834/85/Gpu-programming-with-java-40-320.jpg)

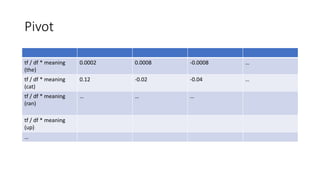
![Multiply TF*IDF and Word2Vec data
INDArray weighted = tfVec.div(dfVec).mul(scoresVec);
shape = wordVects.shape();
for (int i = 0; i < shape.length; i++) {
System.out.println(shape[i]);
}
1
1500](https://image.slidesharecdn.com/gpuprogrammingwithjava-180217155834/85/Gpu-programming-with-java-42-320.jpg)
![Reshape (1 row per word)
INDArray wordVects =
weighted.reshape(
vocabulary.size(),
widthOfWordVector
);
shape = wordVects.shape();
for (int i = 0; i < shape.length; i++) {
System.out.println(shape[i]);
}
5
300](https://image.slidesharecdn.com/gpuprogrammingwithjava-180217155834/85/Gpu-programming-with-java-45-320.jpg)
![Produce Weighted Average
INDArray documentAverage =
wordVects.sum(0).div(vocabulary.size());
shape = documentAverage.shape();
for (int i = 0; i < shape.length; i++) {
System.out.println(shape[i]);
}
1
300](https://image.slidesharecdn.com/gpuprogrammingwithjava-180217155834/85/Gpu-programming-with-java-46-320.jpg)

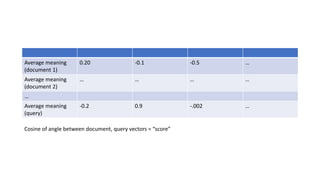
![01
Example: Similarity
Number from [0, 1]
4
9
Image credit: https://engineering.aweber.com/cosine-similarity/](https://image.slidesharecdn.com/gpuprogrammingwithjava-180217155834/85/Gpu-programming-with-java-49-320.jpg)


























![[Pycon 2015] 오늘 당장 딥러닝 실험하기 제출용](https://cdn.slidesharecdn.com/ss_thumbnails/pycon2015-150913033231-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


















































