Download as PDF, PPTX











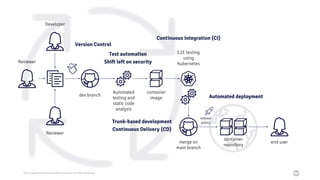

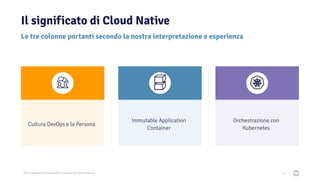

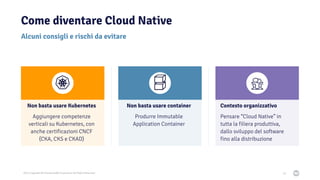

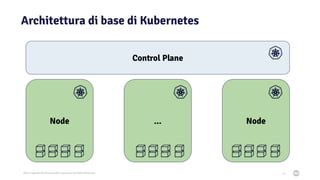




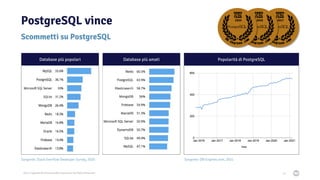




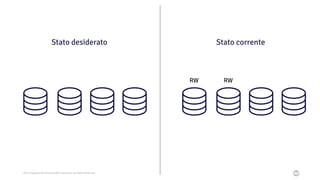






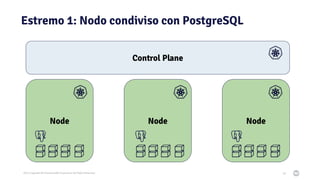
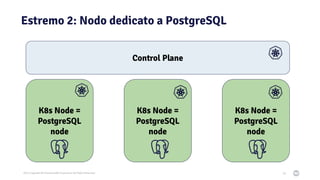

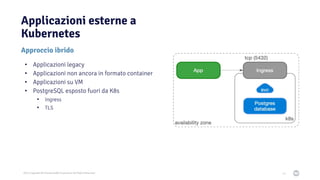
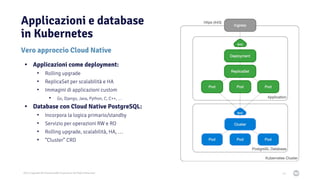

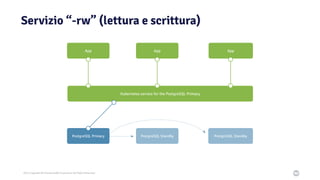
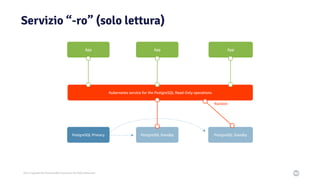




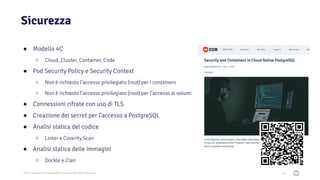


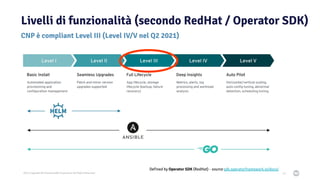

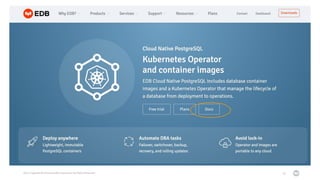









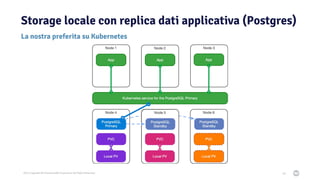










Il documento discute la trasformazione verso un'architettura cloud native utilizzando Kubernetes, concentrandosi sull'integrazione di PostgreSQL in tale contesto. Viene presentata la cultura DevOps e i principi di gestione dei container, evidenziando l'importanza di una mentalità orientata ai container e alle applicazioni immutabili. Inoltre, il testo esplora le caratteristiche e i benefici di Cloud Native PostgreSQL, sottolineando le pratiche di orchestrazione e gestione del database in ambienti Kubernetes.




























































