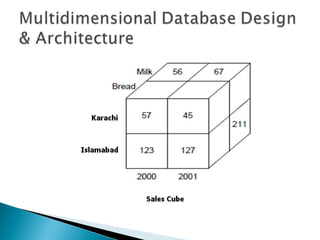
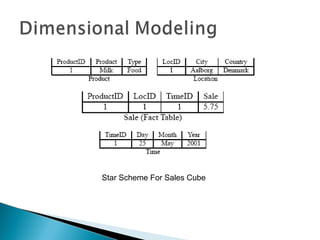
This document discusses multidimensional databases and provides comparisons to relational databases. It describes how multidimensional databases are optimized for data warehousing and online analytical processing (OLAP) applications. Key aspects covered include dimensional modeling using star and snowflake schemas, data storage in cubes with dimensions and members, and performance benefits of multidimensional databases for interactive analysis of large datasets to support decision making.