Downloaded 365 times






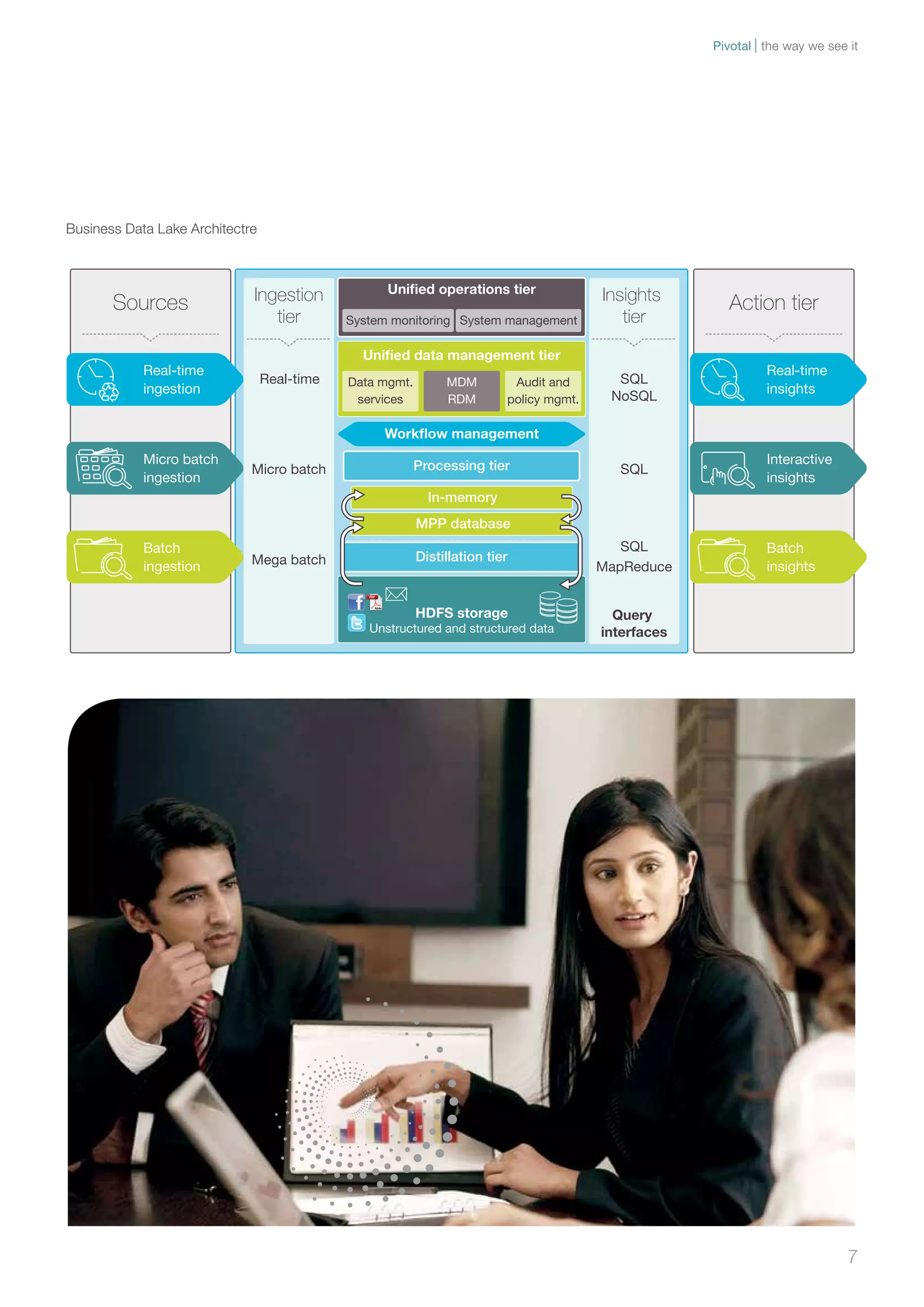


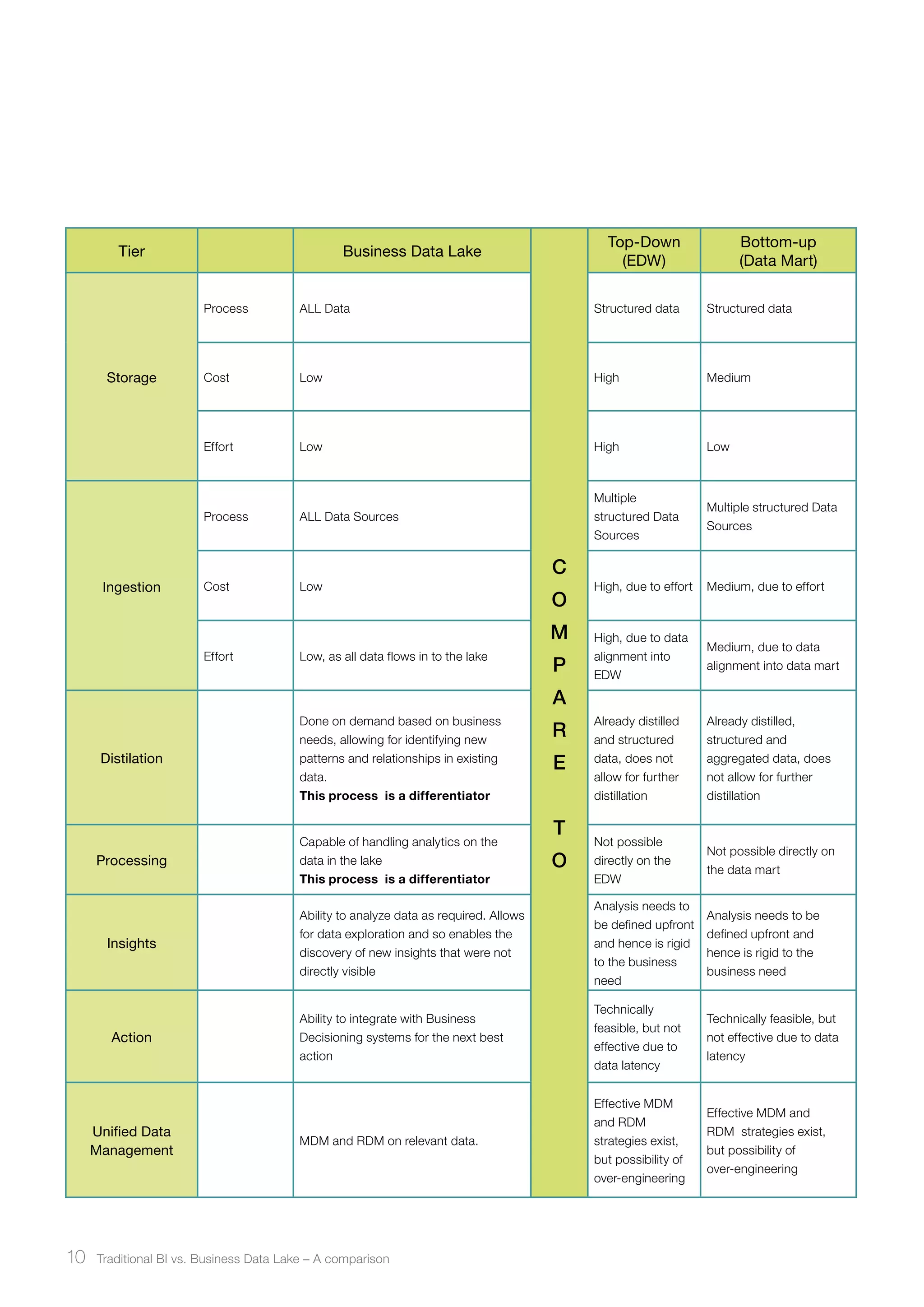



Traditional BI systems have limitations in handling big data as they are not designed for unstructured data and have data latency issues. A business data lake provides a new approach by storing all raw structured and unstructured data in a single environment at low cost. This allows for near real-time analysis on any data from any source to gain insights.






















































































