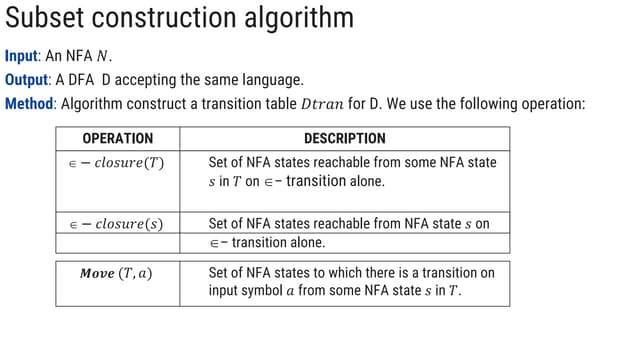
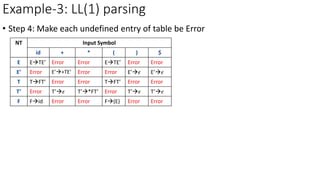
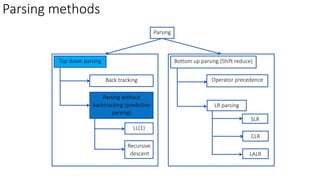
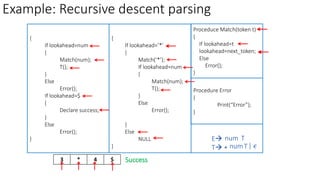
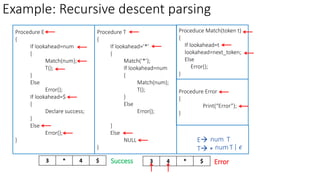
This document describes the steps to construct a LL(1) predictive parsing table. It begins with a grammar and removes left recursion. It then computes the FIRST and FOLLOW sets for each nonterminal. Using these sets, it constructs the predictive parsing table by filling in the entries based on the FIRST of the right side and FOLLOW of the left side nonterminals. The table allows LL(1) parsing by predicting the next move based on the lookahead symbol.

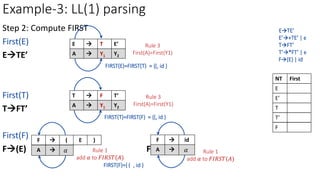
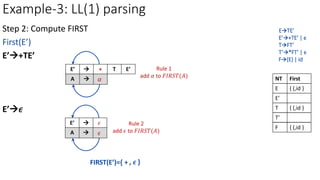
![Example-3: LL(1) parsing
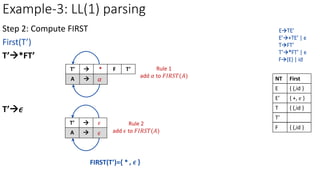
Step 3: Construct predictive parsing table
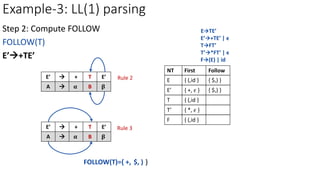
ETE’
a=FIRST(TE’)={ (,id }
M[E,(]=ETE’
M[E,id]=ETE’
NT First Follow
E { (,id } { $,) }
E’ { +, 𝜖 } { $,) }
T { (,id } { +,$,) }
T’ { *, 𝜖 } { +,$,) }
F { (,id } {*,+,$,)}
Rule: 2
A 𝛼
a = first(𝛼)
M[A,a] = A 𝛼
NT Input Symbol
id + * ( ) $
E ETE’ ETE’
E’
T
T’
F
ETE’
E’+TE’ | ϵ
TFT’
T’*FT’ | ϵ
F(E) | id](https://image.slidesharecdn.com/6-practiceproblems-ll1parser-16-05-2023-230707153559-f6a8ac17/85/6-Practice-Problems-LL-1-parser-16-05-2023-pptx-12-320.jpg)
![Example-3: LL(1) parsing
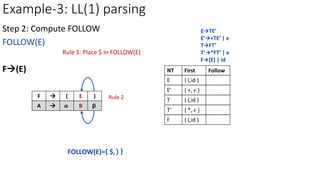
Step 3: Construct predictive parsing table
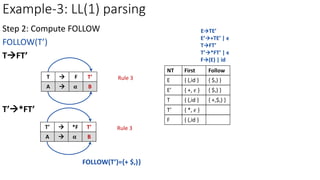
E’+TE’
a=FIRST(+TE’)={ + }
M[E’,+]=E’+TE’
NT Input Symbol
id + * ( ) $
E ETE’ ETE’
E’ E’+TE’
T
T’
F
Rule: 2
A 𝛼
a = first(𝛼)
M[A,a] = A 𝛼
NT First Follow
E { (,id } { $,) }
E’ { +, 𝜖 } { $,) }
T { (,id } { +,$,) }
T’ { *, 𝜖 } { +,$,) }
F { (,id } {*,+,$,)}
ETE’
E’+TE’ | ϵ
TFT’
T’*FT’ | ϵ
F(E) | id](https://image.slidesharecdn.com/6-practiceproblems-ll1parser-16-05-2023-230707153559-f6a8ac17/85/6-Practice-Problems-LL-1-parser-16-05-2023-pptx-13-320.jpg)
![Example-3: LL(1) parsing
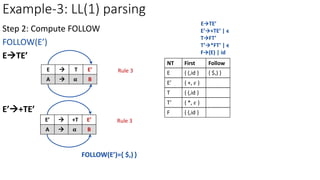
Step 3: Construct predictive parsing table
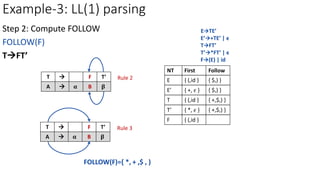
E’𝜖
b=FOLLOW(E’)={ $,) }
M[E’,$]=E’𝜖
M[E’,)]=E’𝜖
NT Input Symbol
id + * ( ) $
E ETE’ ETE’
E’ E’+TE’ E’𝜖 E’𝜖
T
T’
F
Rule: 3
A 𝛼
b = follow(A)
M[A,b] = A 𝛼
NT First Follow
E { (,id } { $,) }
E’ { +, 𝜖 } { $,) }
T { (,id } { +,$,) }
T’ { *, 𝜖 } { +,$,) }
F { (,id } {*,+,$,)}
ETE’
E’+TE’ | ϵ
TFT’
T’*FT’ | ϵ
F(E) | id](https://image.slidesharecdn.com/6-practiceproblems-ll1parser-16-05-2023-230707153559-f6a8ac17/85/6-Practice-Problems-LL-1-parser-16-05-2023-pptx-14-320.jpg)
![Example-3: LL(1) parsing
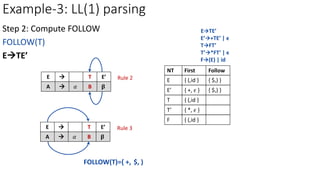
Step 3: Construct predictive parsing table
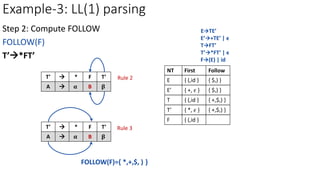
TFT’
a=FIRST(FT’)={ (,id }
M[T,(]=TFT’
M[T,id]=TFT’
NT Input Symbol
id + * ( ) $
E ETE’ ETE’
E’ E’+TE’ E’𝜖 E’𝜖
T TFT’ TFT’
T’
F
NT First Follow
E { (,id } { $,) }
E’ { +, 𝜖 } { $,) }
T { (,id } { +,$,) }
T’ { *, 𝜖 } { +,$,) }
F { (,id } {*,+,$,)}
ETE’
E’+TE’ | ϵ
TFT’
T’*FT’ | ϵ
F(E) | id
Rule: 2
A 𝛼
a = first(𝛼)
M[A,a] = A 𝛼](https://image.slidesharecdn.com/6-practiceproblems-ll1parser-16-05-2023-230707153559-f6a8ac17/85/6-Practice-Problems-LL-1-parser-16-05-2023-pptx-15-320.jpg)
![Example-3: LL(1) parsing
Step 3: Construct predictive parsing table
T’*FT’
a=FIRST(*FT’)={ * }
M[T’,*]=T’*FT’
NT Input Symbol
id + * ( ) $
E ETE’ ETE’
E’ E’+TE’ E’𝜖 E’𝜖
T TFT’ TFT’
T’ T’*FT’
F
Rule: 2
A 𝛼
a = first(𝛼)
M[A,a] = A 𝛼
NT First Follow
E { (,id } { $,) }
E’ { +, 𝜖 } { $,) }
T { (,id } { +,$,) }
T’ { *, 𝜖 } { +,$,) }
F { (,id } {*,+,$,)}
ETE’
E’+TE’ | ϵ
TFT’
T’*FT’ | ϵ
F(E) | id](https://image.slidesharecdn.com/6-practiceproblems-ll1parser-16-05-2023-230707153559-f6a8ac17/85/6-Practice-Problems-LL-1-parser-16-05-2023-pptx-16-320.jpg)
![Example-3: LL(1) parsing
Step 3: Construct predictive parsing table
T’𝜖
b=FOLLOW(T’)={ +,$,) }
M[T’,+]=T’𝜖
M[T’,$]=T’𝜖
M[T’,)]=T’𝜖
NT Input Symbol
id + * ( ) $
E ETE’ ETE’
E’ E’+TE’ E’𝜖 E’𝜖
T TFT’ TFT’
T’ T’𝜖 T’*FT’ T’𝜖 T’𝜖
F
Rule: 3
A 𝛼
b = follow(A)
M[A,b] = A 𝛼
NT First Follow
E { (,id } { $,) }
E’ { +, 𝜖 } { $,) }
T { (,id } { +,$,) }
T’ { *, 𝜖 } { +,$,) }
F { (,id } {*,+,$,)}
ETE’
E’+TE’ | ϵ
TFT’
T’*FT’ | ϵ
F(E) | id](https://image.slidesharecdn.com/6-practiceproblems-ll1parser-16-05-2023-230707153559-f6a8ac17/85/6-Practice-Problems-LL-1-parser-16-05-2023-pptx-17-320.jpg)
![Example-3: LL(1) parsing
Step 3: Construct predictive parsing table
F(E)
a=FIRST((E))={ ( }
M[F,(]=F(E)
NT Input Symbol
id + * ( ) $
E ETE’ ETE’
E’ E’+TE’ E’𝜖 E’𝜖
T TFT’ TFT’
T’ T’𝜖 T’*FT’ T’𝜖 T’𝜖
F F(E)
Rule: 2
A 𝛼
a = first(𝛼)
M[A,a] = A 𝛼
NT First Follow
E { (,id } { $,) }
E’ { +, 𝜖 } { $,) }
T { (,id } { +,$,) }
T’ { *, 𝜖 } { +,$,) }
F { (,id } {*,+,$,)}
ETE’
E’+TE’ | ϵ
TFT’
T’*FT’ | ϵ
F(E) | id](https://image.slidesharecdn.com/6-practiceproblems-ll1parser-16-05-2023-230707153559-f6a8ac17/85/6-Practice-Problems-LL-1-parser-16-05-2023-pptx-18-320.jpg)
![Example-3: LL(1) parsing
Step 3: Construct predictive parsing table
Fid
a=FIRST(id)={ id }
M[F,id]=Fid
NT Input Symbol
id + * ( ) $
E ETE’ ETE’
E’ E’+TE’ E’𝜖 E’𝜖
T TFT’ TFT’
T’ T’𝜖 T’*FT’ T’𝜖 T’𝜖
F Fid F(E)
Rule: 2
A 𝛼
a = first(𝛼)
M[A,a] = A 𝛼
NT First Follow
E { (,id } { $,) }
E’ { +, 𝜖 } { $,) }
T { (,id } { +,$,) }
T’ { *, 𝜖 } { +,$,) }
F { (,id } {*,+,$,)}
ETE’
E’+TE’ | ϵ
TFT’
T’*FT’ | ϵ
F(E) | id](https://image.slidesharecdn.com/6-practiceproblems-ll1parser-16-05-2023-230707153559-f6a8ac17/85/6-Practice-Problems-LL-1-parser-16-05-2023-pptx-19-320.jpg)















































![Cd2 [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/cd2autosaved-161231072301-thumbnail.jpg?width=640&height=640&fit=bounds)