
Download to read offline

















![Example
18
1
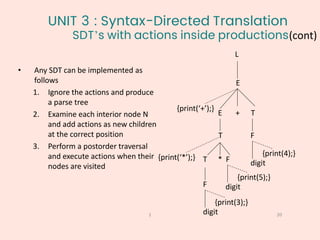
L -> E n {print(stack[top-1].val);
top=top-1;}
E -> E1 + T {stack[top-2].val=stack[top-2].val+stack.val;
top=top-2;}
E -> T
T -> T1 * F {stack[top-2].val=stack[top-2].val+stack.val;
top=top-2;}
T -> F
F -> (E) {stack[top-2].val=stack[top-1].val
top=top-2;}
F -> digit
UNIT 3 : Syntax-Directed Translation](https://image.slidesharecdn.com/cdpptunit-iii-210504105910/85/COMPILER-DESIGN-Syntax-Directed-Translation-18-320.jpg)





![UNIT 3 : Intermediate-Code Generation
Forms of three address instructions
28
1
• x = y op z
• x = op y
• x = y
• goto L
• if x goto L and ifFalse x goto L
• if x relop y goto L
• Procedure calls using:
– param x
– call p,n
– y = call p,n
• x = y[i] and x[i] = y
• x = &y and x = *y and *x =y](https://image.slidesharecdn.com/cdpptunit-iii-210504105910/85/COMPILER-DESIGN-Syntax-Directed-Translation-28-320.jpg)
![UNIT 3 : Intermediate-Code Generation
Example
29
1
• do i = i+1; while (a[i] < v);
L: t1 = i + 1
i = t1
t2 = i * 8
t3 = a[t2]
if t3 < v goto L
Symbolic labels
100: t1 = i + 1
101: i = t1
102: t2 = i * 8
103: t3 = a[t2]
104: if t3 < v goto 100
Position numbers](https://image.slidesharecdn.com/cdpptunit-iii-210504105910/85/COMPILER-DESIGN-Syntax-Directed-Translation-29-320.jpg)


![UNIT 3 : Intermediate-Code Generation
Type Expressions
32
1
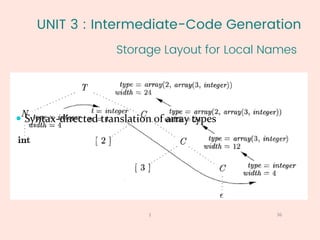
Example: int[2][3]
array(2,array(3,integer))
• A basic type is a type expression
• A type name is a type expression
• A type expression can be formed by applying the array type constructor
to a number and a type expression.
• A record is a data structure with named field
• A type expression can be formed by using the type constructor g for
function types
• If s and t are type expressions, then their Cartesian product s*t is a type
expression
• Type expressions may contain variables whose values are type
expressions](https://image.slidesharecdn.com/cdpptunit-iii-210504105910/85/COMPILER-DESIGN-Syntax-Directed-Translation-32-320.jpg)








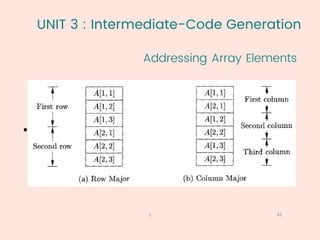



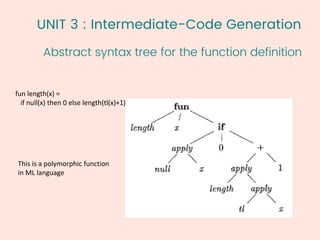













The document discusses compiler design, focusing on syntax-directed translation (SDT) and intermediate-code generation. It covers topics such as syntax-directed definitions, evaluation orders, intermediate representations, and three-address codes. Additionally, the document elaborates on semantic rules, types, attributes, and various implementation strategies related to SDT and intermediate code generation.























































































