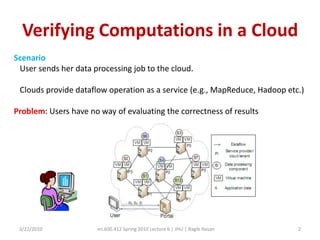
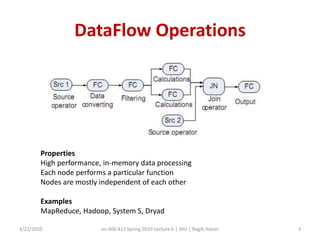
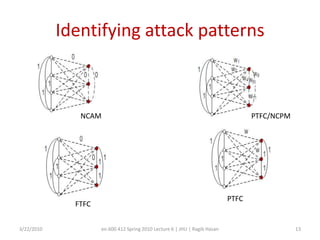
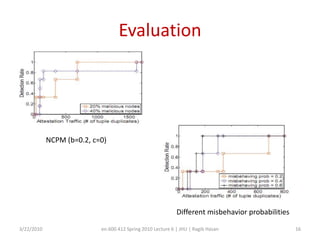
This document discusses verifying computations in cloud computing. It presents the RunTest approach, which randomly sends data along multiple processing paths and matches intermediate results to build an "attestation graph" showing node agreement. Nodes that are always inconsistent are identified as malicious. The Bron-Kerbosch algorithm finds the largest consistent clique to identify malicious nodes. The approach was evaluated on an IBM System S, detecting different attack patterns and assessing data quality. Issues discussed include the algorithm's complexity and scalability.