Download to read offline





![10
<event
name>
Traceability, explainability, transparency – EU regulations
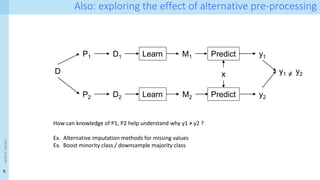
“Why was my mortgage application refused?” The bias problem originates in the data and its pre-processing!
Article 12 Record-keeping
1. High-risk AI systems shall be designed and developed with capabilities enabling the automatic recording of events
(‘logs’) while the high-risk AI systems is operating. Those logging capabilities shall conform to recognised standards or
common specifications.
Proposal for a Regulation laying down harmonised rules on artificial intelligence (Artificial Intelligence Act) - Brussels,
21.4.2021: https://ec.europa.eu/newsroom/dae/items/709090
“AI systems that create a high risk to the health and safety or fundamental rights of natural persons/ […] the
classification as high-risk does not only depend on the function performed by the AI system, but also on the specific
purpose and modalities for which that system is used.
- used for the purpose of assessing students
- recruitment or selection of natural persons
- evaluate the eligibility of natural persons for public assistance benefits and services
- evaluate the creditworthiness of natural persons or establish their credit score
- used by law enforcement authorities for making individual risk assessments](https://image.slidesharecdn.com/dp4ps-romatre-may-21-211016122047/85/Data-Provenance-for-Data-Science-10-320.jpg)




![23
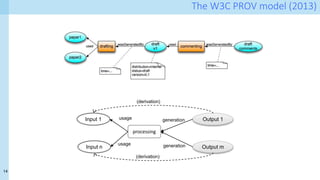
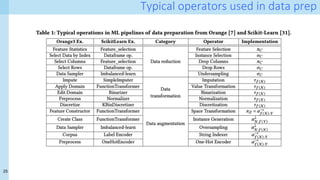
Data Provenance for Data Science: technical insight
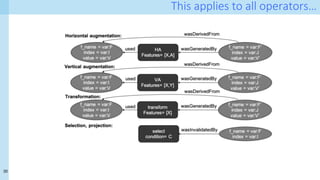
Technical approach [1]
- Formalisation of provenance patterns for pipeline operators
- Systematic collection of fine-grained provenance from (nearly) arbitrary pipelines
- Demonstration of provenance queries
- Performance analysis
- Collecting provenance incurs space and time overhead
- Performance of provenance queries
[1]. Capturing and Querying Fine-grained Provenance of Preprocessing Pipelines in Data Science. Chapman, A., Missier,
P., Simonelli, G., & Torlone, R. PVLDB, 14(4):507-520, January, 2021.](https://image.slidesharecdn.com/dp4ps-romatre-may-21-211016122047/85/Data-Provenance-for-Data-Science-18-320.jpg)
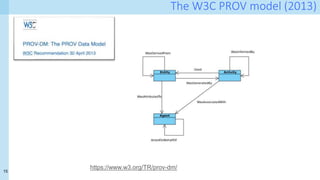
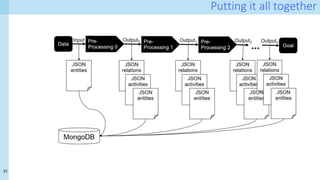
![24
Pre-processing operators
<event
name>
[1] Berti-Equille L. Learn2Clean: Optimizing the Sequence of Tasks for Web Data Preparation. In: The World Wide Web Conference on - WWW ’19. New York, New York, USA:
ACM Press; 2019. p. 2580–6.
[1]
[2] García S, Ramírez-Gallego S, Luengo J, Benítez JM, Herrera F. Big data preprocessing: methods and prospects. Big Data Anal. 2016 Dec 1;1(1):9.
[2]](https://image.slidesharecdn.com/dp4ps-romatre-may-21-211016122047/85/Data-Provenance-for-Data-Science-19-320.jpg)
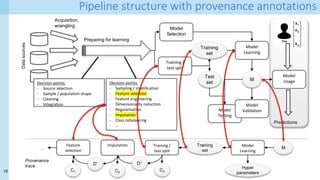
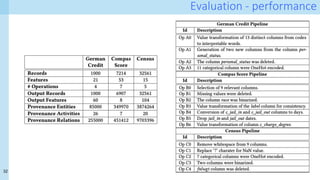
![27
Making your code provenance-aware
df = pd.DataFrame(…)
# Create a new provenance document
p = pr.Provenance(df, savepath)
# create provanance tracker
tracker=ProvenanceTracker.ProvenanceTracker(df, p)
# instance generation
tracker.df = tracker.df.append({'key2': 'K4'},
ignore_index=True)
# imputation
tracker.df = tracker.df.fillna('imputato')
# feature transformation of column D
tracker.df['D'] = tracker.df['D']*2
# Feature transformation of column key2
tracker.df['key2'] = tracker.df['key2']*2
Idea:
A python tracker object intercepts dataframe
operations
Operations that are channeled through the tracker
generate provenance fragments](https://image.slidesharecdn.com/dp4ps-romatre-may-21-211016122047/85/Data-Provenance-for-Data-Science-22-320.jpg)
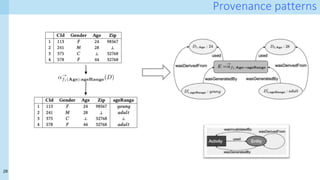
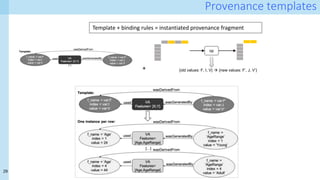
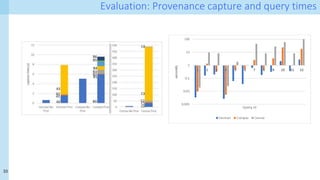




The document discusses data provenance for data science applications. It proposes automatically generating and storing metadata that describes how data flows through a machine learning pipeline. This provenance information could help address questions about model predictions, data processing decisions, and regulatory requirements for high-risk AI systems. Capturing provenance at a fine-grained level incurs overhead but enables detailed queries. The approach was evaluated on performance and scalability. Provenance may help with transparency, explainability and oversight as required by new regulations.
































































