Download as PDF, PPTX




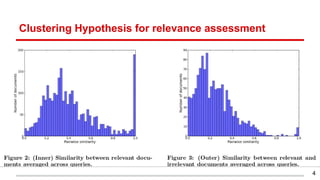

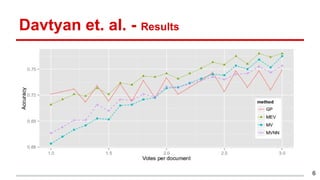














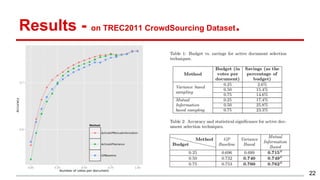
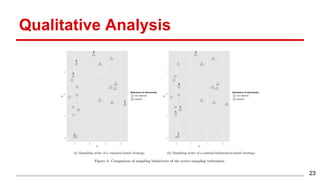


This document discusses methods for active content-based task selection in crowdsourcing, focusing on optimizing relevance assessments under budget constraints using information-theoretic approaches. It presents algorithms for variance-based and mutual information-based sampling to improve the efficiency and quality of relevance votes, demonstrating significant budget savings. Experiments conducted on the TREC crowdsourcing dataset illustrate the proposed methods' effectiveness and efficiency, leading to potential applications in other fields.













































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)
















