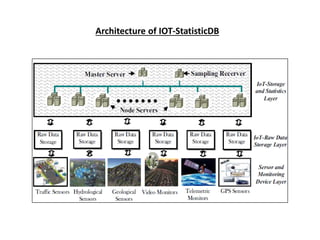
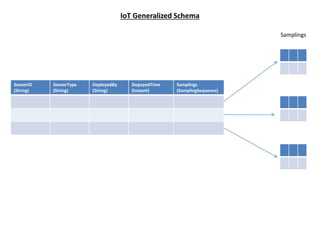
This document discusses big data mining and the Internet of Things. It first presents challenges with big data mining including modeling big data characteristics, identifying key challenges, and issues with statistical analysis of IoT data. It then describes an architecture called IOT-StatisticDB that provides a generalized schema for storing sensor data from IoT devices and a distributed system for parallel computing and statistical analysis of IoT big data. The system includes query operators for data retrieval and statistical analysis of IoT data in areas like transportation networks.































![Network-based Parameter Aggregation
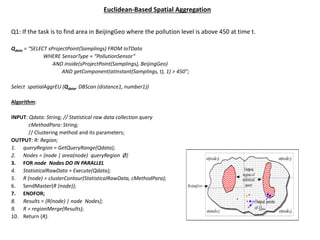
Q4: If task is to find the traffic flow parameters at time t for each edge in BeijingGeo.
Qdata= “SELECT sTruncateTime(sTruncateGeo (Samplings, BeijingGeo), [ t - 5*Minute, t ])
FROM IoTData
WHERE SensorType = “VehicleGPS””
Select parameterAggrNet (Qdata, TrajectoryAnalysis);
Algorithm:
INPUT: Qdata:String; //Raw data collection query
method: String; //aggregation method
OUTPUT: R; //of the form Set((edgeID:string, para: string))
1. queryRegion = GetQueryRange(Qdata);
2. Nodes = {node | area(node) queryRegion Ø}
3. FOR node Nodes DO IN PARALLEL
4. StatisticalRawData = Execute(Qdata);
5. R (node) = trafficAnalysis(StatisticalRawData, method);
6. SendMaster(R (node));
7. ENDFOR;
8. Results = {R(node) | node Nodes};
9. R = edgeBasedValueMerge(Results);
10. Return (R).](https://image.slidesharecdn.com/94aa7e36-a999-47a0-abd9-f0cd37ddd76d-160725195029/85/Big-Data-and-IOT-38-320.jpg)





































































