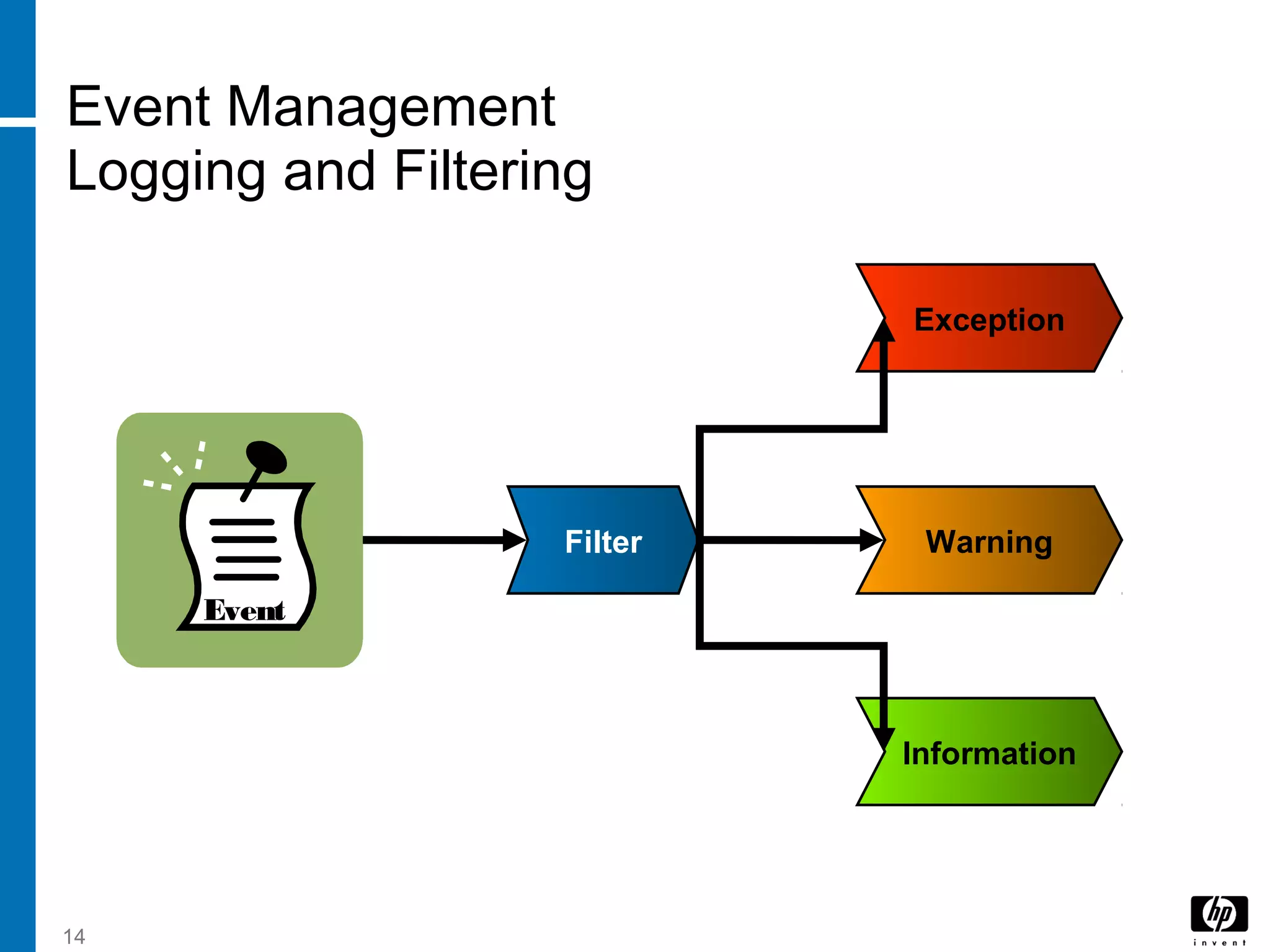
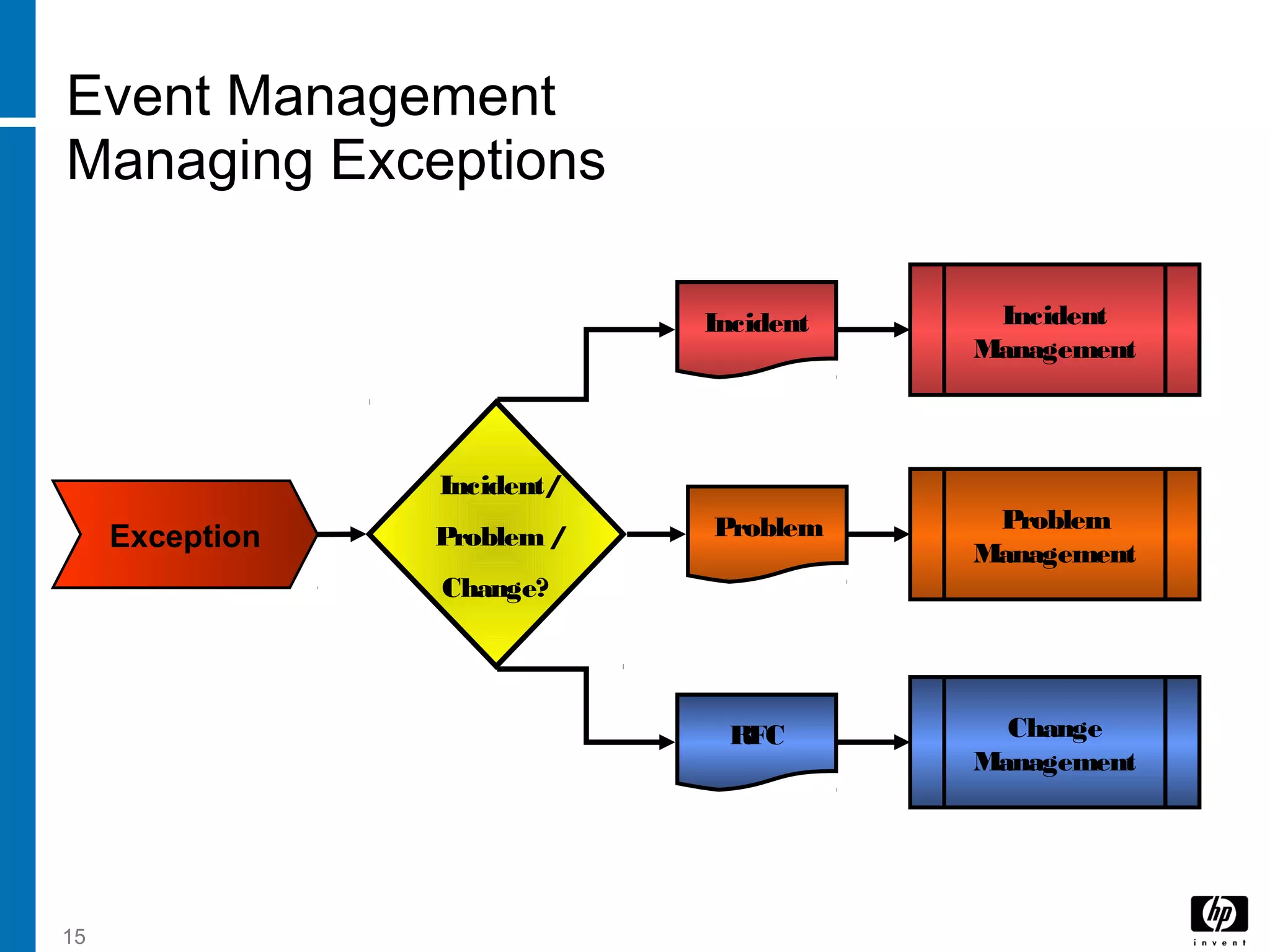
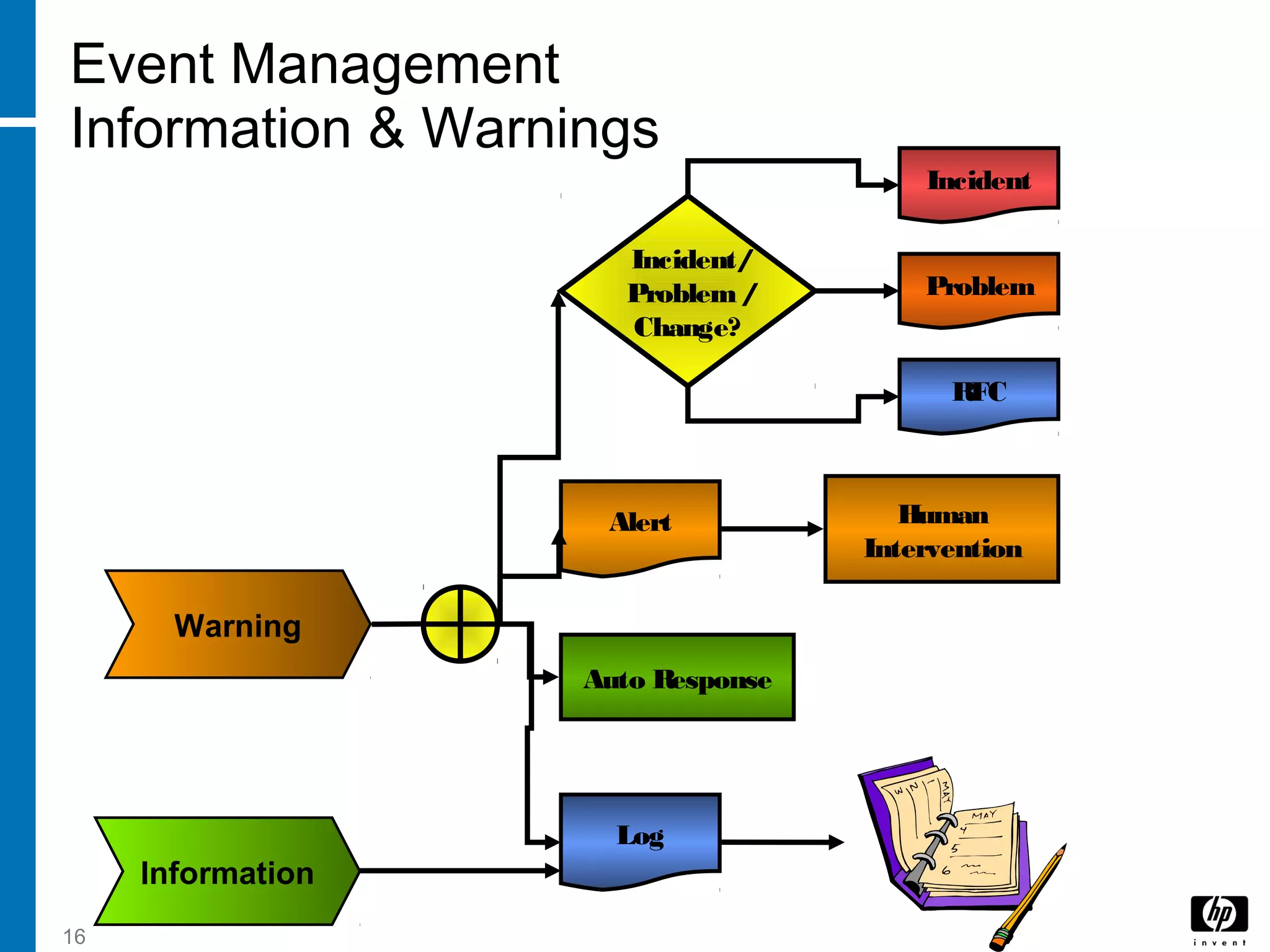
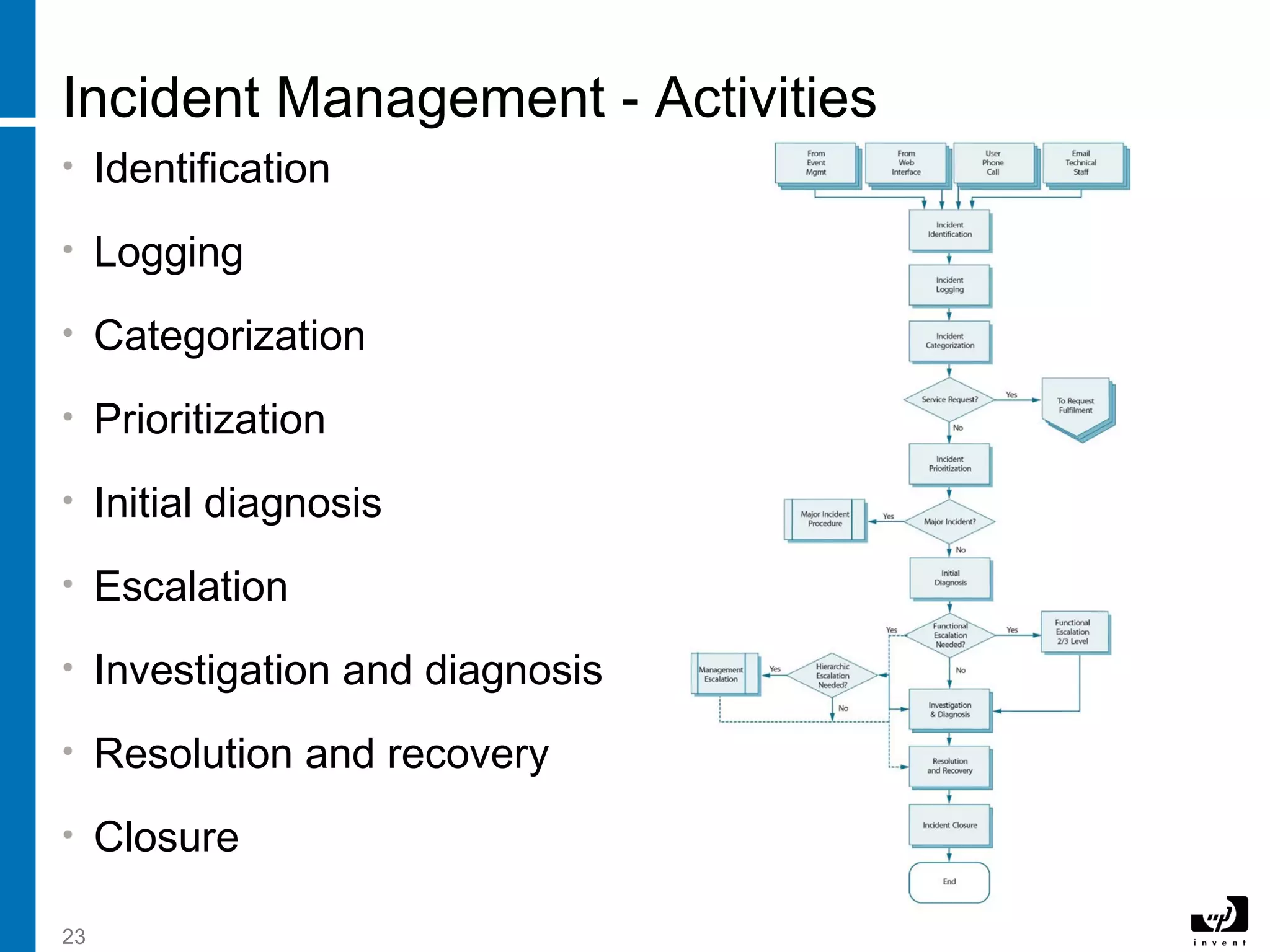
The document discusses service operation processes including event management, incident management, request fulfillment, and access management. It describes event management as monitoring all events through the IT infrastructure to allow normal operation and detect exceptions. Incident management focuses on restoring service as quickly as possible to minimize business impact. Access management grants authorized users access to services while restricting unauthorized users.





















































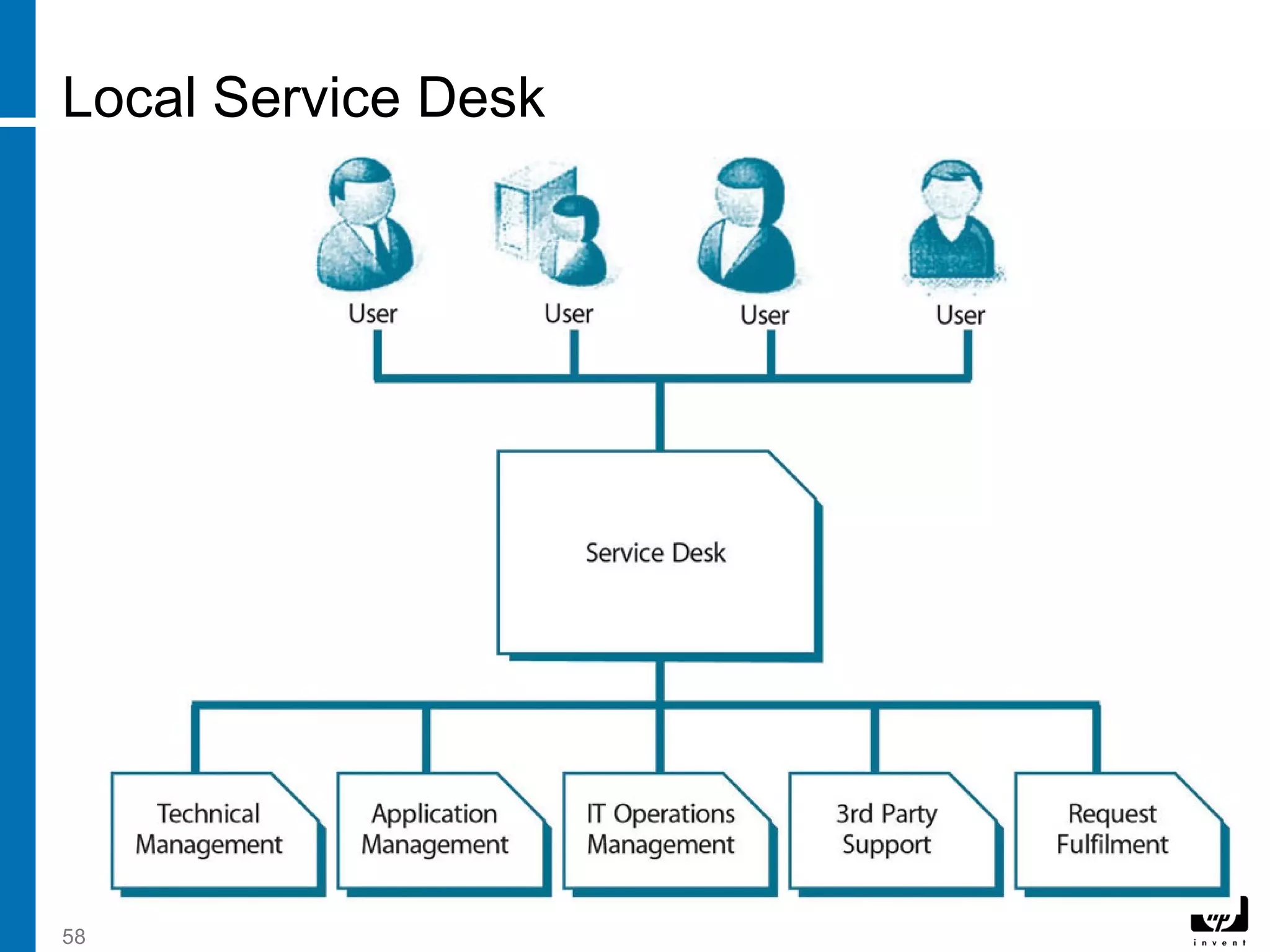
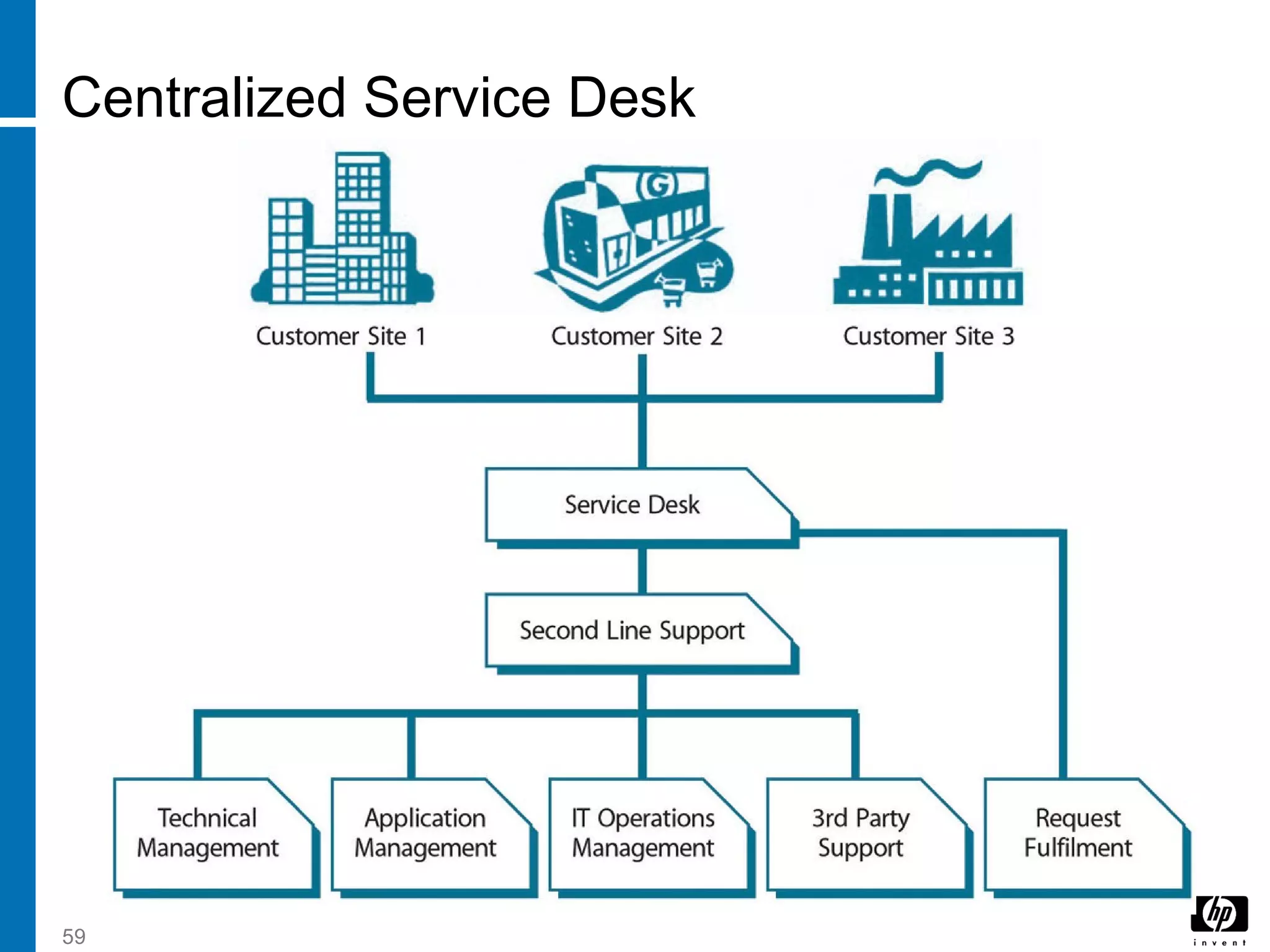
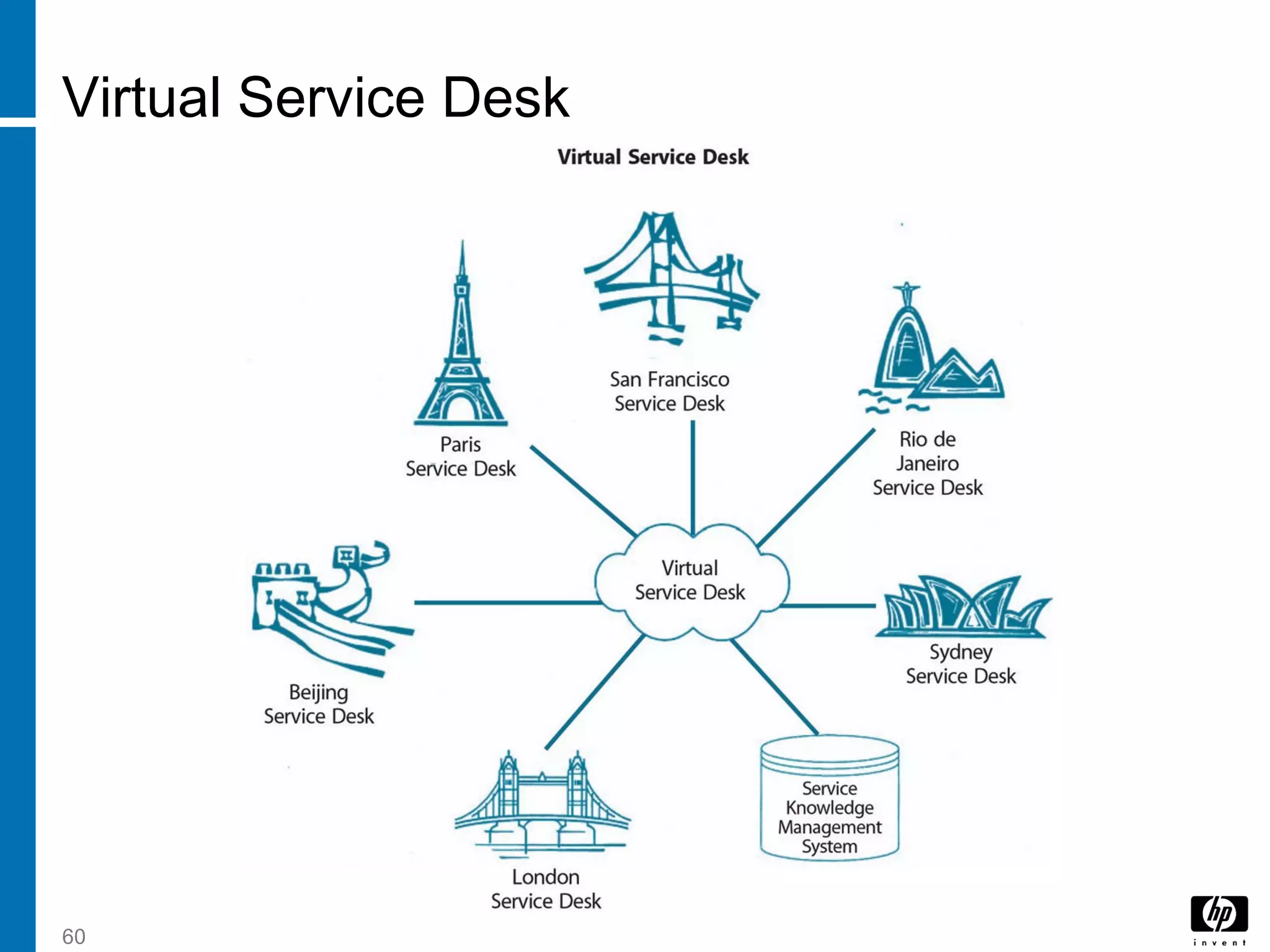













































































![1 introduction to itil v[1].3](https://cdn.slidesharecdn.com/ss_thumbnails/1introductiontoitilv1-130822004610-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















