Downloaded 221 times



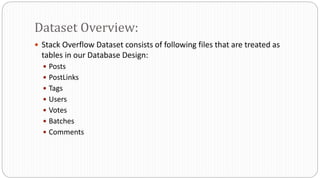
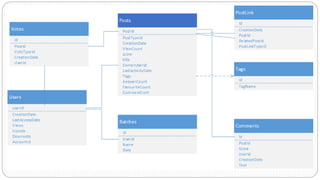

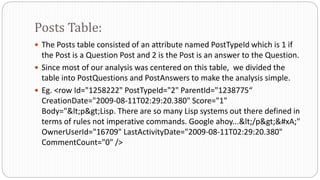










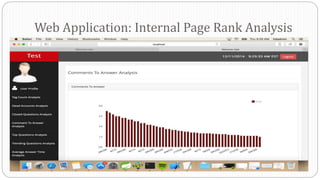







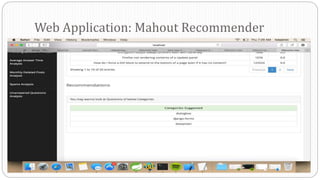

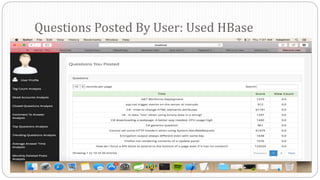
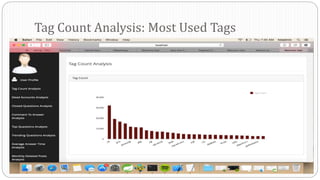
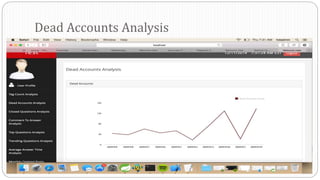
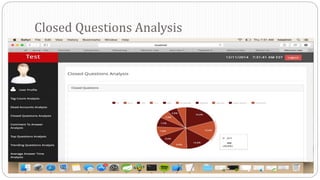
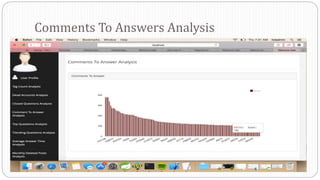
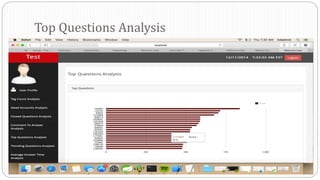
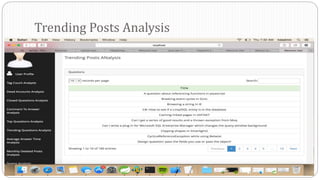
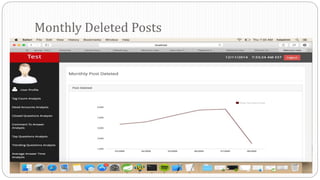
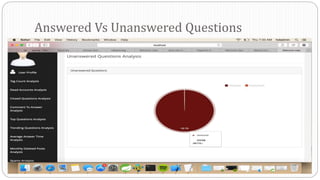
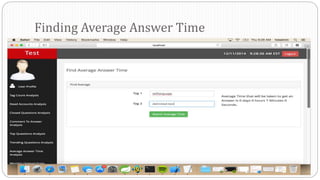
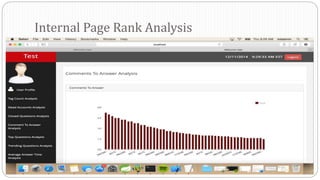


The document describes a Big Data project analyzing the Stack Overflow dataset. Key points: - The dataset was obtained from Stack Exchange and consists of XML files totaling around 20GB that were parsed and loaded into HDFS. - The data was analyzed to identify trending questions, unanswered questions, closed questions, dead questions, top tags, and more. PageRank analysis was also performed to rank posts. - The results were visualized in a web application using technologies like Hive, HBase, Pig, and Mahout recommendation. Performance issues were encountered during the MapReduce parsing of the large XML files.



































































