Downloaded 77 times







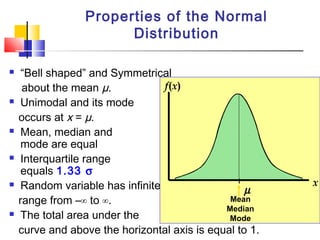
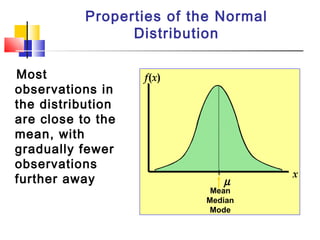
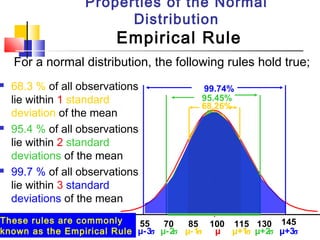

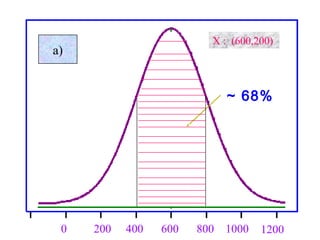
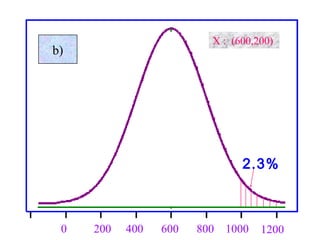
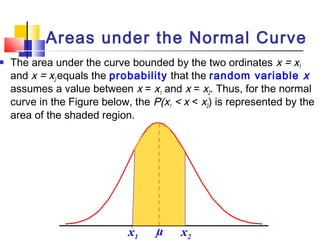
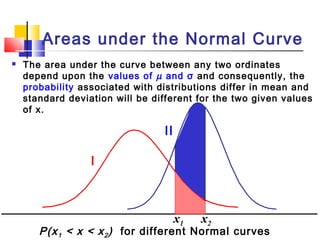


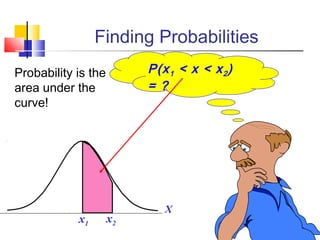

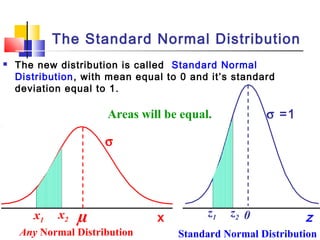




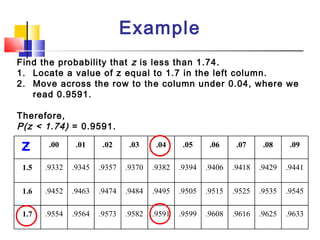


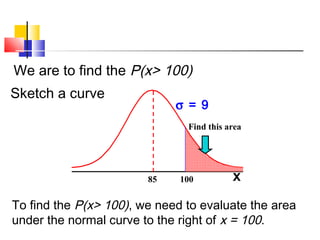

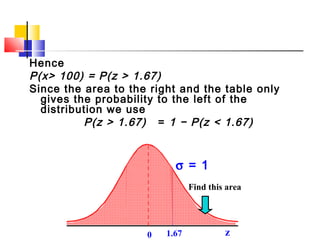
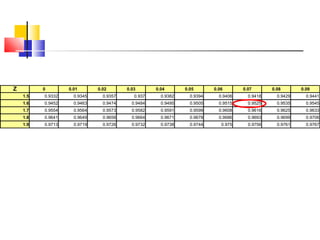
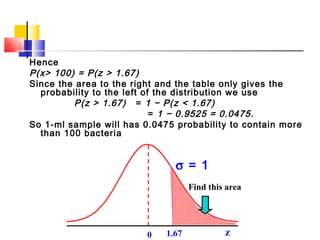


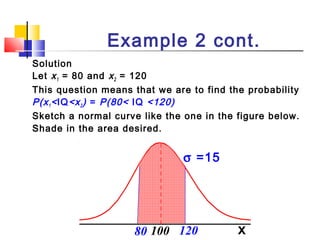

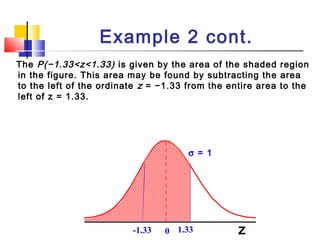
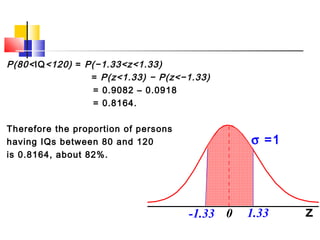
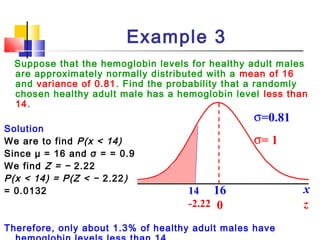





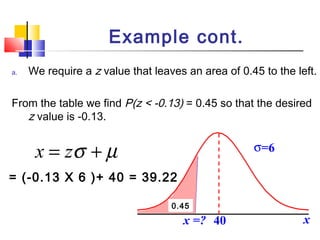
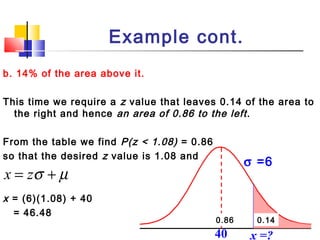









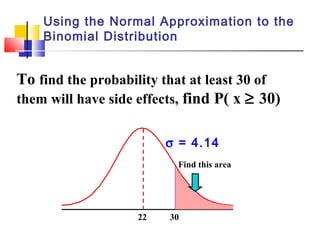
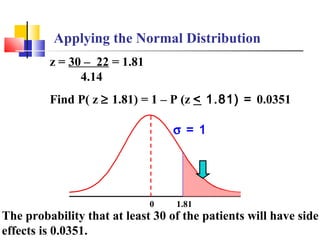

Here are the steps to solve this problem: a) Find the z-score corresponding to 115 mm Hg: (115 - 85)/13 = 2.31 The proportion that is NOT severely hypertensive is 1 - P(Z >= 2.31) = 1 - 0.0103 = 0.9897 b) Find the z-score corresponding to 90 mm Hg: (90 - 85)/13 = 0.3846 The proportion that will be asked to consult a physician is P(Z >= 0.3846) = 0.6507 c) Find the z-scores corresponding to the mildly hypertensive range: (90 - 85)/13 = 0.3846 (







































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)


![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)




